
The Not-So-Dark Art Of Designing Database Indexes: Reflections From An Average Software Engineer
When I first started using databases in my software design, I didn't even know that databases had indexes (or "indices," for the more mathematically minded folks). In fact, I had already been building data-driven websites for a few years before I even worked on a database that was large enough to present with performance problems.
When I finally did start using database indexes, they felt mysterious and magical. Designing them seemed like some dark-art that required an extrasensory understanding of the data. Part of this was driven by the seemingly sparse amount of information about good index design. And, part of it was driven by vague and actionless advice that I received from others.
After more than a decade of working with database indexes, I can tell you that indexes aren't that mysterious. And, designing a good index doesn't have to be a "dark art." It just requires a little pragmatism and an understanding of how your application needs to access data.
To be clear, I am not a database administrator. I happen to really, really love writing SQL. And, I happen to have a great relationship with relational databases. But, my understanding of database mechanics is not terribly deep. I don't know much about binlogs or replication or sharding or the finer trade-offs of isolation-level usage in transactions. So, please understand that what I tell you about index design comes from my experience as a general software engineer, not as a database administrator.
This is not meant to be an exhaustive meditation on how to think about indexes. This is merely a primer for software engineers that think index design is mysterious. Ultimately, what I am trying to write here is the blog post that I wish I had had access to a decade ago. Your mileage may vary.
Caveats aside, I remember my "first time" like it was yesterday. I was in the middle of building a report generation interface for RecycleBank, a company that collected data about the recycling habits of entire communities. It was the largest application I had ever worked on (at the time). And, the SQL query in the report that I was writing was taking upwards of 45-seconds to run.
After doing some research about "query optimization", I told the project manager (PM) that I wanted to try adding this thing I had read about called an "index". After getting some push-back from the PM (who clearly knew as little as I did about database design), I finally got the go-ahead.
And, holy mother of dragons! I added a single-column index and the query time for my report generation dropped from 45-seconds to 0.2-seconds. That's a several-orders-of-magnitude performance improvement. And I didn't have to change the SQL at all - I only changed the way the database was organizing the information internally.
At that moment, I knew that database indexes were going to be a critical part of data-driven web application development. So I started to read what I could about good index design; and, I attended every conference talk that I could about databases; and, what I found was a whole lot of fuzzy, ambiguous "it depends" kind of insight. Which lead me to believe that database index design was actually really complicated and required a 4th-degree black belt in data-jitsu!
TL;DR
What I eventually came to realize, after years of impostor syndrome, was that database index design is simply not that mysterious: If you need to access data quickly, you index it. If the performance of data access isn't a concern, you don't index it. That's 90-percent of what you need to know about database indexing.

Before we talk about the specifics of index design, though, I think it's important to cover some fundamentals with regard to how indexes work. If you have no interest in a database index primer, please feel free to skip down to the "How To Design A Good Database Index" section.
Basic Index Concepts
An index in a database is very much like the index in a book. And, just as a book's index points to locations within the book, a database's index points to records within the storage engine. The database organizes the indexes such that these pointer values can be found extremely fast. And, once the database has located a desired set of pointer values, it can then turn around and quickly read the full table records. So, in the end, a database index is a means to locate and read table data as quickly as possible.
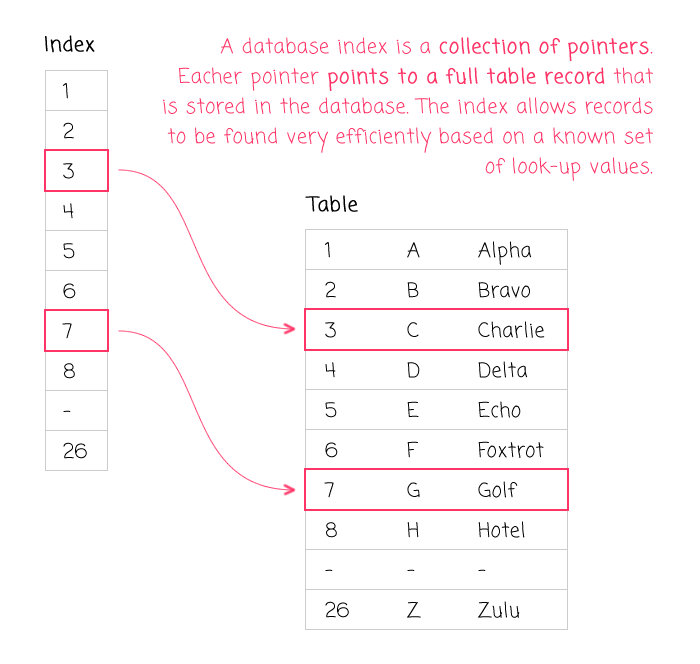
An index can contain values from one table column, as in the example above. Or, in the case of a composite index, multiple columns in the same table (sometimes called a "compound" index). When an index contains multiple columns, the order of the columns in the index matters. You can only leverage a composite index to search for columns in the same order in which the index provides them.
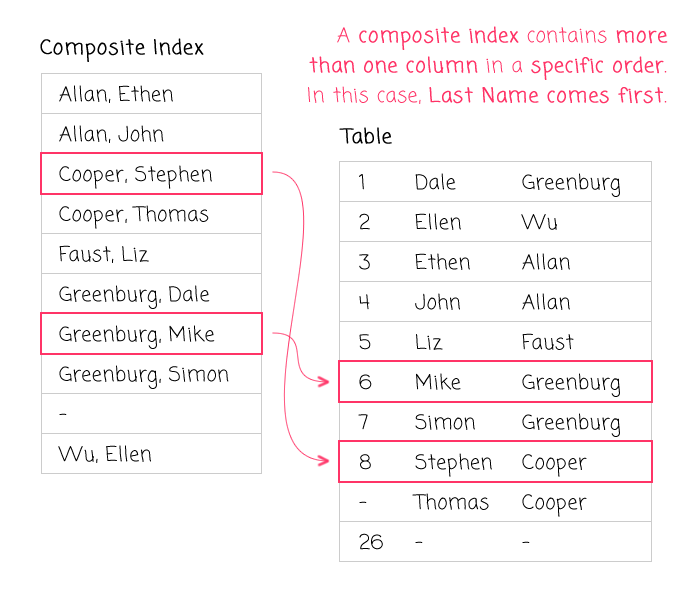
Consider a phone book (if you are old enough to remember what that is). You can think of a phone book as a data table that has a composite index on two columns: (LastName, FirstName). Because LastName is ordered first, you can quickly locate persons with a given LastName followed by a given FirstName. However, if you wanted to locate persons by FirstName alone - the second column in the composite index - the order of the names in the phone book is no longer beneficial. Since the listings are ordered by LastName first, you'd have to scan through the entire phone book in order to locate the necessary persons.
