
Considering Strategies For Idempotency Without Distributed Locking With Ben Darfler
Historically, I've used distributed locking (powered by Redis) as a means to create synchronization around business logic that enforces constraints across multiple resource representations. And to be fair, this has worked out fairly well. But, distributed locking is not without its downsides. As Martin Kleppmann discusses in his book, Designing Data-Intensive Applications, distributed locks reduce throughput, increase complexity, and are really hard to get "right" anyway. As such, I've been thinking about how to implement idempotent application workflows without the use of distributed locks.
Loosely speaking, in a web application, an idempotent action is one that can be safely executed against the application multiple times without producing an undesired result. This doesn't mean that each subsequent action will necessarily be accepted - in fact, it may very well be rejected. But, an "idempotent action" implies that it is safe for a consumer to try and run the action against the application multiple times, even in parallel.
From the consumer's point of view, a distributed locking strategy is intended to create idempotent processing around a request. So, when we talk about removing distributed locks, we're not really changing the way the application works in any fundamental way; rather, we're changing an implementation detail, behind the curtain of encapsulation, that makes the request processing safer and potentially more efficient.
Since I'm relatively new to the concept of idempotent processing, I asked Ben Darfler - one of our lead software architects here at InVision - to sit down with me and walk through some real-world examples. And, what better set of real-world examples could there be than the distributed locking we use right here in our InVision App platform! The following is a selection of the more interesting workflows that we discussed; and, the general strategy we could use to remove a given distributed lock.
In each of the discussed workflows at InVision, the distributed lock was put in place to perform one (or both) of the following duties:
- Enforce a constraint across multiple resources.
- Reduce processing demands on the server.
For the latter, consider something like generating a PDF document, resizing an image, or performing an rdiff between two binaries. In such cases, a distributed lock was used to ensure that parallel requests for the same action would "fail fast", reducing load on the server. When we move to implement idempotency without distributed locks, we are, to some degree, dismissing this requirement out of hand. We're embracing the idea that processing power is cheap, especially at scale; and, if a server has to perform redundant processing in certain edge-cases, then so be it.
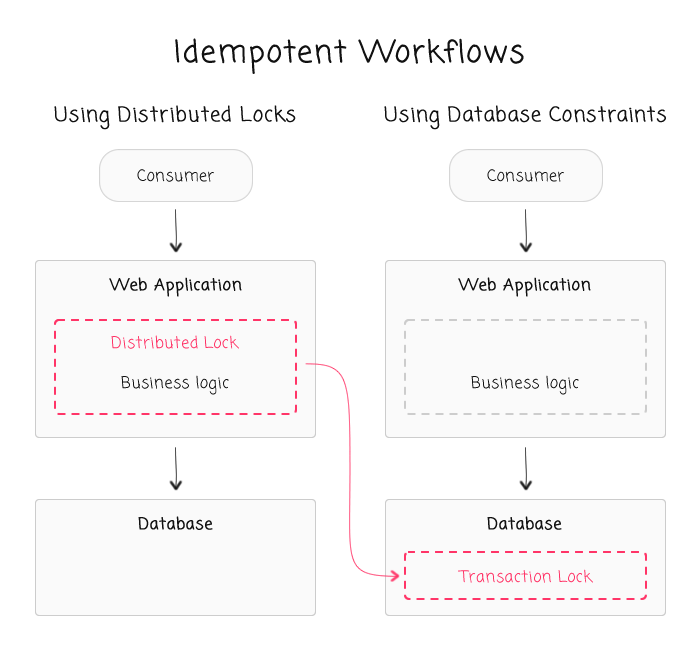
As such, our thought experiment becomes primarily concerned with enforcing constraints across multiple resources. And, without a distributed lock, this still need to be done - constraints still need to be enforced and invariants still need to hold true. In order to do this, we're moving the implementation of our constraints out of the business logic and into the database abstraction.
| |
|
|
||
| |
 |
|
||
| |
|
|
With this approach, we're leaning heavily on the database's ability to enforce constraints with some sort of a unique index. This means that we often have to re-think the way that we're storing data in order to make such a unique index possible while still allowing for the application to be feature-rich and flexible.
Now, to be clear, leaning on the database for these constraints is most certainly a calculated trade-off. After this is done, portions of the business logic will no longer be manifested directly in the code. This makes the totality of the business rules harder to see, understand, and maintain. But, this is done in order to create safer, more consistent code that fosters greater request-throughput.
