
Software Application Layers And Responsibilities, 2019 Edition
The other day, Joshua Caito tweeted about how he still loves writing ColdFusion code. And the truth is, so do I. ColdFusion is not perfect; but, it does a lot of stuff right. And its flexibility has made creating large, robust applications a thing of pleasure. With my recent switch to Lucee (at work), that pleasure has only increased. The reality is, my biggest blocker in ColdFusion application development is simply my own limited understanding of Application Architecture.
At this point in my career, I've more-or-less given up on the idea of learning "Object Oriented Programming" (OOP). For that to happen, I believe I would have to go apprentice at company where OOP was the de facto standard. But, until that happens, I've let go of that dream and embraced the reality of a more "Transaction Script" oriented paradigm.
But, even this approach is not so easy. In 2012, I had a conversation about MVC (Model-View-Controller) with Steven Neiland. And, in the 7-years since that conversation, my confidence in application architecture has moved with lava-like speed. Now, in 2019, I am feeling better about my architectural choices; but, it's still very much trial-and-error followed by refactoring.
Looking back on my own blog, I can clearly see the Sisyphean journey:
- 2012 - A Better Understanding Of MVC Thanks To Steven Neiland.
- 2012 - More Thinking About MVC And Application Architecture.
- 2012 - Software Application Layers And Responsibilities.
- 2013 - Exploring Sample Software Application Layers And Responsibilities.
- 2013 - What If All User Interface (UI) Data Came In Reports?.
- 2016 - How Deeply Should Feature Flags Be Embedded In Your Application?.
- 2017 - Exceptions Are For Programmers, Error Responses Are For Users.
- 2017 - Considering When To Throw Errors, Why To Chain Them, And How To Report Them To Users.
- 2017 - Reflecting On Data Persistence, Transactions, And Leaky Abstractions.
- 2017 - Considering Uniqueness Constraints And Database Abstractions In Application Business Logic.
- 2017 - Why Message-Queues Don't Carry The Stigma Of An Integration Database.
- 2017 - Considering Strategies For Idempotency Without Distributed Locking With Ben Darfler.
- 2018 - Each Feature Flag Should Be Owned By A Single Deployment Boundary.
- 2018 - The Not-So-Dark Art Of Designing Database Indexes: Reflections From An Average Software Engineer.
- 2019 - Lessons I Wish I Had Learned Much Earlier In My Web Development Career.
Having an actual recording of all of this deliberation is a double-edge sword. On the one hand, it's great to see how some of my thoughts are beginning to coalesce and sharpen over time. But, on the other hand, it's infuriating that it's taking so long! I've put in my 10,000 hours of "deliberate practice"; and, I very much feel like my understanding of application architecture should be richer and much more robust at this point in my life.
That said, in the spirit of Joshua Caito's tweet, I thought I would share my current understand of software application layers and responsibilities in a ColdFusion application as they stand on June 6th, 2019.
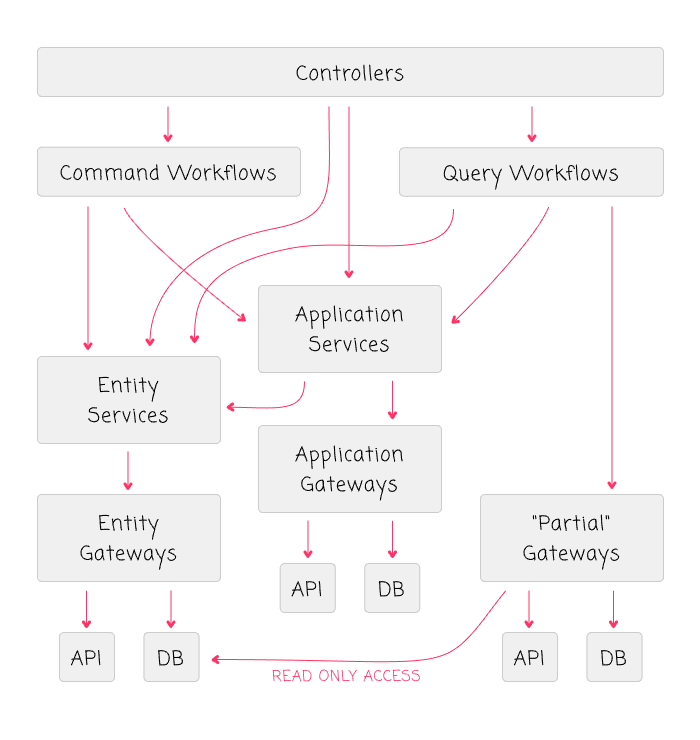
ASIDE: Since I don't get to work on many "green field" applications, some of this is based on experience and some of this is based on theory that has been formed by past pressures and frictions.