Composite Indexes And Leftmost Prefixes
With a composite (multi-column) index, you don't have to consume all of the columns in the index in order to gain a performance boost. Going back to the phone book example, if you wanted to find all persons with a given LastName, regardless of the FirstName, you could still leverage the organization of the phone book. This is known as using the "leftmost prefix" of the composite index.
To make it more concrete, consider the following table:
/* NOTE: I've removed the data-types to make it easier to read. */
CREATE TABLE `listing` (
`id`,
`firstName`,
`lastName`,
`isPrivateListing`,
`phoneNumber`,
`createdAt`,
PRIMARY KEY (`id`),
/* SECONDARY INDEX HERE: */
KEY `byName` (`lastName`,`firstName`,`isPrivateListing`)
);
In this table, we have a secondary, composite index on (lastName, firstName, isPrivateListing). The order of the columns in the index determines what kind of searches can leverage it. And, thanks to "leftmost prefix" consumption, all three of the following WHERE clauses would benefit from this index:
- WHERE lastName = ?
- WHERE lastName = ? AND firstName = ?
- WHERE lastName = ? AND firstName = ? AND isPrivateListing = ?
As long as the order of the columns in the search matches the order of the columns in the composite index, the database query optimizer should apply the composite index to the search execution.
Conversely, the following WHERE clauses would not benefit from this index:
- WHERE isPrivateListing = ?
- WHERE firstName = ?
- WHERE firstName = ? AND isPrivateListing = ?
This is because the columns being searched to not match the order of the columns in the composite index.
How Indexes Are Structured
When designing an index, you can select the columns contained within the index; but, you can [sometimes] also select the way in which the index is structured. The structure of the index determines how fast the index can be accessed and what kind of queries can leverage it.
Perhaps the most common type of index structure is the B-Tree. The B-Tree is a self-balancing, sorted variation on the binary tree structure that stores the index values in a relatively shallow but wide shape. The sorted nature of the B-Tree lends itself well to range-based scanning and sequential access as well as equality-based access. It can also provide "leftmost prefix" searches (ie, using a leading subset of the columns in a composite index).
There are other types of indexes, like filtered, hash, full-text and geo-spacial. But, those are far more specialized and beyond the scope of this primer. And to be honest, in a relational database, I believe I have only ever used the B-Tree structure.
B-Tree Composite Indexes And Range Queries
While a B-Tree structure lends itself well to range-based queries, in databases like MySQL, a query can only apply an index-based range-search to the last-consumed column in a composite index. That's not to say that you can't use a range-search on multiple columns in a single query - only that one of them will be powered by the index and one of them will be powered by subsequent filtering.
For example, if we have a composite index on (lastName, firstName), the following queries will be powered by the index in MySQL:
- WHERE lastName = ?
- WHERE lastName >= ?
- WHERE lastName = ? AND firstName = ?
- WHERE lastName = ? AND firstName <= ?
As you can see, in each of these queries, at most one range-search is applied; and, it's always applied to the last consumed column of the composite index (which may not account for the entire breadth of index columns).
In contrast, the following queries can run in MySQL; but, they wouldn't be powered entirely by the index:
- WHERE lastName <= ? AND firstName >= ?
- WHERE lastName >= ? AND firstName = ?
In this case, because "lastName" is using a range-query, the "firstName" filtering is performed after the tabular data has been read. This will be fast; but, not as fast as it could be.
Uniqueness Constraints
The nature of an index is simply that it has searchable values that point to table records. There is nothing that says that the values within the index have to be unique. And, in fact, many times, they are not. Once again, consider the index in a book - if you look up "endoplasmic reticulum" in the back of a Biology textbook, the index will likely point you to several different pages in the book, not just a single page.
If, however, you know - or want to guarantee - that an index will only contain unique values, you can add a uniqueness constraint to your index definition. For example, the following table has an index on "email" that requires it to contain unique values across the entire table column:
/* NOTE: I've removed the data-types to make it easier to read. */
CREATE TABLE `user` (
`id`,
`email`,
`createdAt`,
PRIMARY KEY (`id`),
/* SECONDARY INDEX HERE: */
UNIQUE KEY `byEmail` (`email`)
);
If you attempt to INSERT a duplicate email into this table, the database will throw an error. Not only does this help enforce business rules, it can also help facilitate idempotent workflows - something we will talk briefly about at the end of this post.
Primary Key Index / Clustered Index
Every table in the database, no matter how small, should have a primary key (sometimes called a "clustered index"). The primary key is the column - or set of columns - that uniquely identifies every individual record in a table. This primary key is then used to search for and act upon a single, specific record.
NOTE: Many databases will actually generate a hidden primary key on a table if you don't explicitly define one. But, you should always define one.
There are two philosophies on primary key designation: a natural key and a surrogate key (sometimes called an "artificial" key or a "mechanical" key or a "synthetic" key). A natural key is one that is based on the fundamental nature of the data itself, like a person's Social Security Number (SSN) or a product's SKU number. A surrogate key, on the other hand, has nothing to do with the data but is designed specifically to be unique, like an auto-incrementing value or a Universally Unique Identifier (UUID).
While I think there is a lot of romance (and debate) around the idea of a "natural" primary key, I've never been smart enough to get it to work. Data that you think of as being unique and consistent in theory is often never as unique and clean in "real life." For example, even Social Security Numbers get re-used in real life, making them an unsafe choice for primary key.
A primary key has to be unique. And a "surrogate" primary key only ever requires a single column in order to fulfill this uniqueness constraint. Contrast this with a natural key which may require several columns in order to ensure uniqueness within the table.
Personally, I just use the auto-incrementing or ever-increasing feature provided by the database. This works well for the majority of applications; though, it may start to fall-down when you have a very large, distributed, sharded, or event-driven application. In those cases, it can be beneficial to have your application logic generate the primary key value and provide it to the database (or event stream). In such cases, people often use a UUID, GUID, or CUID.
