
Replacing ColdFusion Query-of-Query (QoQ) INNER JOIN And LEFT OUTER JOIN With Array Functions In Lucee CFML 5.3.3.62
Earlier this week, I took a look through the InVision codebase, pulled-out several ColdFusion Query-of-Query (QoQ) examples, and then demonstrated how those query-of-queries could be re-implemented using Array functions in Lucee CFML. I wanted provide a quick follow-up post about re-implementing INNER JOIN and LEFT OUTER JOIN queries using Array functions in Lucee CFML 5.3.3.62.
With a JOIN query, you are matching the records in one recordset to the records in a second recordset using some sort of join condition (almost always consisting of a primary-key reference). In the database, this is an efficient operation because the columns in the join condition are - or should be - indexed. This allows the associated set of records to be located very quickly.
When we move the join operation into the ColdFusion application code, we can leverage the same principles. Which means, we have to create an "index" for the second recordset that we can use during the join operation. In the context of ColdFusion, this "index" can be nothing more than a Struct in which each Struct-key represents the look-up value for a cohesive set of records.
If you've ever used a client-side library like Underscore or Lodash, you're likely familiar with methods like _.indexBy and _.groupBy. That's exactly the same kind of method that we're going to implement in our Lucee CFML code:
<cfscript>
/**
* I return a Struct that groups the given collection based on the given key. Each
* key-value is an Array that contains all of the items that match the same key-
* value.
*
* CAUTION: Every item in the collection is ASSUMED to have a NON-NULL reference to
* the given key. This makes sense for an in-memory JOIN.
*
* @collection I am the Array of Structs being grouped.
* @key I am the key on which to group items in the collection.
*/
public struct function groupBy(
required array collection,
required string key
) {
var index = {};
for ( var item in collection ) {
var keyValue = item[ key ];
// This expression attempts to get the current group indexed by the given
// key-value. However, if it doesn't exist, we're using the "Elvis"
// operator to "Assign and Return" a new Grouping for this key-value.
var group = ( index[ keyValue ] ?: ( index[ keyValue ] = [] ) );
group.append( item );
}
return( index );
}
</cfscript>
As you can see, this User Defined Function (UDF) takes a collection (our recordset) and a key and then returns a Struct in which each key in the struct aggregates each record within the recordset that has the same key-value. Once we have this Struct, we can find associated records in constant-time.
With an index like this, we can then loop over one recordset and find all of the associated rows in the second recordset. To see this in action, I have created a demo that matches a collection of Friends to a collection of PhoneNumbers. As a first step in the algorithm, we index the Phone Numbers on the "friendID" key:
<cfscript>
friends = [
{ id: 1, name: "Kim", isBFF: true },
{ id: 2, name: "Hana", isBFF: false },
{ id: 3, name: "Libby", isBFF: false },
{ id: 4, name: "Dave", isBFF: true },
{ id: 5, name: "Ellen", isBFF: false },
{ id: 6, name: "Sam", isBFF: false }
];
phoneNumbers = [
{ id: 1, friendID: 1, phone: "555-1111", type: "mobile" },
{ id: 2, friendID: 6, phone: "555-6666", type: "home" },
{ id: 3, friendID: 3, phone: "555-3333", type: "home" },
{ id: 4, friendID: 1, phone: "555-1113", type: "pager" },
{ id: 5, friendID: 4, phone: "555-4444", type: "mobile" },
{ id: 6, friendID: 5, phone: "555-5555", type: "mobile" },
{ id: 7, friendID: 1, phone: "555-1112", type: "home" },
{ id: 8, friendID: 6, phone: "555-6667", type: "mobile" }
];
// When performing an INNER JOIN in SQL, the ON clause should always reference an
// indexed column in the secondary table such that the associated records can be
// looked-up without a full-table scan. When performing a JOIN in the application,
// the same exact principle applies. Before executing the JOIN, we have to create an
// index for the secondary collection that allows the cross-product to be calculated
// efficiently. In this case, we're going to group the phoneNumbers by "friendID".
phoneNumberIndex = groupBy( phoneNumbers, "friendID" );
// Now that we have our index in place for the secondary collection, all we have to
// do is map over the primary collection and find the associated INDEXED VALUE.
results = friends.map(
( friend ) => {
return({
friend: friend,
phoneNumbers: ( phoneNumberIndex[ friend.id ] ?: [] )
});
}
);
// NOTE: Technically, the above JOIN would be a LEFT OUTER JOIN since we keep the
// friend record even if there are no associated phoneNumber records. If we wanted to
// truly create the equivalent of an INNER JOIN, we've have to filter-out non-
// matching cross-products.
