
How Deeply Should Feature Flags Be Embedded In Your Application?
At work, we've been using Feature Flags (otherwise knowns as feature toggles) in our application for about a year. The usage started out in a single place; then, it was sprinkled throughout the application, as needed. Unfortunately, we never really took a moment to think about how feature flags should be used; or, how the use of feature flags should be reflected in the application architecture. This has caused a certain degree of friction when trying to refactor code. So, I wanted to take a minute and think out loud about how deeply the concept of feature flags should be woven into the fabric of the application.
For a little background, a feature flag is a mechanism for deploying code to a production environment in such a way that it is not immediately available to all users. At work, we use LaunchDarkly with ColdFusion, which is basically a "Feature Flags as a Service" provider; but, I've also played around with rolling my own Redis-backed feature flag system in ColdFusion.
Feature flags typically work by returning a True / False Boolean indicator based on a some sort of identifier. This identifier might be a user's unique account identifier. But, it could just as easily be something like an IP address, a security group (ex, "Beta Users"), or a "bucket" allocation. The returned Boolean value can then be used to expose user interfaces (UI) or manage request fulfillment.
Despite the open-ended nature of a feature flag's identifier, the feature flag is almost always associated with a user or group. After all, feature flags have to behave consistently; and, they can only do that if a given user is consistently associated with the same set of feature flags on every request to the application. Randomly assigning feature flags on every request would immediately defeat the purpose of a feature flag.
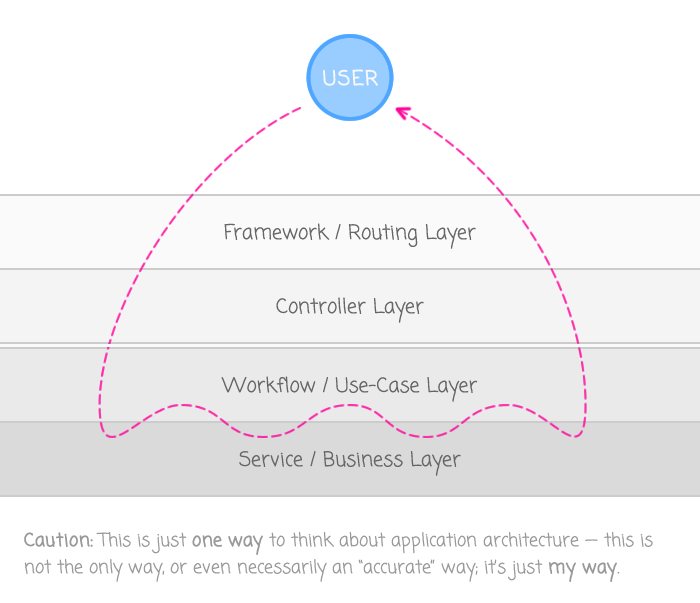
That said, at what point in the request life-cycle should a request be associated with a set of feature flags. To frame the conversation, here's the way that I think about the layers of a web-based application:
| |
|
|
||
| |
 |
|
||
| |
|
|
Keep in mind, of course, that this is just my own personal mental model for application design. Your application may be different; your mental model may be different; but, at least this graphic will anchor the conversation.
When I look at this graphic, the first thing that I notice is that the deeper the request goes into the application, the farther away the request gets from the User. This means that the deeper portions of the application are quite likely to have less information on which to base the feature flag assignment. A method call in the bowels of the business layer may have a "User ID"; but, what about the user's session data? Or the client IP address? Or the browser's User-Agent string? Probably not. The closer that we can move the feature flag assignment to the user's request, the more informed our assignment will be.
So, what about doing the feature flag assignment in the Workflow / Use-Case layer? I view this layer as the top layer of the "core" application. Meaning, this layer encapsulates the web-agnostic portion of the application. As such, it makes it hard to think about using this layer to perform browser-related decisions. For example, what if I wanted all "Safari Mobile" users to see a particular feature? To perform this assignment from within the user-case layer, I'd have to either break encapsulation and reach directly into the request data, which is ewww gross; or, I'd have to start passing the browser's User-Agent string into the use-case method, which also feels icky.