While I don't think it isn't necessary to understand databases at this level, I will mention that the Primary Index / clustered index can determine how data is stored on disk. In fact, in both Microsoft SQL Server and MySQL's InnoDB storage engines, the Primary Key and the row data are stored in the same data-structure (the row data is actually stored in the leaf-nodes of the clustered index B-Tree). This is an implementation detail; but, it's what makes the primary key so fast.
Secondary Index
In addition to the primary key index, every table can have zero or more secondary indexes. A secondary index is nothing more than an additional index on the same table. It can contain one or more columns. And, its columns can overlap with other indexes on the same table. Secondary key indexes are really where index design gets interesting.
An important thing to understand about secondary indexes (at least in common databases) is that each value in the secondary index is implicitly augmented with the primary key index value of the same table. The secondary index value doesn't actually point directly to the full table record. Instead, the secondary index value points to the primary index value, which is then, in turn, used to read in the full table record.

What this means is that the primary key value doesn't have to be explicitly added to your secondary key index - it's already there. As such, you should be able to SELECT the primary key value when performing a secondary key search without having to read from the table record. This becomes meaningful when dealing with JOINs and "covering indexes" (which we'll discuss a bit later).
As a side-note, this implicit extension of the secondary index is yet another reason why primary key values should be small and artificial: not only are they stored in the primary index, they are duplicated in all of the secondary indexes on the same table (and of course, required in any foreign key relationship).
Indexes Are Not Free
While an index can be absolutely essential to an application's performance, it should be said that indexes are not free. They have to be stored, which requires disk and memory space. And, they have performance implications: every time the records referenced by an index are altered (insert, update, delete), the database may need to reorganize the index so that subsequent reads are optimized. This re-balancing of the index structure takes time and will delay the response to your query (and to your users).
To make this concrete, in a large table, it would not be unheard of for index size to be measured in Gigabytes. For example, at work, our largest index requires 33Gb of storage space. That's 33Gb above and beyond the storage cost of the raw table data.
This overhead doesn't make indexes bad or prohibitive - it just means that they are a necessary trade-off. Many indexes will be worth their weight in gold; some will not. Calculating the trade-off is a factor of how often the query is run (ie, the value to the users) vs. the cost of storage and maintenance.
Using Multiple Indexes In The Same Query
Databases and query optimizers are very intelligent (much more so than I am). And, when possible, they can actually use more than one index to optimize a single query (aka "Index merge optimization"). However, I would recommend that you ignore this fact. Instead of assuming that a database can use multiple indexes, you should take complex queries and break them up into multiple smaller queries that each rely on a single index. This will simplify your queries and make them easier to understand, consume, and maintain.
NOTE: This does not pertain to sub-queries, dependent queries, and UNION'd queries, which can all use a separate index.
In fact, I would recommend that you try to keep your queries as small as possible. Having nothing to do with indexes, smaller queries are easier to work with and to refactor. And, they are more likely to be cachable by the database. Not to mention that it is easier to see common data-access patterns in smaller queries.

I spent the first half of my career figuring out how to write super complicated, multi-hundred-line queries; and, I've spent the second half of my career trying to figure out how to undo all that complexity.
How To Design A Good Database Index
Now that we have a foundational understanding of what indexes are and how they are structured, we can finally look at how to design a good index. This discussion will be split between Primary Key design and Secondary Key design as these two types of indexes represent two very different types of access patterns.
How To Design A Good Primary Key Index
As I stated earlier, there is some debate over whether or not you should use a "natural" key or a "surrogate" key in your Primary Key / clustered index. I prefer to use an incrementing or ever-increasing surrogate value and I suggest that you do the same.
I am explicitly trying to avoid the term "auto-incrementing" as the auto-incrementing feature provided by the database is an implementation detail. An "ever increasing" column could just as easily be based on some other approach, like a time-based CUID value.
By default, I give all of my database tables an ever-increasing surrogate primary key (usually MySQL's AUTO_INCREMENT column feature). This is true even if the table "appears" to do nothing but establish a relationship between several other tables (sometimes referred to as a "Join Table"). I find that this approach has several benefits:
First and foremost, it simplifies the process of designing tables because it's an easy-to-follow rule that your teammates don't have to argue about.
It also creates a consistent and predictable access path across all tables. This makes the database easier to work with for all team members.
It forces you to leave the "Join Table" mindset and think more about relationships as "entities." This leads to a richer, more semantic domain model that provides for a more robust and flexible application platform. For example, instead of having a "Join Table" that relates a "user" to a "team", including a surrogate primary key can help you turn that table into a "membership" table that happens to reference "user" and "team" identifiers along with a bunch of other membership-attribute data.
Another benefit of favoring a single-column surrogate key over a natural key is that it makes foreign keys easier to work with. In a foreign key relationship, the primary key of one table has to be duplicated and maintained in another table. As such, using a single-column primary key keeps data-duplication to a minimum.
The same benefit [of a surrogate primary key] applies to secondary indexes. As mentioned earlier, secondary indexes are implicitly augmented with the primary key values on the same table. By using a surrogate, single-column primary key, it implicitly keeps the size and maintenance overhead of the secondary indexes smaller.
For Primary Keys, that's really all there is to it (at least, in the way that I approach database design). Every table gets one. It's always an ever-increasing, surrogate, single-column value. The real interesting part of index design is reserved for Secondary Indexes.
A Quick Aside On The Auto-Increment Column
Some people believe that using an auto-incrementing, numerical key can "leak information" about the application. For example, an auto-incrementing key can offer insight into how large the database is, how fast records are being added, and how one might iterate over said records. Personally, if this kind of "data leakage" is a "problem" then I would suggest that you are doing "security" wrong (ie, "security through obscurity").
That said, sometimes creating "hard to guess" URLs is an important part of an application constraint. Such a constraint can be accomplished with an additional table column. Give each record a UUID value and then create a secondary index on said UUID. This will allow you to have a "normal" primary key while still providing fast look-ups on the longer, much harder to guess UUID values.
Extension Tables: The Exception To The Primary Key Rule
The one exception that I make to the "every table gets an ever-increasing primary key column" is for "extension" tables. These are tables that don't really represent a new type of "thing"; but, rather, contain additional information about an existing "root" table. In such cases, I give the extension table the same primary key as the root table:
/* NOTE: I've removed the data-types to make it easier to read. */
CREATE TABLE `user` (
`id`,
PRIMARY KEY (`id`)
);
CREATE TABLE `user_extended` (
`userID`,
PRIMARY KEY (`userID`)
);
In this case, the "userID" column of the "user_extended" table is the same value as the "id" of the "user" table. This is not a function of the database - it is something I have to implement in my application logic.