// --
/*
results = results.filter(
( result ) => {
return( result.phoneNumbers.len() );
}
);
*/
dump( results );
// ------------------------------------------------------------------------------- //
// ------------------------------------------------------------------------------- //
/**
* I return a Struct that groups the given collection based on the given key. Each
* key-value is an Array that contains all of the items that match the same key-
* value.
*
* CAUTION: Every item in the collection is ASSUMED to have a NON-NULL reference to
* the given key. This makes sense for an in-memory JOIN.
*
* @collection I am the Array of Structs being grouped.
* @key I am the key on which to group items in the collection.
*/
public struct function groupBy(
required array collection,
required string key
) {
var index = {};
for ( var item in collection ) {
var keyValue = item[ key ];
// This expression attempts to get the current group indexed by the given
// key-value. However, if it doesn't exist, we're using the "Elvis"
// operator to "Assign and Return" a new Grouping for this key-value.
var group = ( index[ keyValue ] ?: ( index[ keyValue ] = [] ) );
group.append( item );
}
return( index );
}
</cfscript>
As you can see, once we index the Phone Numbers by "friendID", all we have to do is loop over the Friends collection and then, for each friend, look up the associated phone numbers based on the index value. And, when we run the above ColdFusion code, we get the following output:
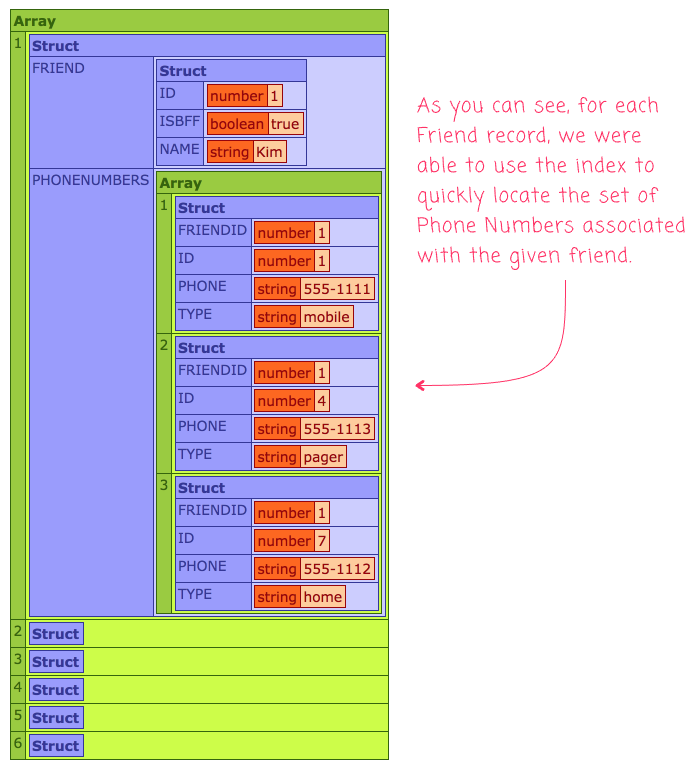
As you can see, our .map() call created a new Array of Structs in reference the Friend item and the collection of associated Phone Number items.
Now, technically, this code is implementing a LEFT OUTER JOIN since we return a cross-product even if there are no associated Phone Numbers. If we truly wanted to make this is an INNER JOIN, we'd have to filter-out the cross-product items in which there were no associated Phone Numbers:
<cfscript>
// ....
// To implement a true INNER JOIN, we would have to filter-in only those
// records in which each Friend had at least one associated Phone Number.
results = results.filter(
( result ) => {
return( result.phoneNumbers.len() );
}
);
// ....