It seems to me, the only place to perform the most informed feature flag assignment would be in the Controller layer. This is where you know the most about the incoming request from a user-agnostic standpoint (ex, user-agent string, IP address, HTTP cookies); but, it's also the place where we know enough about the web-application as a whole such that we can easily access session, security, and user data.
If I could go back and re-architect the way our application uses feature flags, I would ensure that all feature flag assignments were done in the Controller layer. Then, those feature flags would be passed into the Workflow / Use-Case layer as static values. The use-case layer could then marshal requests using these pre-calculated feature flags, perhaps even passing the feature flags down into the lower layers (though that starts to feel a bit funky as well).
A side-effect of this controller-initiated set of feature flags would be that the internal layers of the application are easier to test. Since each subsequent layer action would be based on inputs, the control flow and output calculations would be much easier to reason about.
I'm still relatively new to the concept of feature flags. But, I'm not so inexperienced to know that we've made some unfortunate decisions in the way that we've implemented feature flags. We've made decisions that make refactoring the code harder because we've made feature flag assignments too deeply within the layers of the application. If I could go back and do it over, I would keep such decisions as high up in the application architecture as possible.

Reader Comments
Been thinking about this a great deal myself recently, as I too find it tends to litter itself across the codebase.
The trouble is, it's very nature is that you need access to it at all points throughout the stack, perhaps I'm adapting the UI slightly based on it, perhaps I'm locking access to a given controller/action, perhaps I'm augmenting some JSON data returned by an API... the list goes on.
My current approach is to bundle the feature flags into my authorization process, which has a helper method which is exposed in the controller and view layer:
<% if can?(:update, @profile) %>
This then authorises the user to perform that action, based on their role/permissions, but also against a feature flag.
Accessing this deeper down the stack is still something which I'm bugged by though, as these things should not really have access to the request context, and therefore the user.
Tricky.
@Robert,
Trust me, we're currently in the same boat. We have a "FeatureFlagService" that we can inject into anything. So, it's really easy for any developer to just inject that into some service and call:
if ( featureFlags.getFeature( user.id, "newLoggingThing" ) ) { .... }
The problem that I've run into, which made me realize that something was terribly wrong with this was that for some of these type of operations, I had to change "user.id" to something else -- something that I didn't have access to in the current execution context because I was too deep in the application.
The work-around for us was to push some logic into the inner-workings of the feature-flag service itself. The problem with this is that it required a database-lookup, which may not be called several times in any given request depending on how many parts of the code reference feature flags. We've tried to mitigate the issue by adding internal caching for the DB request; but, clearly, the architecture is making it hard to refactor.
@Ben
Glad to know other people have similar challenges. I think it's that whenever I find myself accessing the request context in the model it always smells a little; but without refactoring a bunch of things within the domain model you just have to suck-it.
One way I've seen this being handled is to allow instantiation/injection of the 'scope' into a given model, which can then be used to perform contextual checks, so something like.
class SomeController
bar = Bar.new(context: current_user)
end
class Bar
def do_thing
if feature_flags.get_feature(context.id, "newLoggingThing" )...
end
end
This allows the context to be switchable down the line, and doesn't tie the model directly to the user class, or the way in which the user is found or authenticated etc.
With regards to performance, obviously you're dealing at massively different scales to me, but we stick this stuff in Redis rather than in a traditional DB.
@Rob,
That's very interesting. We don't really have a "domain model" that allows for new-ing Objects - we mostly have a pile of Singletons that "do stuff". Basically a bunch of procedures wrapped in superficial OO. So, we can't really swap contexts. But, we can certainly pass data into the methods since the singletons are, more or less, stateless.