That said, I don't use this pattern all that often.
How To Design A Good Secondary Index
The secondary indexes on a table are the "search" indexes. They are the indexes that help you locate records when you do not know the primary key of the records ahead of time. As such, the columns used to define the secondary indexes should include the columns that help you find the data that you need in order to fulfill specific business requirements.
The fact that these indexes help fulfill business requirements is why so many people hide behind the lackluster response, "It depends." After all, the requirements "depend" on your particular business. But, there's nothing more infuriating than, "it depends;" so, I am here to tell you concretely that you should index the columns that help you quickly find answers for your users. The only "it depends" portion of that concept is where you draw the line between performance and cost (of maintenance and storage).
Unlike Primary Index design - which is always an ever-increasing surrogate key - Secondary Index design evolves with the application. As the application needs change, so will the existence and composition of the secondary indexes in your database. This is not a short-coming of your database design - it's a byproduct of shifting business priorities and application life-cycles.
Take, for example, a "user" table with the following columns:
/* NOTE: I've removed the data-types to make it easier to read. */
CREATE TABLE `user` (
`id`,
`firstName`,
`lastName`,
`phone`,
`state`,
`zip`,
PRIMARY KEY (`id`)
);
Given such a table, how would you define a secondary index?
Trick question! We don't know what secondary indexes we need to create because we don't yet know how this table will be used. In order to create a secondary index, we have to:
- Interview stakeholders about the application.
- Look at the way the code implements data access.
- Create secondary indexes that "pave the cow-paths".
- Repeat until the application is end-of-life'd.
When I say, "pave the cow-paths," what I mean is that we look at the existing patterns in the application and then add indexes that make the existing patterns faster. This is exactly what I did with the RecycleBank application (mentioned in the introduction) - I added a secondary index to optimize a reporting query that was already in place.
So, if we look at the application and we find that it often looks for users based on their Last Name and First Name, we can create a secondary index on (lastName, firstName):
/* NOTE: I've removed the data-types to make it easier to read. */
CREATE TABLE `user` (
`id`,
`firstName`,
`lastName`,
`phone`,
`state`,
`zip`,
PRIMARY KEY (`id`),
-- We have created this composite, secondary index because it will
-- help improve the performance of existing pathways in the application.
KEY `byName` (`lastName`,`firstName`)
);
Such an index would facilitate queries in the form of:
- WHERE lastName = ? AND firstName = ?
And, thanks to "leftmost prefix" consumption, it would also facilitate queries in the form of:
- WHERE lastName = ?
On day one, this may be sufficient. But, let's say that later on, the application interface needs to allow users to filter on "State" as well as the required Last Name / First Name combination. At that point, we have a few options:
We do nothing. If the database is small enough, it may be entirely acceptable to locate records using the (lastName, firstName) index and then apply an optional "State" filter to the intermediary recordset. In fact, if the database were sufficiently small, such filtering could even be done in the application code (as opposed to the database process).
We could drop the current index (lastName, firstName) and then re-create it with the addition of state: (lastName, firstName, state). This larger index would require more storage space and computation time to re-balance; but, it would still work for name-only queries while also providing fast queries on all three columns.
The option that you choose will depend on the performance requirements of the application and the relative performance of the query both before and after any structural change to the index. It's important to always run an "EXPLAIN" on the query to see how it intends to use the indexes provided on the table. Then, it's a matter of human judgment.
The key take-away here is that the secondary indexes should include the columns that you use to narrow down record-selection in your queries. These columns can be identified because they are often:
- Part of the WHERE clause.
- Part of the JOIN clause.
- Part of the GROUP BY clause.
And, of course, there's absolutely nothing wrong with having multiple secondary indexes on the same table. You do not need to create a single secondary index that searches for "all the things!" Such an endeavor is impossible. Given the table above, if your Analytics team came to you and told you that they needed the ability to calculate demographics based on state and zip, it would be reasonable to end up with several secondary indexes on the "user" table:
/* NOTE: I've removed the data-types to make it easier to read. */
CREATE TABLE `user` (
`id`,
`firstName`,
`lastName`,
`phone`,
`state`,
`zip`,
PRIMARY KEY (`id`),
-- We have created this composite, secondary index because it will
-- help improve the performance of existing pathways in the application.
KEY `byName` (`lastName`,`firstName`),
-- We have created these composite, secondary indexes because they will
-- help the Analytics team run demographic calculations.
KEY `byState` (`state`,`zip`),
KEY `byZip` (`zip`)
);
Notice that these secondary indexes have overlapping columns. There's nothing inherently wrong with that. Each secondary index is geared towards the optimization of a query (or set of queries) that fulfill a given business requirement.
NOTE: Remember, composite (multi-column) indexes can only be used if the column filtering in the query matches the index definition. Meaning, the (state, zip) index cannot be used to filter purely on "zip". That's why we needed to add an additional secondary index for "zip"-only filtering. Of course, there are ways to get around this, like passing every state to an "IN" clause, essentially creating a non-selective filter on state:
WHERE
-- By passing all possible values in for "state", we essentially turn
-- the composite key prefix into a "non-selecting" column. This gives
-- us access to the second column in the composite index.
state IN ( 'AL', 'AK', .... 'WI', 'WY' )
AND
zip = '10010'
But, such tricks are far beyond the scope of this post.
Sometimes You Pave Cow-Paths, Sometimes You Move The Heard
Oftentimes, the indexes you create will be designed to serve the existing data access patterns - what I referred to as "paving the cow-paths." Sometimes, however, due to a variety of business and resource constraints, paving the cow-path isn't a viable option. In such cases, query optimization can be performed in reverse. Instead you have to take a look at what indexes already exist and then refactoring your queries to leverage those indexes. This often means creating a sub-optimal query that still performs better than it did before. Such trade-offs are a legitimate and pragmatic approach to data-driven application design.
Using EXPLAIN To Understand How Your Secondary Indexes Are Being Applied
When you execute a query in MySQL, your SQL statement gets parsed by the database engine and run through a query optimizer. The optimizer examines the structure of your SQL, looks at the participating tables, compares them to the collection of existing indexes, looks at the table statistics, and then figures out how to most efficiently fulfill the query requirements.
In order to gain insight into how the query optimizer is going to execute your query, you can prepend "EXPLAIN" at the front of your SQL statement. Doing so will prevent the database from executing the query; and, instead, get the database to return information about the query execution plan.