The first thing that we can see here is that the relationship of components flows in a unidirectional way. I do not believe in circular dependencies for these high-level concepts. If two components depend on each other, I believe that this represents a lack of orchestration at a higher level in the dependency graph.
NOTE: This is unrelated to the concept of circular references in a "data structure". This conversation is limited in scope to application layering.
The second thing that we can see here is that each "Gateway" is owned and accessed entirely by the "Service" above it. This allows for strong assertions at the data-layer and demands loose transactional coupling between entities.
ASIDE: The one exception to this is the "partial gateway", which is granted read-only access to the database tables that are "owned" by other gateways. This allows for light-weight CQRS (Command-Query Responsibility Segregation) without having to maintain a separate, materialized database.
With that said, let's look at the responsibilities of each application layer.
Controllers
The Controller Layer, as "Uncle Bob" Martin would put it, is the "delivery mechanism". This is the layer of the application that interfaces with the user and manages the request / response life-cycle. It has, by far, the most leniency in what it can access because it has the broadest set of responsibilities.
The Controller layer is responsible for:
Bootstrapping the application. In a ColdFusion application, I would include the
Application.cfccomponent - the ColdFusion application framework - in the Controller abstraction as it takes care of bringing the rest of the components to life. This includes configuring the application as well as instantiating any dependency-injection (DI) frameworks. By definition, this requires reaching down into all layers of the application.Session management. The Controller layer is the only layer that is "session aware". As a request comes into the application, it is up to the Controller to associate the request with any new or existing sessions. It may do this by consuming lower-level "Application Service" and "Entity Service" components; but, those lower-level components never act on the session independently.
This includes altering the session based on user-actions. For example, it is a security best-practice to rotate a session once an Email address or a Password is changed. The Controller layer would perform this rotation as part of the response-handling on the relevant requests.
High-level security. Relating to session management, the Controller layer is responsible for high-level authentication and authorization of the request. This does not include things like low-level authorization around business logic; this pertains to general route-based authentication (such as ensuring that a request to a given route has been authenticated).
The Controller is also responsible for pulling Authentication headers - such as OAuth bearer tokens and Basic Authentication tokens - out of the HTTP request and consuming those during request handling.
High-level rate-limiting. While lower-level components may have rate-limits around certain actions (based on business logic), the Controller layer can apply rate-limiting in a broader sense, across all requests. In order to do this, it may reach down into the "Application Services" and "Entity Services" components.
ASIDE: Rate-limiting may also be applied in an upstream layer called the "Web Application Firewall" (WAF). In that regard, I wonder if the WAF should be considered part of the "Controller".
IP white-listing. Very much like rate-limiting, the Controller - or the Web Application Firewall (WAF) - may implement some high-level IP-based white-listing (meaning, it locks down access to certain routes based on a restricted set of IP-addresses). In order to do this, the Controller may reach down into both the "Application Service" and "Entity Service" components.
Routing requests. The Controller layer understands that the web application is an HTTP-based application. And, it is responsible for routing HTTP requests through to the appropriate Command and Query workflow components. In other words, the Controller layer is responsible for translating "web requests" into "application core" requests.
Part of this "request translation" should attempt to abstract-away the concept of the HTTP-request. However, in a web-based application, this is not going to be a clean abstraction. For example, you may need to pass things like IP-Address, User-Agent, and Request-ID through to the lower-levels of the application. I theorize that this can be done with a consistently-shaped object, like
RequestMetadata; however, I have never actually tried this.Response handling. Once an HTTP request is routed to the application core and a response payload has been provided, the Controller must translate the response into the appropriate HTTP Status Code. It must also serialize the response payload and provide it to the client in a format that they can consume (such as HTML, JSON, CSV, binary, or XML). In order to do this, the Controller may reach down into the "Application Services" layer.