NOTE: For the following, assume that we're using MySQL, which I'm told lacks some of the more advanced indexing functionality of something like PostgreSQL.
Workflow: Creating A Project
Business rules and considerations:
- Projects must be uniquely named under a given owner.
- Projects can be archived / deactivated.
- Projects can be flagged as over-quota based on the owner's subscription level.
In order to enforce the uniqueness constraint on the project name, we can create a unique composite index on "(userID,name)" (using a case-insensitive collation). However, when a project is archived, we no longer want its name to participate in the constraint. And, since we can have multiple projects archived with the same name, adding an "isArchived" flag to the composite index doesn't help us. As such, we have to physically move archived projects to a different table where there is no uniqueness constraint on the name.
This leaves us with two tables, "project" and "project_archive", in which the former holds all of the active records that adhere to the constraint; and, the latter holds all of the archived records that are unbounded. In addition to letting us move the name-constraint out of the code and into the data-layer, this two-table approach has the added bonus of [generally] keeping our working dataset and our indices smaller. This should require fewer database resources and make our queries faster and more efficient.
When it comes to applying the quota logic, here's where I think there's a great lesson to be learned about how we understand business requirements. As Martin Kleppmann explains in his book (Data-Intensive Applications), most requirements aren't nearly as strong as we make them out to be. For example, is it absolutely critical that the "isOverQuota" flag be applied to the new "project" record at creation time? Or, is it OK to apply it right after? Or, is it even OK to make it "eventually consistent" with the business rules?
In many business contexts, it is actually acceptable to temporarily violate a constraint and fix it up later by apologizing. The cost of apology (in terms of money or reputation) varies, but it is often quite low; you can't unsend an email, but you can send a follow-up email with a correction. If you accidentally charge a credit card twice, you can refund one of the charges and the cost to you is just the processing fee and perhaps a customer complaint. Once money has been paid out of an ATM, you can't directly get it back, although in principle you can send debt collectors to recover the money if the account was overdrawn and the customer won't way it back.
Whether the cost of apology is acceptable is a business decision. If it is acceptable, the traditional model of checking all constraints before even writing data is unnecessarily restrictive, and a linearizable constraint is not needed. It may well be a reasonable choice to go ahead and write optimistically, and to check the constraint after the fact. You can still ensure that the validation occurs before doing things that would be expensive to recover from, but that doesn't imply you must do the validation before you even write data. (Designing Data-Intensive Applications, Page 778, iBooks)
I, for one, want to learn how to embrace this more open-minded approach to consistency. So, for applying the "isOverQuota" flag to the "project" record, I would simply default the project to "under quota" (fail "safe"); then, go about recalculating the quotas across the entire set of projects owned by the user. The benefit of this approach is that the quota logic can be centralized and applied after all kinds of actions, such as project-deleting, project-archiving, project-activation, subscription-changes, etc.
As far as the logic involved in actually calculating and applying the quotas, I would calculate the set of projects that should be flagged as over-quota. Then, I would reset all the flags (for the given user) to "false", and go about setting the selected project records to "true." There is room here for a race-condition. But, since the quotas are being recalculated after many actions, any inconsistencies should fix themselves over time. And, if these inconsistencies become problematic, we can always create a background-task that double-checks quota adherence for recently mutated accounts.
NOTE: It is healthy to remember that we are talking about edge-cases when it comes to race-conditions.
Workflow: Activating A Project
Business rules and considerations:
- Projects must be uniquely named under a given owner.
- Activating a project should not violate unieness constraint.
- Projects can be flagged as over-quota based on the owner's subscription level.
Activating an old project is not that different from creating a new project. As such, we'll borrow heavily from the approach outlined above. The only real variation here is that we don't want to "fail" on violation of the unique name contraint (ie, the project-being-activated conflicts with an already-active project); instead, we want to automatically rename the activating project such that it becomes unique. For example, if there is an active project called, "Email Campaign", which conflicts with the activating project, we'll rename the activating project to be, "Email Campaign (Copy 1)".
Of course, there may already be an active project with the name, "Email Campaign (Copy 1)". So, what we end up with is a while-loop and a try-catch block that attempts to move the "project_archive" record over to the "project" table, catching and retrying any naming conflicts:
- Try to move record to active table.
- If it fails, increment "(Copy ${N})" token in on-the-fly name change and try again.
- If it works, proceed to quota-calculations.
