
Using Derived Tables To Generate "Stats" For An Outer Query JOIN In MySQL 5.6.49
Most of the time, when writing SQL queries, I try to keep my queries as simple as possible. I find that this aids in both readability and performance. However, sometimes, the more complicated query is the best option. This is particularly true when writing reporting queries. And, one technique that I love - when it comes to reporting - is the use of derived tables to gather statistics that can then be re-joined to the outer query. I don't think I've ever written about this specifically; so, I just wanted to show a quick demo of this in MySQL 5.6.49.
A "derived table", in SQL, is a temporary data table that is created on-the-fly within the scope of a query as part of the SQL statement execution. We can give these derived tables a name. And then, we can INNER JOIN and LEFT OUTER JOIN the derived table back to the parent query using one of the columns in the derived table's SELECT.
So basically, a derived table is just like any other table; only, it is temporary. MySQL may even add indexes to a derived table as part of its performance optimization.
When it comes to reporting queries, that need to aggregate a bunch of data, a derived table can be used to hold some subset of data for later association. For example, imagine that I have a user table and an activity_log table and I want to look at the recent activity for the users. I could use a derived table to calculate activity_log aggregates; and then, INNER JOIN those aggregates back to my user table:
SELECT
( u.id ) AS user_id,
( u.name ) AS user_name,
-- Get activity logs stats for this user.
( activityLogStats.logCount ) AS log_count,
( activityLogStats.maxCreatedAt ) AS log_createdAt
FROM
user u
INNER JOIN
-- Create a derived table that contains statistics about log-activity for the set of
-- users in a way that we can JOIN to this table using the USER ID. This allows us to
-- calculate this data ONCE FOR THE QUERY rather than ONCE PER USER.
-- --
-- NOTE: In a production setting, I would almost certainly be limiting the scope of
-- derived table in some way, using an indexed value. Otherwise, this would be a
-- full-table scan, which would likely be catastrophic for performance.
(
SELECT
l.userID,
COUNT( * ) AS logCount,
MAX( l.createdAt ) AS maxCreatedAt
FROM
activity_log l
GROUP BY
l.userID
) AS activityLogStats
ON
activityLogStats.userID = u.id
ORDER BY
u.id ASC
;
This SQL query has two tables:
user- an existing table in our database schema.activityLogStats- a derived table that we're creating on-the-fly, based on the existingactivity_logtable.
In this case, the derived table is gathering activity-log statistic by grouping records on userID. We're then performing an INNER JOIN to the outer query on that userID column in order to find the recent activity for our set of users.
Now, if we run this MySQL query, we get the following outcome:
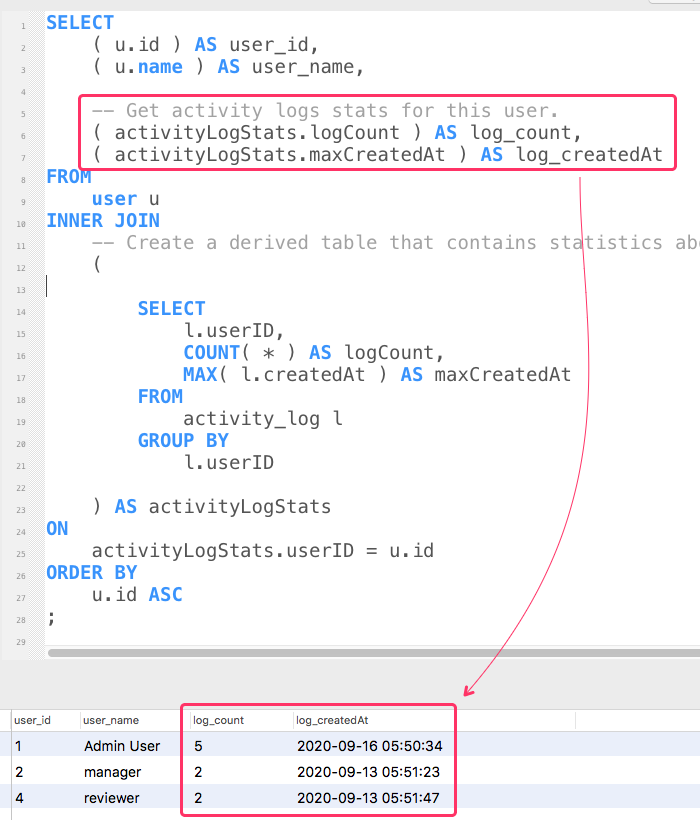
As you can see, for each of our user records, we were able to find both the number of activity_log records and the date of the most recent record using the user-based aggregates from the derived table.