/*
By prepending EXPLAIN to this SQL statement, the database will bypass
execution of the query. And, instead, it will return the results of the
query execution plan so that we can see which indexes are available;
and, which index the query optimizer will choose.
*/
EXPLAIN
SELECT
u.id,
u.firstName,
u.lastName
FROM
user u
WHERE
u.zip = '10010'
ORDER BY
u.lastName ASC,
u.firstName ASC
Running this will return a recordset in which each row pertains to a table in the SQL statement. Since we only have one table reference, this EXPLAIN query will only return on row:
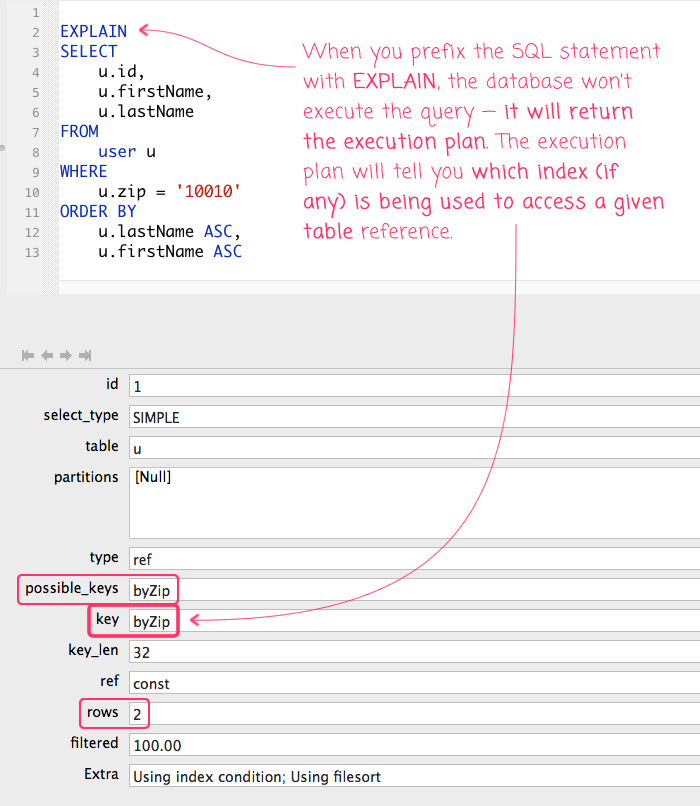
The results of the EXPLAIN contain a lot of information. It's all very useful; but, the breadth of which is usually more than I can keep in my head. As such, I just concentrate on a few key aspects:
possible_keys: This lists the indexes that the query optimizer is considering for the data access on the given table.
key: This identifies the actual index that the query optimizer has chosen for this query on the given table. If this value is empty, it means that the database will be performing a full table scan. This is almost always a big red flag!
rows: This is an estimate of the number of table rows that the database will have to examine in order to gather the desired records. This value should roughly match the number of records that the query returns (though, this is just an estimated value). If the number here is much higher than you would expect, this is usually a big red flag!
extra: This contains additional information about how the query optimizer will fulfill your query. The information in this field is robust and goes beyond the scope of this post; but, it's great for fine-tuning your query's performance (especially when it comes to things like Filesort and Temp table creation).
As long as the "key" value is not empty, you're moving in the right direction. A populated "key" means that the query optimizer was able to find an index that should allow for efficient data access.
If the selected "key" does not contain the index that you expected, this may be an indication that you need to restructure your index (or your query). In such a case, look at the columns being referenced on that table. This includes columns referenced in the SELECT, WHERE, JOIN, GROUP BY, and ORDER BY clauses. Double-check that you're referencing columns that make up some "leftmost prefix" of the composite index that you want to use.
Covering Indexes
Earlier, I mentioned that a secondary index points to the primary key (clustered) index, which in turn is used to read-in the full table records (which, in the case of MySQL and MSSQL Server are stored in the actual clustered index data structure). This relationship is what allows a secondary index to quickly locate disparate table records. However, sometimes, all of the data that you need is contained directly within the secondary index itself. In such a case, the database can short-circuit the lookup because it doesn't even need to read from the full table record. This is known as a "covering" index because its contents fully cover the read-requirements of the query.
The short-circuiting nature of the covering index can make a query perform extremely fast. It's something to aim for, especially in "hot" pathways in your application. However, it's not always possible to create a covering index; nor, is it always worth the cost of the increased index size and maintenance overhead.
One complication of the covering index is that the read-requirements include both the look-up portion of the query and the "select" portion of the query. If your index includes the look-up columns, but not the "select" columns, the full table record will still have to be loaded into memory. Of course, an index-based look-up is still a lot better than a full-table scan, even if the index doesn't cover the full read requirements of the query.
In the above description, I am quoting the term "select" because I am not referring to the "SELECT" clause specifically but, more generically, to any portion of the query that needs to read data. When all you have is a "SELECT" clause, the read requirements are more obvious. However, with something like an INNER JOIN, the full read requirements can be subtle.
For example, in the following INNER JOIN:
FROM
membership m
INNER JOIN
role r
ON
(
m.userID = ?
AND
m.teamID = ?
AND
r.id = m.roleID
)
... you may think that the "read" columns are just "m.userID" and "m.teamID" because those are the columns that you're searching on. However, in order for the query to compute the JOIN cross-product, it has to know "m.roleID" as well. So, even though you are not "looking up" the records based on "roleID", you are still consuming the "roleID" column".
Given this INNER JOIN, an index on (userID, teamID) would be very fast. But, it would not be a "covering" index. An index on (userID, teamID, roleID) would be more likely to "cover" the read requirements and could, therefore, perform even faster by not having to read anything from the full table row.
NOTE: Of course, I'm only showing the JOIN portion of this query. The optimizer's choice of index and the index's ability to "cover" is still a factor of all query clauses, including SELECT, JOIN, WHERE, GROUP BY, and ORDER BY.
Ultimately, if you can create a covering index, it can be great for performance. But, if you can't, it's not the end of the world. The best side-effect of thinking about covering indexes is that it forces you to think more deeply about data-access patterns, query construction, and index structures.
JOIN Filtering Helps You See And Think About Read Requirements
There is an old-school mindset that believes JOIN clauses should only include the columns necessary to define the cross-product of two tables. All "filtering" of the resultant cross-product should then be performed in a subsequent WHERE clause. This approach certainly works - there's nothing "technically" wrong with it; but, it spreads the read-requirements of the query across a multitude of clauses.