</cfscript>
This is a technique that I use all the time at InVision. For me, this has less to do with replacing ColdFusion Query-of-Queries (QoQ) and more to do with moving processing demand out of the Database and into the Application tier. For our architecture, we have way more cumulative CPU power in the horizontally-scaled Application tier than we do in the Database. As such, moving things like INNER JOIN, ORDER BY, and UNION ALL out of the database means that we can shift demand to a more scalable set of CPUs.
ASIDE: I am not trying to say that all of these queries make sense in the Application tier. After all, the database was designed for this kind of processing power. However, I have found that moving some "hot" query operations into the application can simplify the queries and make them faster. Especially when one portion of the records has more relaxed "staleness" requirements and can be read from a different data-source (or even a Cache).
There's no arguing with the simplicity of the ColdFusion Query-of-Query (QoQ) syntax. Clearly, using a single INNER JOIN is less code than manually creating an index and then finding associated values. But, the explicit code is [almost certainly] faster and more flexible.
Want to use code from this post? Check out the license.

Reader Comments
@All,
A couple of people on Twitter asked me about the relative performance of ColdFusion Query-of-Queries and Array-based data collation. To be clear, both options are fast; but, Array-based methods are faster. In most context, there is not going to be any pragmatic difference. However, when trying to optimize a hot pathway that has been measured to be a performance bottleneck, it could be a viable optimization:
www.bennadel.com/blog/3717-superficial-performance-comparison-between-coldfusion-query-of-queries-qoq-and-array-functions-in-lucee-cfml-5-3-3-62.htm
Take this performance test with a grain of salt, as you should any other performance comparison.
Hi Ben
This is really great. It's just I got different results.
I actually used JavaScript, because I wanted to see the results on my iPhone.
So, I changed your function to:
I got 3 phone numbers for Kim, 2 for Sam & 1 for everyone else except for Hanna.
Your dump seems to show empty Structs for everyone except for Kim?
I really liked this part:
The way you are assigning from the right to the left!
I had to look at this a few times, before the penny dropped!
This is the kind of stuff, that sets your code apart from the rest!
Because another more long winded way of doing it, using my JavaScript version is:
Or, using CF:
But I love the simplicity of your version and the way you use the amazing Elvis operator.
Interestingly, JavaScript does not have an Elvis operator! Which is why TypeScript doesn't have one either!
@Charles,
In the screenshot, I was just collapsing the other Struct instances so they didn't take up as much room. Sorry, I should have mentioned that in the write-up.
JavaScript doesn't have the Elvis operator; but, it does sort-of allow for the same type of operation using the
||(OR) operator. For example you could have something like this:Here we're basically doing the same thing. Essentially saying set
grouptoindex.test; however, if that is Falsy, then setgroupto the result of the assignment,index.test=[].And Yes, you are correct in your long-form version of these. It's basically just a short-form for an IF/ELSE statement. I actually debated on whether or not to use it. In the end, I decided to proceed with the usage; but, you can see that I added a hefty comment to the code so that it would attempt to explain what was going on.
The rationale behind my choice was an attempt to limit the number of
index[ keyValue ]calls. As you can see, in the long-form, you have to evaluateindex[ keyValue ]a max of 3-times. In my version, it is only evaluated twice. This is just a micro-optimization; but, I figured since it was in a "utility" method, then it might be worth it.It's cool how you create an array at the same time as you assign to the Struct key.
I don't think I have ever seen this before.
It's like killing two birds with one stone, although I don't condone violence to animals, in any way!
I will try and use this kind of thing in my own code from now on.
Once again, thanks for your inspiration...
@Charles,
My pleasure! Sometimes, it's a fine-line between "clever code" and "hard to read code". So, use this is caution, I would say. I find that I use this most when I am setting a key into some sort of Struct / Object. You can even do this in something like a
returnstatement, which is often times how I'll populate a cache:Usually, I find this is best used in code that changes infrequently, so people don't have to read it much. But, it's a fun thing to use.
Nice work Ben. We've also been working to move some code to the application layer as we've got load-balanced instances that have 'cooler' cpu's than our db...
trying to cache and use memory as much as possible also for performance, so this snippet just found a home in the 'diimes' cf framework code :-)