Error handling and logging. The application "core" is going to throw both expected and unexpected errors. The Controller layer must catch those errors and log them, providing additional context about the request (see
RequestMetadataabove). As much as possible, the Controller layer should present the user with a graceful error page, ensuring that no low-level error details are accidentally leaked to the outside world. To do this, the Controller may reach down into the "Application Services" layer.Feature flags. When a request comes in and is associated with a Session, the Controller layer can then identify all of the feature flags that the request has access to. These feature flags can then be made available to the rest of the request handling through something like the
RequestMetadata(see above). In order to do this, the Controller may reach down into the "Application Services" layer.ASIDE: In my "brown field" applications, feature flags tend to be calculated at all levels of the application. However, in theory, I would love to see those calculations be made high-up in the request flow where we have the most contextual information about the request available. For me, that's the Controller layer.
Despite all of these responsibilities, the Controller layer should, itself, be rather "thin". While it contains a lot of request-handling logic, a large portion of the implementation details should be deferred to lower-level components. This is why the Controller layer has to be able to reach down into lower-level layers of the application as part of its responsibility.
Application Services
The Application Services layer is the "utility" layer. It implements all of the logic that is somewhat "meta" to the core value-proposition of the business. Things like rate-limiting, password hashing, parsing, serialization, email delivery, server-sent events / WebSocket events, security, and error logging, to name a few.
Though, to be honest, the boundaries of this layer are still a bit fuzzy in my mind. For example, imagine a request comes into an application to "delete a document" and I wanted to be able check with a centralized permissions service as to whether or not this can be done. I might call something like the following in my "Command Workflow" component:
securityService.canDeleteDocument( userID, documentID )
In this case, I would consider SecurityService to be an "Application Service", despite the fact that it clearly contains some core business logic. And, to implement this business logic, it would likely turn around and consume lower-level "Entity Services". All to say that my classification of this layer as "meta" to the core value-proposition is, at the very least, not terribly consistent.
Taking this concept one step farther, I would say that this layer also contains cross-entity / coordination business logic that I simply want to extract and reuse. But, in that sense, the concept of the "Application Services" layer as a "utility" layer is still somewhat consistent.
Clearly, there's still some codification of this that layer needs to take place.
Application Gateways
The Application Gateway layer just enables data access for the Application Services layer. For example, a "Rate Limit Service" (Application Service) may use some sort of "Redis Client" (Application Gateway) under the hood in order to persist rate-limiting data.
Command Workflows
The Command Workflow layer implements requests to change the application state. For example, creating a document, deleting a comment, changing an email address, and accepting an invitation would all be examples of actions handled within this layer. I like to think of the Command Workflow layer as the "orchestration layer" because it applies business logic and security constraints across entities.
In my mind, the Command Workflow layer is akin to what Uncle Bob Martin would call the "Use Cases". The Command Workflow layer - like the "Use Cases" - describe what the application can "do". It's responsibilities include:
Low-level security. While the Controller layer handles high-level security, like ensuring that incoming requests are authenticated, it is the Command Workflow layer that authorizes the requesting user for the requested action. For example, in order to "send a team invitation", the Command Workflow layer would ensure that the requesting user is an "admin on the team". To do this, it can reach down into the "Application Service" and "Entity Service" layers.
Low-level rate-limiting. While the Controller layer (including the WAF) handles high-level rate-limiting and DDOS (Distributed Denial of Service) attacks, it is the Command Workflow layer that handles rate-limiting on a use-case basis. For example, in order to prevent spamming, the Command Workflow layer may only allow 10 new "team invitations" to be sent in an hour. Furthermore, this limit may be different based on a user's subscription level or other mitigating factor. In order to do this, it can reach down into the "Application Service" and "Entity Service" layers.
Event broadcasting. When an action is performed on the application, it is likely that other people and systems need to know about it. The Command Workflow layer is responsible for broadcasting the relevant events for a given action. This may include sending WebSocket events to the browser. Or, it may include sending an Email notification to the members of a team. Or, it may include pushing "Domain Events" onto a message bus that other components are monitoring. In order to do this, it can reach down into the "Application Service" layer.