FROM
user u
INNER JOIN
membership m
ON
m.userID = u.id
WHERE
u.id = ?
AND
m.teamID = ?
To help consolidate read-requirements, I highly recommend that you move as much filtering into your JOIN clauses as you can. For example, we can rewrite the above query as such:
FROM
user u
INNER JOIN
membership m
ON
(
u.id = ?
AND
m.userID = u.id
AND
m.teamID = ?
)
As you can see, we were able to drop the WHERE clause entirely by moving all read-requirements into the INNER JOIN's ON condition. This makes it very easy to see which columns are required to calculate and then filter the cross-product.
Another huge benefit of this (in my opinion) is that it really only works with INNER JOIN. If you attempt to do this with a LEFT (or RIGHT) OUTER JOIN, you will mostly likely get more records than anticipated because your filtering won't limit the cross-product (at least, not in the same way that a WHERE clause would). I call this a "benefit" because INNER JOIN is the superior JOIN. In most cases, a LEFT OUTER JOIN can be re-worked as an INNER JOIN; or, it can be broken up into two separate queries that are each simpler and more efficient.
So, while your JOIN structure has no technical bearing on your secondary index design, moving filtering into your INNER JOIN can help you - as a human - see read-requirements more clearly. And, the more clearly you can see the read-requirements, the easier it will be to design an efficient secondary index.
Foreign Key Colloquialisms And Constraints
No discussion of Secondary Index design is complete without a quick look at "foreign keys". In the context of a database, foreign keys are both a "colloquialism" and a "constraint." From a colloquial standpoint, a foreign key is nothing more than a column in one table that represents a primary key in another table (or the same table within a hierarchical structure).
For example, in the following table, the "groupID" column could be a foreign key:
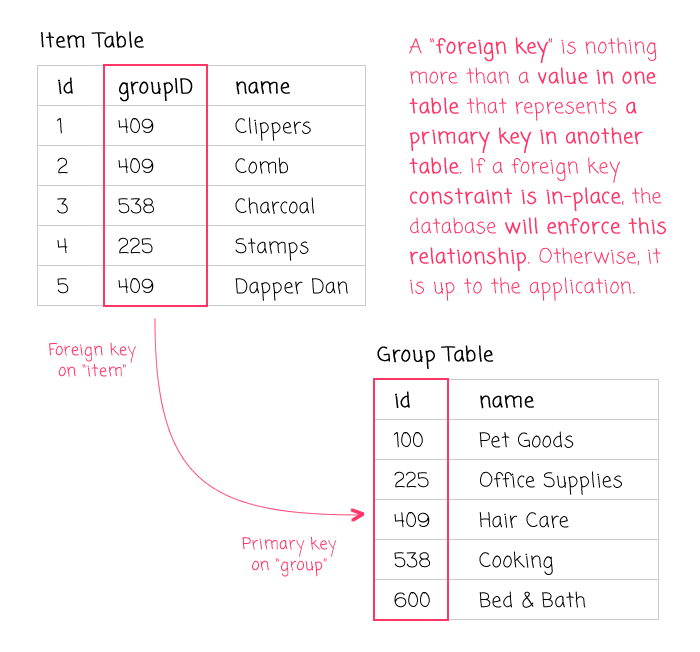
In this case, "groupID" on one table is a "foreign key" that represents the primary key, "group.id", in another table. When used in the informal sense, this relationship is merely conceptual - something that the engineering team understands and that the application logic accounts for.
When a foreign key is used as a "constraint" (ie, an actual configuration at the database level), the database engine itself will actively enforce the relationship between the foreign key and the primary key that it references. Meaning, the database won't let you delete a primary key if it is being references as part of a foreign key constraint.
A foreign key "constraint" may imply a more "correct" database; but, I almost always only use foreign keys as a "colloquialism". Meaning, I have columns in one table the represent the primary key in another table; but, I almost never add the technical constraint at the database level. I omit foreign key "constraints" for several reasons:
They make data migration harder. This is especially true if you have to swap tables while the application is running.
They make data deletion harder. This is especially true if you want to execute some of the deletion in a synchronous manner and some of the deletion in an asynchronous manner (imagine deleting the "root" record now, and then cleaning up all the "referential records" later).
They enforce a technical constraint in places where there may not be an actual business constraint.
They make it harder to extract and move portions of your database into different services (such as when decomposing a monolithic application into a collection of microservices).
Pontification aside, foreign keys are important to be cognizant of because they will almost always be part of a secondary index. If a table has a foreign key, then your application will probably search for records based on that foreign key; or, it will JOIN records based on that foreign key. In either case, its inclusion in a secondary index will likely yield a large performance improvement.
For example, imagine that you have a "widget" table with the following columns:
/* NOTE: I've removed the data-types to make it easier to read. */
CREATE TABLE `widget` (
`id`,
`userID`, -- Possible FOREIGN KEY (user.id).
`categoryID`, -- Possible FOREIGN KEY (category.id).
`name`,
`price`,
PRIMARY KEY (`id`),
-- These secondary indexes contain the FOREIGN KEYs. This will likely
-- help you search this table and / or JOIN it to other tables. Note
-- that this table doesn't define any foreign key CONSTRAINTS; these
-- foreign keys are just conceptual.
KEY `byUser` (`userID`),
KEY `byCategory` (`categoryID`,`price`)
);
In this case, "userID" and "categoryID" are foreign keys that represent primary keys from other tables. Including these in one [or more] secondary indexes makes sense because your application is likely to:
- Search for all widgets entered by a given user (WHERE).
- Search for all widgets in a given category (WHERE).
- Report widget names and categories (JOIN).
Which secondary indexes you create depends on how the columns are used in your application. But, rest assured that if you have foreign keys, you will likely need to include them in some secondary index.
GROUP BY And ORDER BY Optimization
Primary and Secondary Indexes are typically stored in B-Tree structures, which means that they are stored in sort-order. This sort-order storage can theoretically be used to make GROUP BY and ORDER BY operations more efficient; and, in some cases, can even obviate the need for an ORDER BY clause entirely.
To be honest, however, I am not capable of thinking about this effectively. I bring it up because it's interesting to keep in the back of your mind. But, I have found this optimization to be something that is quite hard to understand and / or leverage. I know that in my work, the vast majority of ORDER BY clauses doesn't even reference a column in the index.
