
You Can Reference Your Derived SELECT Columns In Your ORDER BY Clause In SQL
Sometimes, nothing gets me more excited than a well-crafted SQL statement (what can I say, I'm a cheap date). I also love cleaning up and [hopefully] optimizing queries. One thing that I see from time-to-time is someone executing duplicate calculations (typically aggregates such at COUNT) in both the SELECT and the ORDER BY clauses. Typically, this isn't necessary as you can run the calculation once in your SELECT statement and then reference said derived value directly in your ORDER BY.
When a SQL query executes, the SELECT clause is executed after the FROM / WHERE clauses, but before the ORDER BY clause. This means that by the time the ORDER BY clause is executed, any derived or calculated columns in the SELECT statement are available in the ORDER BY. To demonstrate, take a look at this code:
<!--- Reset our test data. --->
<cfquery name="reset" datasource="testing">
TRUNCATE TABLE friend;
INSERT INTO friend
(
id,
name
)
( SELECT 1, 'Tricia' ) UNION ALL
( SELECT 2, 'Joanna' ) UNION ALL
( SELECT 3, 'Sarah' ) UNION ALL
( SELECT 4, 'Kim' ) UNION ALL
( SELECT 5, 'Amanda' ) UNION ALL
( SELECT 6, 'Julie' );
</cfquery>
<!--- Query for a sub-set of friends. --->
<cfquery name="friends" datasource="testing">
SELECT
id,
name,
<!---
This is a trite example, but let's assume this is a somewhat complicated
formula for each row, perhaps event an aggregate or a SUB-SELECT that has
to run a separate query for each matched record.
--->
IF( id IN ( 3, 4 ), 1, 0 ) AS isCloseFriend
FROM
friend f
WHERE
f.id < 5
ORDER BY
<!---
We can reference the calculated column defined in the SELECT when executing
the ORDER BY of the resultant set.
--->
isCloseFriend DESC,
f.name ASC
</cfquery>
<!--- Output the results. --->
<cfdump
var="#friends#"
label="friends"
/>
This example is silly; but, I'm sure you can imagine a more relevant example such a GROUP BY aggregate value or a sub-select. That said, notice that the "isCloseFriend" column, derived in the SELECT statement, is being used to order the overall result-set in the ORDER BY clause. And when we run this query, we get the following CFDump output:
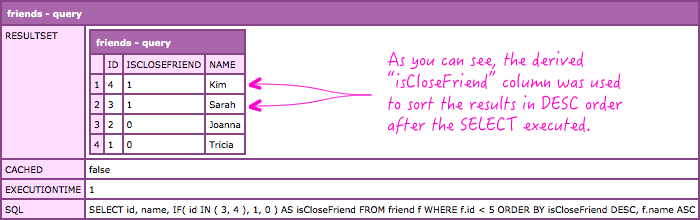
Works like a charm!
The beauty of this SQL feature is that you can cut down on processing and the duplication of logic. And, from a personal standpoint, I think this makes the SQL query easier to read as your ORDER BY now contains meaningful names rather than complex calculations.
Want to use code from this post? Check out the license.

Reader Comments
Hey Ben,
Cool tip. Just a tip for the tipper. When you are doing SQL examples, it is usually better just to use temp tables so we can easily drop it in and run.
<cfquery name="friends" datasource="testing">
(SELECT 1 AS id, 'Tricia' AS name INTO #TEMP ) UNION ALL
( SELECT 2, 'Joanna' ) UNION ALL
( SELECT 3, 'Sarah' ) UNION ALL
( SELECT 4, 'Kim' ) UNION ALL
( SELECT 5, 'Amanda' ) UNION ALL
( SELECT 6, 'Julie' );
SELECT
id,
name,
--
-- This is a trite example, but let's assume this is a somewhat complicated
-- formula for each row, perhaps event an aggregate or a SUB-SELECT that has
-- to run a separate query for each matched record.
--
IF( id IN ( 3, 4 ), 1, 0 ) AS isCloseFriend -- mysql
-- CASE WHEN id IN ( 3, 4 ) THEN 1 ELSE 0 END AS isCloseFriend --sqlserver
FROM
#TEMP f
WHERE
f.id < 5
ORDER BY
--
-- We can reference the calculated column defined in the SELECT when executing
-- the ORDER BY of the resultant set.
