
Command-Query-Responsibility-Segregation (CQRS) Makes Domain Models Practical
As I've been learning more about software application architecture and trying to get my feet wet with real Object Oriented Programming (OOP), one of the biggest stumbling blocks has been trying to reconcile the constrained nature of a domain model with the rather numerous and diverse set of user interfaces (UI) that leverage said domain model. In my experimentation, as each UI was added to the application, it seemed that the domain model would have to grow in order to deliver the new data requirements. This eventually created a large and sloppy domain model that loaded far more information than could ever be needed by any single request. The situation seemed hopeless. But then, I started reading about Command-Query-Responsibility-Segregation (CQRS) and I had an enormous "Ah-ha!" moment of clarity.
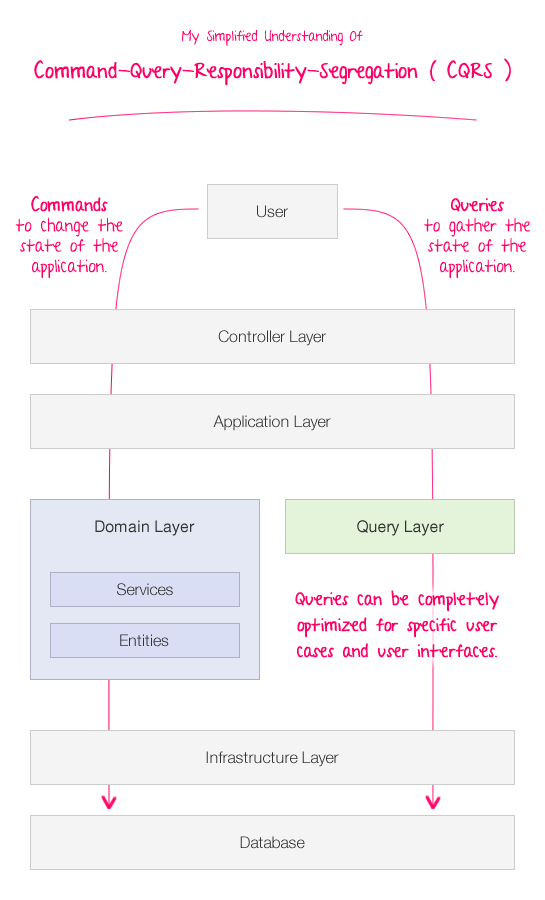
According to people like Martin Fowler and Udi Dahan, Command-Query-Responsibility-Segregation (CQRS) is a rather involved concept that makes use of things like application events and different, "eventually consistent," database stores; but for me, I like to dumb it down quite considerably such that my unfrozen caveman brain can comprehend it. When I think about CQRS, I sum it up as follows:
Commands (ie. requests to change the state of an application) are handled differently than requests to query the state of an application.
This is huge! This separation of responsibilities suddenly makes the domain model practical. Domain models are awesome for making sure that the application stays in a valid state. Databases, on the other hand, are awesome for gathering relational data. CQRS speaks to both of these strengths. If you want to change the state of the application, go through the domain model; if you want to query the state of the application, go directly to the most optimized source of data!
| |
|
|
||
| |
 |
|
||
| |
|
|
When I first started learning about Object Oriented Programming (OOP), people told me to stop thinking about the database. And, I tried - I really tried. The problem with this, however, is that you also stop thinking about SQL. And, subsequently, you forget that SQL is really awesome at doing a lot of what you need to do in your application - namely, present data. CQRS gives you a way to keep a concentrated domain model while allowing you to grow your "query layer" as the needs of your user interface evolve.

Reader Comments
Nice concept Ben,
But will it not cause overhead of maintaining two separate models ?
Great post Ben, CQRS seems really sensible and frees us from trying to squeeze round pegs through square holes. Out of curiosity, what software did you use to create your diagram (nicely done)?
@Maddy,
Granted, I have not had too much experience with this yet; but, I think you have just the opposite - you get Freedom. Instead of having to make sure your domain model is capable of easily populating every user interface, you are freed up to create queries that are specialized for specific interfaces. And, as your domain model evolves naturally, you may not even have to change your query model at all.
That said, what I've been doing lately is establishing a "core' set of properties that every query should have given the model that it is building on top of. For example, if I have a set of queries that deal with some representation of "User", they do all include a reasonable subset of the properties the User domain model would have.
@Dominic,
Yeah, there's something about this approach that really seems to solve a pain that I've been having for a good while.
As for the image, I use Adobe Fireworks for all of my image processing stuff. It's really great - combines vector and bitmap tools in perfect balance.
@Ben,
Yes, eventually everything will boils down to our requirements. Surely i'll give a try on this.
Hi Ben,
Yes, I hit the same issue. Using ORM to save the state of the entities is great. However, the hoops I found myself jumping through to query data (using HQL) from entities with lots of interconnections was way too much and I found myself saying "f*** it!" and did it using SQL instead! Much faster to write and maintain and less heartache getting it to work as required. Probably faster to execute too although I havent tested that.
Thanks, nice to know I am not the only heretic!
Murray
@Murray,
After years of development, I'm starting to realize one thing - refactoring code is really not a Herculean task... as far as TIME is concerned. I've never met a change in the database that I couldn't propagate through the entire app in (worst case) like 2 hours. And often times, only a minute or two. With IDE's ability to do extended search through your project, finding instances of something that needs to be changed is straightforward.
All to say, I'm not afraid to "duplicate" a set of query columns in various *optimized* queries. If a new column needs to be added, removed, or renamed... no problem: Search, Find, Edit, Save... Done.
If you force your same model to serve many different UIs, I find that you'll often see new, unnecessary properties pop-up in your model since a developer needed it in some random UI, unrelated to your UI. This adds unexpected bugs and processing overhead.
But, I really do need to sit down a think through this stuff deeply. I need to figure how to organize files and what to name things. That stuff is always hard!
Hi Ben,
My company is actually planning to implement CQRS architecture but I'm a bit unsure how to the client handles this from a consistency point of view. When I hit the back-end will the server wait until the actual data is stored/changed or will it just return an "202 Accepted" response like I've seen some people doing? But the obvious question ... when do I change the data on the client, because I have no idea when the server finishes all the stuff.
The best scenario would be the server to push a notification to the browser once everything is finished but that means talking sockets/long pooling and I'm not very confident to have a massive app with loads of users flying around thousands of opened sockets.
Any thoughts on that would be greatly appreciated!
@Adrian,
You should read http://www.udidahan.com/2011/04/22/when-to-avoid-cqrs/. Udi says : "the strongest indication I can give you to know that you're doing CQRS correctly: Your aggregate roots are sagas". Sagas are long-running business process, because of the nature of those process you can avoid using push notification to the browser and you could use email notifications.
@Adrian,
If you are still interested I can help you apply CQRS.
@Josué,
Thanks a lot for the article it was an interesting read. There's a few months since I posted my first comment and since than we managed to get CQRS in place working nicely with websockets.