ORDER BY At Large Scale
In a large application, instead of trying to structure my secondary indexes to make ORDER BY operations more efficient (see above), I tend to just move the ORDER BY concept out of the database process and into the application itself. Meaning, I pull the records out of the database in whatever order they happen to arrive; then, I either sort the data on the server or pass it back to a client that sorts it in the browser.
There are many people that would scoff at this approach, saying, "let the database deal with the data - that's its job!" And, this is a totally legitimate mindset and works well for a lot of applications. But, it comes down to an understanding of scalability.
Typically, you have one database within an application boundary. You then have N load-balanced Application Servers that connect to that one database. After which, you have M Client Applications that connect to those N Application Servers. As you move toward the client-side in this funnel, the amount of horizontal processing power increases:
1 Database <= N App Servers <= M Client Apps
While adding an "ORDER BY" to your SQL clause is the easiest approach, it is also more likely to be the processing bottleneck. If you can defer the ordering operation to a lower-tier, you can spread the load over a larger number of processors.
NOTE: To be clear, I am not advocating this approach for all applications. This is certainly not my default optimization. This is a change that I would reserve for an "optimization" sprint in the application development life-cycle. And, in smaller applications, is probably something I would never even need to consider.
Read Replicas Can Have A Different Index Design
In many cases, a read-replica has the exact same structure as the master database. And, is really only there to help scale-out reads. As such, good secondary index design isn't really affected by replication.
However, one really interesting part about database replication is that your read-replicas can, theoretically, have different indexes on top of the same data. I've never actually tried this myself (and frankly, I don't even know how you would configure and manage this). But, it allows for read-replicas to have indexes that are more optimized for some set of SELECT queries in your application.
I think this makes the most sense for "reporting" purposes and other completely tangential business requirements. Meaning, I think it would be too difficult to manage the divergent structures (mentally and technically) simply for application queries that can put up with some small staleness.
Consider Splitting Data Instead Of Soft-Deleting It
When implementing delete operations in an application, it is not uncommon for us to use "soft deletes". These are deletes in which the data isn't actually removed from the table, it is only "deactivated." This typically involves setting some sort of a flag or filling-in a date field:
UPDATE
membership
SET
endedAt = ? -- Soft delete of record.
WHERE
id = ?
In a soft-delete context, many of your application queries will then need to include the soft-delete flag when accessing data:
FROM
membership
WHERE
userID = ?
AND
teamID = ?
AND
endedAt IS NULL
In order to make this data-access pattern fast, these soft-delete flags are often included in some sort of secondary index. This adds overhead to the index storage and re-balancing; and, of course, requires additional logic in every single query made against that table.
Same-table soft-deletion works. But, one optimization that I would recommend is to move "deactivated" records into another table. With this approach, rather than updating a "soft-delete" field, you physically move the record out of the "active" table and into an "archive" table:
-- First, insert the soft-delete record into the archive table.
INSERT IGNORE INTO
`membership_archive`
SET
id = ?,
...
endedAt = ? -- Still using a soft-delete flag for recording purposes.
;
-- Then, delete it from the active table.
DELETE FROM
`membership`
WHERE
id = :id
;
Using an "archive" table means that you now have to manage one set of data across two tables. But, it has a number of benefits:
It simplifies all of your queries because you no longer have to account for soft-delete logic.
It simplifies and reduces the breadth of your secondary indexes because you no longer have to include the "soft-delete" column.
It reduces the storage size of your secondary indexes because they only have to organize your active data.
It allows you to exclude most indexes on your "archive" table (depending on how and if your application consumes the archive table).
For me, this approach is not just an "optimization" - it's something that I wish I did more often. I've tried to retrofit and back-fill this approach into a large application (with some success); but, it's really an effort best used right from the inception of a project.
Leaning On UNIQUE Indexes To Power Idempotent Actions
Everything we've talked about so far revolves around database index design as a means to facilitate data access. But, indexes with UNIQUE constraints can also be used to power idempotent actions. An idempotent action, roughly speaking, is an action that is safe to retry. By using a UNIQUE index in combination with something like "INSERT IGNORE INTO" (which won't error on key collision), you can work towards removing application-level locking. This, in turn, reduces code complexity and increases application though-put.
Index-powered idempotent actions is a whole other topic that we don't have time to get into; so, I would just point you to the earlier article I wrote on the matter. But, I wanted to tease-out this concept here so that it could start marinating somewhere in the back of your mind.
Conclusion
Oh chickens! I know this was a lot to take in. But, hopefully some of my ramblings have helped to demystify database index design. There's no doubt that you can get really fancy with indexes - far beyond anything I have in my skill-set. But, for the lion's share of cases, keep it simple. Don't over-think it. If you need to search a table based on a given column, create a secondary index on that column. If you need to search a table based on several columns, create a secondary composite index on those columns.
And, just remember that the secondary indexes in your database will evolve with your application. That's a good thing - it means that you're continually evaluating and fine-tuning your application performance. If your secondary indexes change over time, it means you're doing it right!
Want to use code from this post? Check out the license.

Reader Comments
Great blog. I really learnt so much. I am looking forward to adding an index to 'tadstats', which stores every impression & hit from my advertising platform. As you can imagine, thousands of new records are inserted every day. I noticed recently that querying the DB, is taking longer & longer. Maybe, an index will help.
I have one question. If I create an index, like:
If I use a WHERE clause, like:
Does the index still get applied to the 'userid' part?
And also, does the order in the WHERE clause, matter:
CORRECTION:
Does the index still get applied to the 'lastName', 'firstName' part?
@Charles,
First, I am super glad you enjoyed the article! That pleases me greatly.
With regard to your question, the answer is "maybe", depending on if you have other indexes. If you have no index on
email, then your query will have to do a full-table scan. Even if thebyNameindex could get used, it wouldn't matter because theOR email = ?essentially negates the benefit (you essentially have to examine every record to see if thatORcondition is true).That said, if you also have an index on `email:
... then it's possible that the query optimizer will actual apply both indexes and then merge the results. You can think of it as basically doing something like:
Of course, there's no guaranteed that the optimizer will do that. In such cases, it could be beneficial to just break it into two separate queries - that way, there's no guess work.
OK. That makes sense. So, I presume it is not unusual to have multiple indexes per table. Just out of interest, how many indexes do you have on your database?
@Charles,
Yes, it's very common to have multiple indexes on a single table. Spot-checking some of our work tables, we usually have somewhere between 2-5 indexes on a table. Not all tables need them; but, if we have needs to search on various columns, we index them.