--
isCloseFriend DESC,
f.name ASC;
DROP TABLE #temp
</cfquery>
Note that not all SQL platforms support using the column alias in the ORDER BY -- E.G. -- PostgreSQL does!, DB2 does not :(
However nearly ALL allow you to refer to the column ordinal position instead. So you example could also be expressed as:
ORDER BY
3 DESC
f.name ASC
"3" being the column that is the third position of the result set --- AKA isCloseFriend
FYI: You need to be sure to add a big comment near the query to let the next developer who comes along to either only add result columns to the end of the list or to fix the ORDER BY...
Another fun trick to wrap the entire query in an outer SELECT so that you can refer to the column aliases by name.
EX:
SELECT
t1.id
,t1.name
,t1.isCloseFriend
FROM
(
YOUR EXAMPLE QUERY HERE
) AS t1
ORDER BY
t1.isCloseFriend DESC
,t1.name ASC
Also no hating on the leading commas. :)
@Justin,
I like that idea. I used to use "table variables" when I was in MS SQL Server; but, when I moved to MySQL, they don't have the same concept. I've done a little bit of reading about the temp table stuff. It seems like they are "session specific", but I never quite know how that works with JDBC connection pooling.
Does the "#" in table name have a significance?
@J,
I don't have any practical experience with DB2 or PostgreSQL, but I hear people rave about Postgress. It even has native JSON data types these days, probably trying to bridge some of the NoSQL functionality. Thanks for bringing the differences up; I didn't know that this wasn't part of the core SQL support.
It's funny that you mention the numeric reference to columns. I say that because I was thinking about writing a blog post about using "SELECT 1" as sub-select statement with things like:
```sql
WHERE
NOT EXISTS (
SELECT 1 FROM .... and so on
)
```
The idea being that the "1" is meant to indicate that you don't care which data is returned, only that _something_ is returned. In MySQL and SQL Server, this just returns the literal "1"; but, I'm wondering if other database may return the first column value.
@Ben -- Correct - Literals in the SELECT clause are treated as such -- I am not aware of any database that claims to be SQL compliant that would not follw that behaviour.
You should consider giving a few or the scaler functions some air time -- my current favorite COALESCE(col1,col2,col3,...). It returns the first non NULL value out of all the columns passed in.
Example of use: Planned vs Actual time -- the actual would be NULL until the event occurred -- but you need to show the event on a timeline in advance too -- so return the time column like: COALESCE( actualTime, plannedTime ) AS eventTime.
You get a time result that you don't need to evaluate in app code.
Ben,
Temp tables are specific to the connection session. That means that care must be used to determine if they exist and manage their existence. Typically, we build and drop the temp table, using it much like a "variable" inside a single cfquery. Table variables and temp tables share a lot of similar behavior, but there is a huge difference when it comes to parsing and executing the SQL. It's very situational, but temp tables, in general, are good for tables with more than a few dozen rows. In addition, you can create indexes on temp tables just like a regular table. Table variables in sql server could get just a single clustered index.
# tells the database server that you are going to use tempdb for this table. Without it, you are just using the current database and creating a normal table.
Finally, double ## indicate a global temp table that all DB sessions can access. Obviously, it's just another tool that might be a life saver or something you never use.
@Ben,
In regards to temp tables and connection pooling -- with both DB2 and PostgreSQL on session based temp tables ( they ones most people think of ) -- as CF will try to round-robin the connection pool to the general extent a second cf query will often fail if you refer to the temp table ( not always as you MIGHT get lucky enough to get dropped back into the same cfquery session as when you defined it ).
To guarantee that you get the same session just wrap all the cfquery tags that refer to that temp table in a cftransaction. Also note that if you have the maintain connections box checked in CFADMIN for the datasource be sure to DROP the temp table when you are done ( still in the cftransaction ).
Otherwise you are chewing up memory until CF decides to end that session -- and you could easily try to create the same temp table later and hit the same session and get a query error since the temp table would still exist.