Cross-entity coordination. When a command is sent to the application, it may affect multiple entities. For example, when accepting a "Team invitation", it likely that both the "Team Invitation" and the "Team Membership" entities will be involved. And, there may also be something like an "Audit Trail" mixed-in as well. The Command Workflow layer coordinates these changes across the entities such that each entity can operate independently of the others. To do this, the Command Workflow layer will clearly be reaching down into the "Entity Service" layer.
To be clear, I am talking about cross-entity business logic. The Command Workflow layer has to understand how an action affects different entities; and then, it must propagate those changes down to those Entity Service.
Facilitating idempotency. Due to the "orchestration" nature of the Command Workflow layer, this layer should be authored with an eye towards idempotency. That is, it should be written in such a way that - as much as possible - a command is safe to retry. This way, if any part of the orchestration fails - such as due to a database lock or an HTTP timeout - the user can retry the command with a reasonable hope of fulfilling their request.
In the same vein, the Command Workflow layer is not the place for Transaction management. While the Command Workflow layer does consume the "Entity Service" layer, the Command Workflow layer should be unaware of the lower-level data persistence details. In other words, the Command Workflow layer can't use Transactions because it shouldn't know it's even using databases.
I've read a little bit about the concept of a "Unit of Work". This is kind of like a "Transaction abstraction" where you can roll-back non-database actions. It sounds really complicated. For my level of experience, I'd rather just make things "retriable" (as much as possible) rather than trying to figure out how to "roll them back."
Locking and synchronization. As much as possible, I am trying to use Idempotent workflows instead of locking (including distributed locks). But, in cases where locking and synchronization of a particular "action" makes sense, I think this should go in the Command Workflow layer. After all, it's this layer that implements the cross-entity orchestration and is, therefore, the most likely to understand the needs of locking.
Facilitating loosely-coupled entities. This is more a byproduct of the entity orchestration, but I wanted to call it out explicitly because it can act as a litmus test. By facilitating cross-entity logic, the Command Workflow layer allows each "Entity Service" to remain decoupled from every other Entity Service. This means that if you end up with an Entity Service that depends on another Entity Service (ex, a "Team Membership" service needing the "User Service"), it is a "code smell" that logic in the lower-level Entity Service layer should be moved up into the Command Workflow layer.
The Command Workflow layer is really the layer that defines the "application". It's where the bulk of the business logic lives. The lower-level layers deal with things like data integrity; but, it's this Command Workflow layer that turns that data into a cohesive set of business features.
Query Workflows
Whereas the Command Workflow layer defines what the application can "do", the Query Workflow layer defines what the application can "present". The Query Workflow layer is the layer that gathers data for the user. It is geared towards performance. It may use a combination of databases, including caches and read-replicas, where it can make calculated decisions with regard to staleness, consistency, user experience, and duplication of logic.
While it is a sibling of the Command Workflow layer, the responsibilities of the Query Workflow layer are far more limited in scope:
Low-level security. While the Controller layer handles high-level security like basic authentication, the Query Workflow layer implements low-level security around data access. For example, if a user wants to see a list of "Team Members", the Query Workflow layer must ensure that the requesting user is a member of the given team. To do this, it can reach down into the "Application Service" and "Entity Service" layers.
Cross-entity coordination. While the Command Workflow layer has to understand how different entities are affected by an action, the Query Workflow layer has to understand how different entities relate to data gathering. For example, if a user requests a list of "Team Members", the Query Workflow layer has to understand that this should only include a list of team members that have active team memberships.
At first, it can feel like the Query Workflow layer has a lot of logic duplication. However, this in an inaccurate understanding of "duplication." Since every "View" within an application has different constraints, the Query Workflow layer has to have a lot of logic that enables those different constraints. And, do so in such a way that each "View" can change independently without corrupting the data returned to another View.
ASIDE: One of the most valuable lessons that I've learned in my career is to write code that is "easy to delete". For me, this applies heavily to the Query Workflow layer. Aspects of this layer should be extremely easy to delete. If they are not, it is likely that your Query Workflow methods are being references inappropriately by the Controller layer.
I like to think of my Query Workflow layer as being a collection of mini BFFs (Backend For Front-End). Each "View" within the application will have a Query Workflow method; and, when a View is no longer needed, the corresponding Query Workflow method should be deleted as well.