Thanks for this.
One last question. I have a table with a million records. It contains a column called 'Type'. This column can only accept 2 different values. So, if there were 500,000 'click' values, there would be 500,000 'impression' values.
Are 'indexes' only useful for columns that have mainly unique values or does it not matter.
@Charles,
This is another part of indexing that I am still a bit fuzzy on. The way I understand it is that if your index is only on the
typecolumn, then the index will probably not be used. Meaning, the query optimizer will see that it accounts for only a 50% selectivity, so it may just do the full-table scan regardless.But, if your index is a composite index that happens to start with the
typecolumn, that is a different story. If the subsequent columns have a higher selectivity, then I believe the the query optimizer should still use the index, even if the first column has low-selectivity.When they say that you should only index columns with higher-selectivity, that is true; but, I think you have to take the "breadth" of the index into account -- not just the first column.
That said, you definitely want to experiment with this and run it through
EXPLAINto see what the optimizer will do.Great stuff. I now fully understand. Time to get to work indexing my database! I will let you know what kind of results I get, sometime!
@Charles,
Woot woot, very exciting!
Great writeup Ben! I followed the same journey in my career in dealing with Databases. It is kind of a magic feeling when you have database that is constantly getting deadlocks and you clear it up with a couple of indexes. I wrote about my struggles back in 2012: Coping with deadlocks
@Tim,
Thank you for the kind words! It certainly is a journey. And, as much as I feel like I've learned, there is so much that I still don't have much of a clue about. Though, I am beginning to accept the fact that there are just going to be lots of things that I'll never have a clue about :D
Deadlocks, for example, may be one of those things. I understand deadlocks at a high-level; but, when I see them show up in the error logs, it never really know where to even start debugging. I'll take a look at your write-up - sounds like it's right up my alley!
@Ben,
I know the feeling! Keep in mind when you read my deadlock article, it is old, so the latest versions of MSSQL may have better ways to do it.
@Ben
Thanks for yet another thoughtful and educational post. You've demystified a few things I thought I knew. I'd always been told that a good rule of thumb was that indexes are a trade-off between optimizing for read -vs- write actions. If you're writing to a table more often than you read from it, then indexing may be bad because of the reshuffling that happens with every write operation. After reading your article, I have a better understanding why that's true. However, I had no idea about the concept of "leftmost prefix". I've been told that it's best to order your WHERE clauses from least specific to most specific. In your example "LastName" to "FirstName" for example, you might have many "Jones" (LastName), but fewer who also have the FirstName "Tim". I didn't realize it could have an impact on the query strategy though and just naively thought it was "best practice", which we often follow simply because, well, cargo cult.
I'm not sure I agree that moving the read-requirements to the JOIN, hence eliminating the WHERE clause, makes it "very easy to see which columns are required to calculate and then filter the cross-product". But maybe that's just because my mental model has always leaped to the WHERE clause for this and I just need to try to think about this differently. I am intrigued, so thanks for opening my eyes to a new way of seeing this.
Speaking of JOINS, I always wondered if it mattered whether I do this...
OR
Any thoughts on the order with which you join? Does it matter?
@Tim,
Ha ha, I liked this (from your article):
Good write-up. I'll have to look at the scripts you provided. I know they are MSSQL and I mostly work with MySQL; but, it sounds like there's some interesting introspection stuff in there.
@Chris,
The read vs. write volume can definitely impact the use of indexes, as you say, because data needs to be re-organized during write operation. That said, I think most (though not all) applications tend to be read-heavy, not write-heavy. As such, the use of indexes, despite the overhead, usually has a rather significant payoff.
Re: the
ORDER BYstuff, my knowledge is really shallow at that level. Essentially, the way that I understand it (which is hopefully accurate) is that the data gets loaded into the result-set in the same order as the indexes. So, if yourORDER BYuses the same column-based sort as the composite index, then there's essentially no subsequent ordering operation that the database needs to perform. Or, something like that ....The complexity with the ordering optimization is that I believe it has to be from the first table-reference down. Otherwise, you still end of sorting the result-set, even if your subsequent indexes (in a
JOINfor example) have an order that is desirable.Them more I try to describe it, the more I remember how little I understand about this part. If you are interested, the MySQL docs have a description:
https://dev.mysql.com/doc/refman/8.0/en/order-by-optimization.html
I just tried to read it and it made my head hurt :D
Re:
ON r.id = m.roleIDvs.ON m.roleID = r.id... it makes no difference to the database query optimizer. It still parses the query and then executes it in the same way. The only difference is one of human consumption. For me, I like to structure myJOINclauses such that items on the left are the "things I need" and the items on the right are the "things I have". So, in the case of yourJOIN, I would tend to go with the first one,ON r.id = m.roleID, because I havem.roleIDfrom the first table and I needr.idin the second table (ie, the one that is currently being processed in the cross-product.@All,
On Twitter, my co-worker, Ben Darfler, was saying that in at least one database, you can have multiple clustered-indexes per table. But, the cost of doing so is essentially a complete duplication of the data (since the clustering index determines the internal storage of the data). This isn't supported by MySQL or MSSQL.
Darfler mentioned it because in my article I essentially tread "primary key" and "clustered index" as synonymous. But, this may not always be true for all databases.
@All,
I wanted to share an idea that I've been kicking around for the past few months -- creating compound keys based on slow-changing hierarchical parent IDs:
www.bennadel.com/blog/3643-creating-a-composite-index-using-ancestral-keys-in-a-hierarchical-database-table-design.htm
The idea would be to create an index that includes all of the contextual IDs for the given record. This makes some of the queries more complex; but, would make many queries faster and more flexible. It's all about the trade-offs.
Good work, but very many words, and not so much sence. I think this article can confuse the topic for some newbies making it unclear.
@Dmitry,
Do you have any suggestions on how I could have made it more clear? It's a non-trivial topic to discuss. It's hard to take years of learning and condense it into a single article.
@All,
I just posted a related article that walks through index design for typical membership-style database tables:
www.bennadel.com/blog/3843-showing-the-affects-of-database-index-structure-on-membership-table-join-performance-in-mysql-5-6-37.htm
This looks at a table that represents a relationship between several other tables; and, how the common use-cases for such a table can be used to:
Drive the way you structure your actual SQL
INNER JOINstatements.Help you figure out what index design needs to be applied to said table.
Hopefully this fills in some of the details that may be missing from the current article.