
Irrational Guilt Over Using ORDER BY id In My ColdFusion SQL Queries
Most of the relational database tables that I create in my ColdFusion applications have an AUTO_INCREMENT primary key, id, and some sort of createdAt date/time column. The nature of the primary key along with the nature of a timestamp means that both of these columns "increase" at the same time. Which means that - in almost all cases - I can use the id to sort the query results in chronological order. But, I have a lot of irrational guilt over doing this since the id column is not semantically the same as the createAt column. But, this guilt is stupid; and succumbing to it would actually lead to worse performance in my ColdFusion and MySQL applications.
To get a sense of what kind of database schema I'm talking about, consider the following CREATE TABLE statement:
CREATE TABLE `doc` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT,
`userID` int(10) unsigned NOT NULL,
`name` varchar(255) NOT NULL,
`createdAt` datetime NOT NULL,
PRIMARY KEY (`id`),
KEY `IX_byUser` (`userID`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
As you can see, I have an id column (an auto-incrementing integer) and a createAt column. As the ColdFusion application consumes this table, all INSERT operations will include a createdAt value that represents the current moment-in-time. As such, this value will never get smaller - it will only ever increase (or stay the same depending on the volume of operations per second).
To drive home the point: Both the id and createdAt columns will only ever increase over time - they will never decrease. As such, the id value can be a rough stand-in for the createdAt value in terms of sorting.
To see why this is actually good for performance, let's throw some test data into this table. In the following ColdFusion code, I'm just going to execute 5,000 INSERT statements, each with a createdAt date on a unique day (to keep things simple):
<cfscript>
// Increase the page-request timeout so that our 5,000 queries have time to run.
cfsetting( requestTimeout = 300 );
for ( i = 1 ; i <= 5000 ; i++ ) {
userID = randRange( 1, 100 );
name = "Doc for user #userID#, v#createUuid()#";
// NOTE: For the sake of the demo data, we want to the DATE and the PKEY to
// increment in lock-step. This is how the data would work normally; but, since
// we're populating the demo data programmatically, we have to force the
// synchronicity a bit.
createdAt = createDate( 1990, 1, 1 )
.add( "d", i )
;
createDoc( userID, name, createdAt );
}
// ------------------------------------------------------------------------------- //
// ------------------------------------------------------------------------------- //
/**
* I create a record in the doc table using the given properties.
*/
public void function createDoc(
required numeric userID,
required string name,
required date createdAt
) {
queryExecute(
"
INSERT INTO
doc
SET
userID = :userID,
name = :name,
createdAt = :createdAt
;
",
{
userID: {
value: userID,
cfsqltype: "cf_sql_bigint"
},
name: {
value: name,
cfsqltype: "cf_sql_varchar"
},
createdAt: {
value: createdAt,
cfsqltype: "cf_sql_timestamp"
}
}
);
}
</cfscript>
As you can see, both the id and the createdAt columns are increasing by 1 on each loop. The id column does this because that's what an AUTO_INCREMENT column does; and, the createdAt column does this because I'm using the for-loop iteration index in a dateAdd() call.
ORDER BY id and ORDER BY createdAt are Essentially the Same
To demonstrate that I can use either the id column or the createdAt column in an ORDER BY clause to achieve the same results, let's grab all the documents for a given user and order them in chronological order:
<cfscript>
idLists = {
"id": "",
"createdAt": ""
};
// Iterate over each COLUMN to run the same query using a different ORDER BY clause.
for ( orderByColumn in idLists ) {
results = queryExecute("
SELECT
*
FROM
doc
WHERE
userID = 4
ORDER BY
#orderByColumn# ASC
");
// Get the list of IDs from this query.
idLists[ orderByColumn ] = valueList( results.id );
}
// Now that we've run the query twice, once with ORDER BY id and once with ORDER BY
// createdAt, let's compare the two lists of ids.
writeOutput(
"Same ID list: " &
yesNoFormat( idLists.id == idLists.createdAt )
);
</cfscript>
This ColdFusion code runs the same query twice, but with different ORDER BY clauses:
ORDER BY id ASCORDER BY createdAt ASC
Then, it pulls out the values from the id column and compares them:
Same ID list: Yes
As you can see, both ORDER BY clauses result in the same set of results order in the same way. Because, again, id can act as a rough stand-in for the createdAt when it comes to ordering rows.