In this demo, both the derived table and the outer table are unbounded. Meaning, we're basically doing full-table scans. For a demo, this is fine. But, in a production environment, this would likely be a catastrophic problem. In reality, I would be limiting the scope of both the outer query as well as the derived table.
Of course, the derived table cannot reference the outer query as part of its own calculation. So, it would need to be limited on its own, possibly using a cutoff-date or some sort of user-ID list (via an IN() clause). For example, I could limit this to the users within a given organization:
NOTE: The following SQL is not based on my actual database schema. As such, I have not executed it and it may contain syntax errors.
SELECT
( u.id ) AS user_id,
( u.name ) AS user_name,
-- Get activity logs stats for this user.
( activityLogStats.logCount ) AS log_count,
( activityLogStats.maxCreatedAt ) AS log_createdAt
FROM
organization_membership om
INNER JOIN
user u
ON
(
om.organizationID = 4 -- Limiting the outer-query based on organization.
AND
u.id = om.userID
)
INNER JOIN
(
SELECT
_l.userID,
COUNT( * ) AS logCount,
MAX( _l.createdAt ) AS maxCreatedAt
FROM
organization_membership _om
INNER JOIN
activity_log _l
ON
-- Notice that our derived table is both repeating the organization-based
-- filtering as well as adding additional filtering based on date (assumes
-- that the createdAt date is part of the indexing). This minimizes the
-- number of rows that have to be read in order to derive this table.
(
_om.organizationID = 4
AND
_l.userID = _om.userID
AND
_l.createdAt >= DATE_ADD( UTC_TIMESTAMP(), INTERVAL -30 DAY )
)
GROUP BY
_l.userID
) AS activityLogStats
ON
activityLogStats.userID = u.id
ORDER BY
u.id ASC
;
Since the derived table can't reference the u.id column from the outer table until after the derived table has been generated, we can't use the outer query to limit the scope of the derived query. As such, we have to repeat some of our filtering in both the outer query and the inner query. In this case, we using the organizationID value (4 in this case) in both queries. This allows us to limit the number of records that have to be read in order to generate the derived table.
Of course, this optimization depends on the fact that the limiting columns are part of a consumable index that prevents us from having to perform a full-table scan.
ASIDE: Sometimes I prefix my derived table aliases with an underscore (ex,
_om). I do this so that there is no confusion as to whether the alias is for a table reference within the sub-query for the parent query (which is not possible). This is just a personal preference for readability - not a technical requirement.
For the most part, I do try to keep my SQL queries as simple as possible, sometimes even moving INNER JOINs out of the database and into the application code. But, sometimes, a complex SQL query is the best option. In those cases, I often find that a derived table can be very helpful and surprisingly performant, especially when calculating stats about a subset of related records.
Want to use code from this post? Check out the license.

Reader Comments
Now that I'm running on MySQL 8, I'm starting to look at new features in the new version. And, as of MySQL 8.0.14, there's something called a
LATERALderived table:www.bennadel.com/blog/4222-using-lateral-derived-tables-to-gather-row-specific-aggregations-in-mysql-8-0-14.htm
This new syntax allows us to create derived tables that reference the rows in the outer table - something that has not been possible in the past. This can definitely reduce the complexity of the SQL statement.