
Why Message-Queues Don't Carry The Stigma Of An Integration Database
One of the worst sins that the InVision App engineering team ever committed was allowing two systems to communicate directly with a single, shared database. As is often the case, this was done because we needed a quick solution; and - as is often the case - we've since discovered that the tight-coupling created by an "integration database" makes both systems extremely challenging to evolve. I can't even begin to tell you how infuriating it is to be half-way through a refactoring task when you discover that some other application is independently reading-from and writing-to the same database tables that you're currently refactoring. Once you create an integration database, it doesn't take very long for you to realize that an integration database is pure madness!
Clearly, I'm sensitive to the issue, having been burned badly by it before. Which is why I had a little moment of panic the other day thinking about message queues. A Message Queue is, essentially, a database. As is Kafka. As is Redis. So why is it that these systems - when used for messaging - don't carry the same stigma as an "integration database?" After all, they are databases that act as points of integration.
NOTE: I am specifically saying "when used for messaging" in the previous paragraph because Redis has both a Pub/Sub mechanism and a key-value store. As such, I want to be clear that I am only considering the Pub/Sub functionality for the purposes of this discussion.
| |
|
|
||
| |
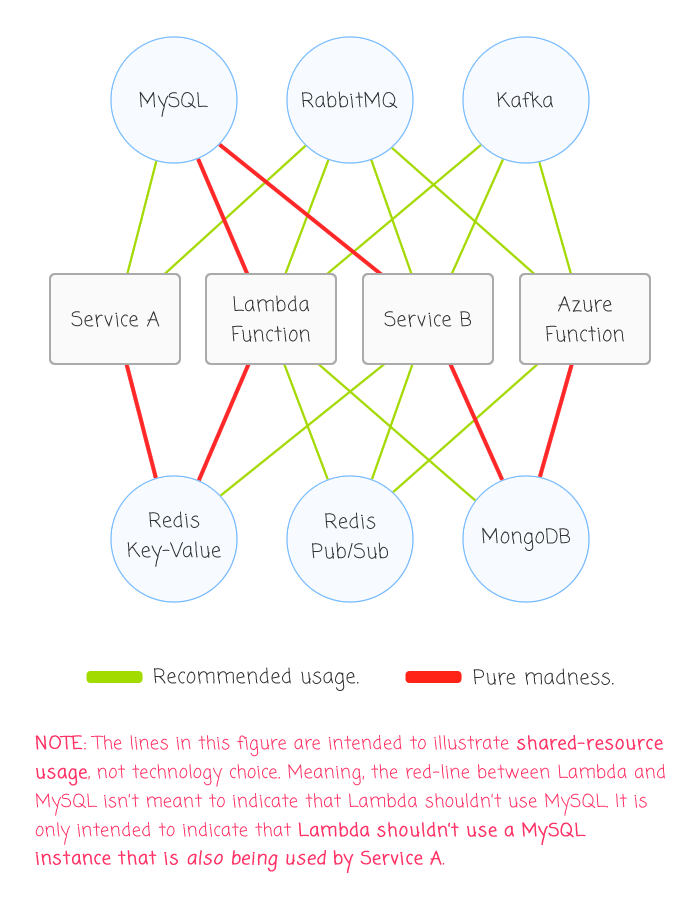 |
|
||
| |
|
|
For a sanity check, I turned to my CTO, Bjorn Freeman-Benson, who helped me noodle on the differences between an integration database and a message-based communications workflow. Here are the key points-of-interest that I've been able to articulate (in no particular order):
- Intent: Message Queues were intended, from day one, to be points of integration. That is their whole reason for being. As such, when a system consumes a message queue (in the general sense), that system is fully aware that the message queue is a point of integration. There are never any surprises. And, there are certainly no "WTF" moments when trying to refactor consuming code.
- Immutability: Messages represent immutable data. A message may be read, deleted, and re-queued; but, the contents of a message may never be changed. As such, there is no need to worry about data consistency within the bounds of a single "record".
- Controlled Reads: With message queues, the data access patterns are very controlled. Messages are pulled from either the top or the bottom of the queue. A consumer cannot randomly read from an arbitrary position within a queue.
- Ownership: Once a producer pushes a message onto a message queue, the producer is relinquishing ownership over that message. The message then remains "unowned" until a consumer pulls it. As such, no two systems will ever believe that they own a given message at the same time. This keeps the boundaries of each system very clear despite the point of integration and shared resource.
- State: Whereas a traditional database generally represents persisted state, a message in a message queue represents a state change, not the state itself (although it may contain relevant state data). As such, every system that consumes the message queue will still own its own state and is still the gatekeep for that state even if it's using the message queue to coordinate state change across systems. This keeps all state mutation within the bounds of a single system.
- Schema Flexibility: Whereas a traditional database table has a strict schema, a message queue can contain multiple versions of a single schema. As such, the producers and the consumers of the message queue still have to agree on message schema; but, they remain loosely coupled to each other, which minimized the possibility of creating regressions while evolving the systems independently.
- Bad Actor Performance: If two systems are sharing the same database, one system's data access patterns can have a direct and deleterious impact on the performance of the other system (since they both use the same shared resource). With a message queue, the actions of one bad actor won't directly affect the performance of the other system (although it may impact the performance of the message queue itself).
This list may or may not be complete. But, it is sufficient in giving me peace of mind. From this list, I can see that, while a message queue is a database that's acting as a point of integration, it doesn't suffer from the problems that make "integration databases" a source of friction for a distributed system. If anything, a message queue is an integration database that keeps systems loosely coupled and easier to evolve.

Reader Comments