ORDER BY id is Better for ColdFusion Application Performance
Ok, now let's talk performance; and, why using ORDER BY id has a positive affect on your ColdFusion application performance. If you recall from my post on the dark art of database indexing, all secondary indexes on a relational database table implicitly include the primary key for that table at the end of each index entry. Which means that the secondary index on our doc table:
KEY `IX_byUser` (`userID`) USING BTREE
... is actually using this under the hood:
KEY `IX_byUser` (`userID`,`id`) USING BTREE
Only, the id portion doesn't need to be explicitly defined because it's inherent to the way secondary indexes work. A secondary index doesn't actually point to the row - it points to the primary key which, in turn, points to the row.
The other thing to know about secondary indexes is that they are stored in sort-order. And, when you perform a SQL query using a secondary index, the rows are returned in that same sort order.
This behavior applies to the prefix-consumption of the secondary index. Imagine that you have a secondary index with the following columns:
A,B,C,D [,pkey]
If you execute a SQL query with a WHERE condition that uses columns A and B for filtering, the rows will come back naturally with the ascending sort order of the next column, C.
If you execute a SQL query that uses all of the columns in the secondary index, A, B, C, and D, the rows will come back naturally with the ascending sort order of the next column, which is implicitly the primary key.
So, for our demo with the secondary index on the userID column, a WHERE clause that uses the userID will inherently return the results using the ascending sort order of the id column, which is our primary key. And, since id is a rough stand-in for createdAt in this case, we actually wouldn't need to order the query at all if we wanted to return the results in chronological order.
And, this actually changes the query execution plan! To see what I mean, let's run an EXPLAIN on selecting documents for a given user (4), but using the different ORDER BY clauses:
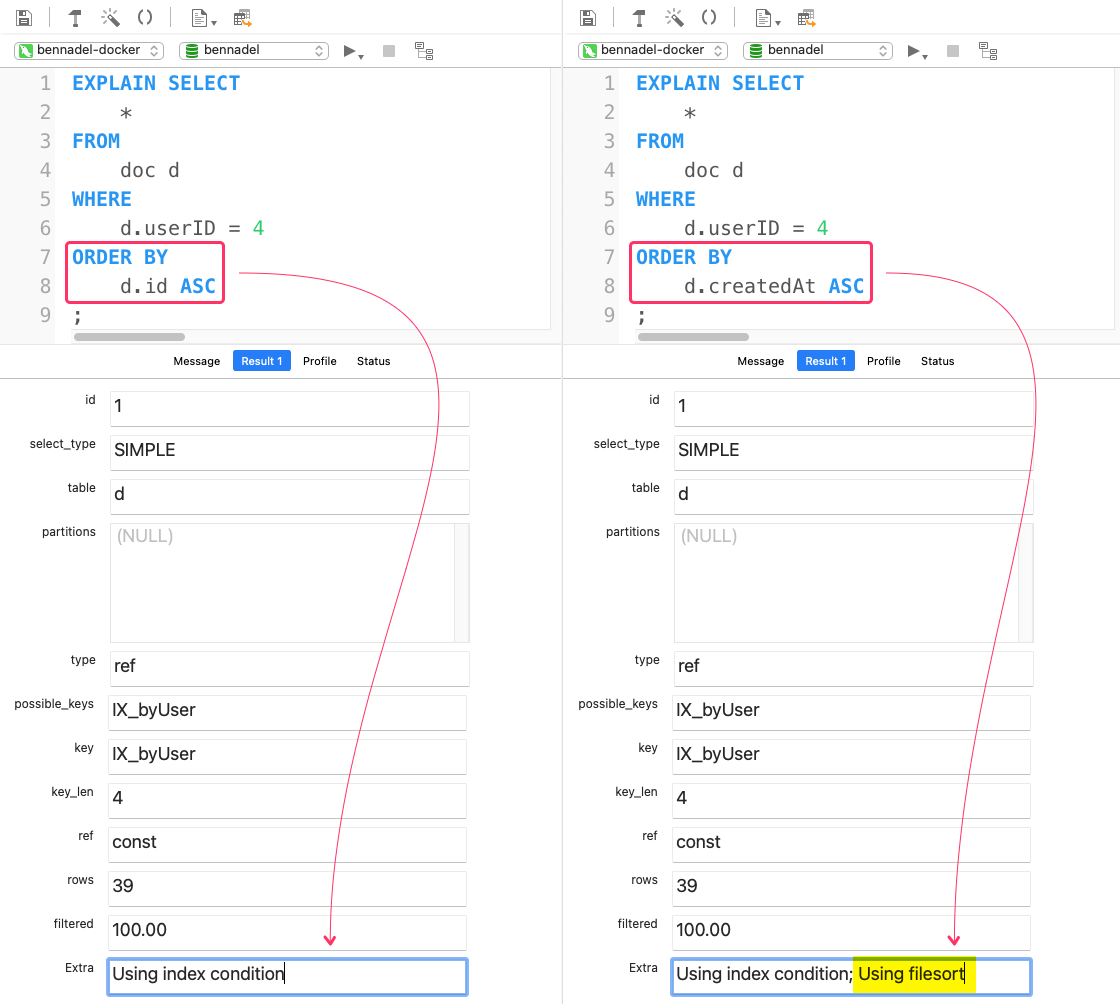
As you can see here, when we ORDER BY id, the SQL query execution is able to sort the query using the index alone. However, when we ORDER BY createdAt, the SQL query execution has to use an additional filesort in order to return the records in the requested order.