Aside from this project-renaming, I think this workflow would be more or less the same as the create-project workflow. Once the record is moved from the "project_archive" table to the active "project" table, we would go about calling the centralized quota-calculation subroutine.
Workflow: Deleting A Project (And All Of Its Children)
Business rules and considerations:
- Deletions must be logged.
- All records that reside under a given project must also be deleted.
- Projects can be flagged as over-quota based on the owner's subscription level.
On its own, a deletion is naturally idempotent because you can't delete the same record twice. However, in this case, we're not just deleting a single record - we're logging the deletion and performing a cascading delete on related entities. As such, I think there's some interesting aspects to consider in this workflow.
For the "project" table itself, we don't have to do anything special. And, for the "project_delete_log" audit table, I am not sure we actually want to create a constraint. I would definitely create an index on "projectID"; but, I don't think we would want to make the index unique. After all, the goal of the "audit" table is provide a record of intent, not necessarily a record of the physical row deletion.
The cascading delete then becomes the most interesting part of this workflow. For one, we don't want the end-user to wait around for the cascading delete to finish. And two, we need to make sure the cascading delete can be run multiple times in case it fails mid-execution (which could happen for any number of reasons). In essence, the cascading delete has to become its own idempotent workflow.
To do this, we have to "queue up" the cascading delete somewhere. Perhaps in another database table; perhaps in a message queue; somewhere that can be asynchronously consumed by a worker thread. And, in order to make sure that we don't end up with orphaned records (since this would likely violate our terms-of-service regarding intellectual property), I would create a workflow in which this queuing action is attempted before the "project" record is deleted:
- Log deletion request (no constraints).
- Queue deletion request (fail loudly on inability to queue).
- Delete "project" record.
- Call quota-adjustment centralized subroutine.
Here, we make sure that nothing destructive can proceed if the deletion cannot be queued. This will ensure that we have a means to remove all orphaned records. The "logging" step should end-up creating one record in most cases. However, if the delete request or the queuing request were to fail (such as by network error), a subsequent request to delete the project would result in a "duplicate" audit record (depending on how you look at it).
The worker thread that ultimately executes the queued-up cascading-delete would then delete all relevant records and assets from the bottom-up. The bottom-up approach is critical to it being idempotent because if any portion of it failed, we'll need the top-down relationships to exist such that next attempt to process the queued-delete can start where the last attempt failed, working its way up the entity-relationship tree. And, at the very end, this asynchronous delete should probably try to delete the "project" record just in case the original request failed to do so after the request was enqueued.
Workflow: Uploading A Screen To A Project
Business rules and considerations:
- Screen filenames must be unique within a project.
- Screen filenames that differ only by file-extension are considered to be the same.
- Screen filenames that differ only by pixel-density are considered to be the same.
- Screens can be archived.
In many ways, this workflow mimics the project-creation workflow in so much as we have a unique naming constraint and the ability to archive records. As such, we will need an active "screen" table that enforces unique naming and a "screen_archive" table allows unbounded archived records. What makes this workflow worth looking into is the fact that variations on a filename are all considered the same from a consumption point of view. For example, each of the following filenames represent the same entity in the application:
- home.png
- home.jpg
- home@2x.png
- home@2x.gif
- home@3x.png
Because of this, it's not as simple as just adding "clientFilename" to the composite index. Instead, what we have to do is created a normalized version of the filename and store that in the composite index:
- home.png => home
- home.jpg => home
- home@2x.png => home
- home@2x.gif => home
- home@3x.png => home
With this filename "base", we can create a unique, composite index on something like "(projectID,clientFilenameBase)" in our "screen" table. Not only does this enforce our constraint, it also makes it easier to query for matching screen records based on any incoming variation.
As this post has already gone on too long, I will cut it off here. There are still many more InVision App distributed locks that could be worth investigating; however, many of them are some variation on the ones seen above. As someone who is not used to thinking in terms of idempotent actions, this is both a thrilling and a frustrating thought-experiment. And, in many ways, these actions also require me to think in terms of flexible and eventual consistency, which is also a new mindset.
Really, it would be great if someone would publish an "Idempotency Cookbook" where it's essentially 500-pages of this kind of workflow analysis. Only, more in-depth, with some code samples, and better, more epxerienced thinking. Can you do that for me, please?
And finally, a huge shout-out to Ben Darfler who is continually helping me to open my mind and see application architecture in a new light!
Reader Comments