Performance trade-offs. The Query Workflow layer is intended to be fast. It should deliver data to the user as fast as it can, with the best experience that it can. This means that it has to have an intimate understanding of the lower-level data as well as an intimate understand of how the data is going to being consumed by the user. It has to understand if "stale data" from a lagging read-replica is acceptable; or, if the data has to be immediately consistent. It then uses all of this logic when trying to figure out which lower-level Gateways to access.
Whereas the Command Workflow layer "defines the application", the Query Workflow layer defines the application "experience."
Partial Gateways
The Partial Gateways layer gathers the data for the Query Workflow layer. Each Partial Gateway is owned exclusively by a single Query Workflow feature. When a Query Workflow feature is deleted, it should be safe to delete the corresponding Partial Gateway.
The Partial Gateway layer may be granted read-only access to database tables that are technically owned by other Entity Gateways. This facilitates a sort of poor man's CQRS without needing a full-on "materialized view" of the data.
ASIDE: People often conflate the idea of "Command-Query Segregation" with the idea of "Event Sourcing". While these two ideas often go together, they are not the same thing. At its most base level, CQRS just means that the methods used to query data shouldn't be the same methods used to mutate data. This creates flexibility. At the Partial Gateway layer, I am implementing CQRS by separating my "read / reporting queries" from my "entity queries", even though they are often going to the same database tables.
Entity Services
The Entity Service layer provides data consistency around an isolated business concept. In my mind, the Entity Service is akin to the "Aggregate Root" in Domain Driven Design (DDD). All changes to entity data must be accomplished through a call to the relevant Entity Service.
The constraints implemented within an Entity Service should apply only to the data owned by the Entity Service; and, should not apply to relationships across entities. All cross-entity constraints must be applied at a higher layer in the application. For example, if a "Subscription level" implies a limit to the number of "Team Memberships" that can be created, the Team Membership Service should not have any understanding of this (that is, of Subscriptions). The application of such Subscription-based constraints must be applied in the Command Workflow layer.
ASIDE: This separation of concerns can get a little fuzzy when you consider the use of database indexes and idempotent workflows. For example, you could argue that "email uniqueness" is a constraint at the Command Workflow layer, not the "account" entity service layer (depending on how you squint). However, in order to help facilitate data integrity and idempotency, it would make sense to add a Unique Index to the "account" database table for emails. Doing so, is great from a business rules standpoint; but, begins to blur the separation of concerns. To be clear, I am very OK with this; especially when the Command Workflow layer also performs an explicit check for duplication, using the database index as the "fail safe" mechanism in lieu of locking.
An Entity Service should not depend on any other Entity Service. Just as with the "Aggregate Root" in DDD, references to other entity types should be accomplished through foreign-key references only - not objects. Any loading of foreign-key-related entities should be done at a higher layer of the application, such as the Command Workflow layer.
The Entity Service layer should not deal with Transactions. Since it depends on a Gateway abstraction for data persistence, it's very possible that there is no database under the hood. As such, it should favor idempotent strategies and defer to the Gateway layer for Transactions.
Entity Gateways
The Entity Gateway layer implements the data persistence logic for the Entity Service layer. Each Entity Gateway is owned by exactly one Entity Service.
Since the Entity Gateway is the only layer that knows whether or not a database exists, this is the layer that can rightfully implement Transactions. And, to this point, if an Entity Service needs to affect multiple tables at the same time, it should do this with a single Entity Gateway method which can wrap a Transaction around the underlying query / queries.
The Entity Gateways should only deal with consistent data-sources (ie, they should only read and write to the master database). If you need to use a read-replica within an Entity Gateway, you are probably conflating "Entity Gateway" and "Partial Gateway" (see above).
None of this is perfect, some of it is theory.
A lot of the thoughts and opinions here are based on the work that I do within a large monolith. Some of these rules are based on things that I have tried and liked; but, some of these rules are based on things that I wish I had tried. As such, not all of this is grounded in hands-on experience.
There's also a lot of cross-cutting stuff that I don't have strong feelings about. Features like StatsD metrics, Analytics tracking, and Logging don't necessarily fit into nice and neat box. Not from a theory stand-point; and, certainly not from a pragmatic "getting stuff done" stand-point.