And, since id is a rough stand-in for createdAt when it comes to sorting, the latter query is doing more work for no reason - both queries result in the same exact data.
Of course, the huge caveat here is that in order to leverage the stored sort of the implicit id column on the secondary index, you have to consume all of the columns in the secondary index. Meaning, if our IX_byUser index was actually defined using the name column as well:
KEY `IX_byUser` (`userID`,`name`) USING BTREE
... then both of our EXPLAIN outcomes above would have included a filesort. And both queries would have had the same performance characteristics.
In total, what this means is that at worst (depending on the indexes) ORDER BY id and ORDER BY createdAt have the same performance. But, at best (depending on the indexes an our queries) we can bring back the records in chronological order (ascending or descending) with better performance when using ORDER BY id.
In other words, it's always better to use ORDER BY id because, at least sometimes, it has better performance. And, I'm done feeling guilty about using the id column in this manner.
If You Don't Use an Incrementing Primary Key
This whole post applies to a situation in which you have a primary key what is incrementing / increasing monotonically. If you don't have that in your database table - such as when using a UUID as the primary key - then this post doesn't apply to you.
It's Not Premature Optimization, It's How Databases Work
It would be easy to look at this post and claim that using id instead of createdAt is a case of premature optimization; but, I would push back against that notion. Everything about how we structure the database is geared towards performance. From normalization to secondary indexes - it's all about performance; and how we organize our data in a way that balances performance and usability. If you think using id is premature, then you might as well say that using secondary indexes is premature as well since you can pull back data without them.
Want to use code from this post? Check out the license.

Reader Comments
I always learn so much about how databases work from your posts. It is by far the most opaque technically I work with regularly...and I appreciate you pulling back the curtain for me every once in a while. I need a master's course in
EXPLAIN@Chris,
I'm so happy you find this stuff interesting - you are likely in the small minority of people 😆😆😆 But yeah, it took me years to start to feel really comfortable with relational databases. And, I'm still learning - and there's still so much stuff that I don't know. Even with
EXPLAIN, I only vaguely know what I'm talking about.When I talk to the people on our data-services team, I feel like I'm speaking a different language. They start talking about "bin logs" and "change data capture" and I'm like wat?! 😮
Just taking it a day at a time.
Why not use an index on the
createdAtcolumn?@Nanos,
It's a good question - and something I didn't really touch-on in the post. At a high-level, yes, adding
createdAtto the existing index would achieve the same performance (since the secondary index is stored in sort-order).But, indexed are not free. They have storage costs and performance costs when it comes to maintaining them over time. So, if all you were doing was adding
createdAtto get the sort to be faster, then you've incurred that cost for no real benefit since you can get the sort of theidanyway.That said, if you need to search on the
createdAtdate, then that's a different story - in the case, adding thecreatedAtdate to the index could be beneficial, assuming that you're first limiting the query byuserIDsuch that thecreatedAtcolumn is the next column in the secondary index:Of course, if you were less concerned with the "last 30 days" and would be OK with just "recent" documents, then you could do something like:
... where you can leverage the primary key for the sorting without incurring any performance penalty or having to index the
createdAtcolumn.Ultimately, this is all more art than science; and every app is different and every View has different requirements. It's super subjective - I really only intended to alleviate my own guilt on the matter 🤪 Your mileage will definitely vary.
@Ben,
Yeah makes sense. In my case, I almost always need to be able to search by date, so I often end up adding an index on that column. But if you don't need that then you certainly have a point...
@Nanos,
Yeah, exactly - every app is different. I'm sure I actually do end up search by date more often than I realize. Or, even if it's not in the Product UI, there's always some back-end report that I need to generate for the Sales or Customer Success team. But, for those one-off things, if I can narrow the records based on an indexed value, the additional filtering on date - even when not indexed - is usually pretty fast.... But, not always. More art than science. 🤓