That said, this is the current mental model that I have for Application Architecture in 2019. When looking back to the same exercise that I did in 2013, I can see a lot of similarities; but, I can also see that I now have a lot more thinking behind - and confidence in - some of my choices. I can also see that some choices, like where I manage Transactions, have changed dramatically.
As far as I have come, I still feel like I have so much more to go. Especially if I ever want to revive the dream of learning Object Oriented Programming (OOP). But, all I can do is take it a day at a time and do my best to think deeply about how and why I am architecting my applications.
Hopefully, I get a little better at this every day.
Monolith vs. Microservices
While the overwhelming majority of my experience is in the monolith world, I don't believe that anything I have discussed here actually changes in a microservices landscape - it just happens on a different scale. Where as a monolith may have a very broad Command and Query model, a microservice would have a much more narrowly-scoped model. But, the mechanics should be very similar (at least, in my brain).
Who consumes message queues?
One area that I really wish I had more experience with was message queues. But, that will come naturally when I start to get more involved with microservices at work. That said, I've been thinking about where I would classify message queue consumers in my application layering.
At this time - which, again, is almost entirely theory - I would classify message queue consumers as part of the "Controller" layer. The Controller layer is the "delivery mechanism". And, the message queues seem to be how the events are getting "delivered" to the application boundary. As such, I would think that the Controller layer would start consuming messages and, in turn, passing them off to the Command Workflow layer for fulfillment. It would then consume the Command Workflow responses, possibly, in turn, pushing new events onto another message queue.
In this sense, the incoming and outgoing message queues are akin to the incoming and outgoing HTTP request and response, respectively. And, by separating out the delivery mechanism (ie, message queues), it keeps the "application core" devoid of having to know anything about message queues.

Reader Comments
Ben, this was a great write up.
Our company has been developing in ColdFusion since 2001 and around 2005 we challenged a company moving away from ColdFusion into .NET with the claims that .NET was more n-tiered based and scalable.
Really though, when you consider nTier, all you need to do is consider a layout such as you've provided. I want to say around 2007, we began converting every project into a separation of layers that has evolved.
I tried to put your diagram and place it with a practical example of a few controllers talking to a ColdFusion application. I have questions and comments.
In my imaginary example we have 3 controllers, A ColdFusion website, an APP and a Third-Party developer given the opportunity to talk to the application in their preferred language. My questions and comments are mostly related to the diagram and the placement of the query workflows. While I find most of the flow correct, I tried to imagine a controller talking to query workflow process prior to application services and couldn't find or imagine it viable. For instance, in a ColdFusion website, your CF application will have to talk to the application.cfc and it does this prior to command workflows and independent of query workflows. In fact - I couldn't conceptualize the controller touching the query workflow prior to application services. For example…
So basically - in this concept - it doesn't matter what the controller is - unless it is a CF Site - because it will read the application cfc. Other controller will build command workflows that don't really take effect until they begin to talk to the app but enter via the application services. Wouldn't you want all workflows to enter through application services for security - then process queries and have query workflows shell out to the different services / gateways?
http://www.goliathdevelopment.com/download/applicationflow.jpg
Can you give me some input based on the diagram and perhaps my lack of understanding of your application flow concept? For instance - I see a controller going to Entity Services or even the query workflow prior to touching application services. Thanks!
@Angel,
You are absolutely right; and, I believe this is a short-coming of my diagram. I really focused on general dependencies, but didn't really articulate any of the order-of-operations. In reality, I would be doing exactly what you are saying, at least I think so.
Everything has to come in via the
Application.cfcas that's the top-level ColdFusion framework that everything goes through. Then, the request would be routed to a lower-level Controller (a "subsystem" in Framework One,FW/1). From there, the Controller would very likely talk to an Application Service to handle things like high-level authentication, check sessions, log requests, setup response variables, handle high-level rate-limiting, etc. Then, once the overall request was verified, the Controller would hand-off to a Command or Query workflow.So, for example, at work, all requests get routed by the
Application.cfcconfig to a "common" controller before they get routed to a feature-specific controller. That common controller has things like this (pseudo-code):Here, this is all pre-Command, pre-Workflow logic - just the Controller(s) doing high-level request processing using Application Services (and some Entity Services). Once this is done, at that point, we would dip down into something a bit more request-specific,handling Commands and Queries.
So, I think we are basically on the same page as to the workflow, now that I've filled-in some of the missing details.