
Drawing Parallels Between a Flux-Style State Management Architecture (Like Redux) And An Event-Driven Microservices Architecture
CAUTION: This post is mostly just me thinking out-loud about stuff with which I have little experience. Take the following with a grain of salt. I'm just trying to formulate a better mental model for complex architectures that have long-term maintainability.
The vast majority of my experience resides in the world of monoliths - those large, one-size-fits-all containers that house all the code needed to run a given application. I love the monolith; it has gotten me quite far in life. But, at work, we're in the middle of decomposing our monolith into a collection of microservices. And, to help us move in the right direction, Tom Lee, the lead engineer on our Platform Labs team, has been educating people on how to use Kafka as the event-based backbone of inter-service communication.
To be frank, Tom's recent presentations have kind of blown my mind; one side-effect of which is that I'm now thinking about event-based architectures in a completely new light. And, it was with this altered perspective that I just finished reading through Taming The State In React by Robin Wieruch. Wieruch's book is about using Redux (and MobX) to manage client-side state in a Single Page Application (SPA). Redux is a Flux-style state management library that uses an event-stream to make append-only changes to an in-memory data cache. As I was reading Wieruch's book, I couldn't help but start drawing parallels between Redux and Kafka. This, of course, lead to me wonder if there were other commonalities that I could find between a microservices architecture and a Flux-style state management architecture (like Redux or NgRx Store).
The way I understand it, you can't simply take a monolith and break it up into different services and call it a "microservices" architecture. In doing so, you're just as likely - if not more likely - to create a "distributed monolith". That is, a monolith that is separated by HTTP calls instead of in-process method invocation. A distributed monolith is the "worst of both worlds," combining the complexity and overhead of a distributed system with the tight-coupling of a monolithic code-base that is now much harder to understand as it is spread across many different repositories.
From what I have seen in presentations and heard in podcasts - remember, I live in the world of monoliths - is that in order for a collection of services to be a true "microservices" architecture, the services need to have low coupling and high cohesion. This has two significant implications:
- You can't have a lot of inter-service calls (ie, services constantly querying other services).
- If one service goes down, it can't take the rest of the application down with it.
To make this possible - to avoid creating a "monolith that is separated by HTTP calls" - each microservice will have its own local database. Then, it will use an event-bus, like Kafka, to listen for global events such that each service can create local, materialized views into another service's data (if need-be). This way, instead of "Service A" constantly calling "Service B", "Service A" will keep an up-to-date cache of some portion of "Service B" data such that it can read from its own local cache rather than making slow, blocking, synchronous HTTP calls to "Service B"s API.
NOTE: This is broad strokes, of course; services are allowed to query each other. And, even a materialized-view cache has to be initialized with data that it doesn't own. Each service should also implement things like Circuit Breakers and other measures that help prevent cascading failures. And so on, yada yada yada, microservices.
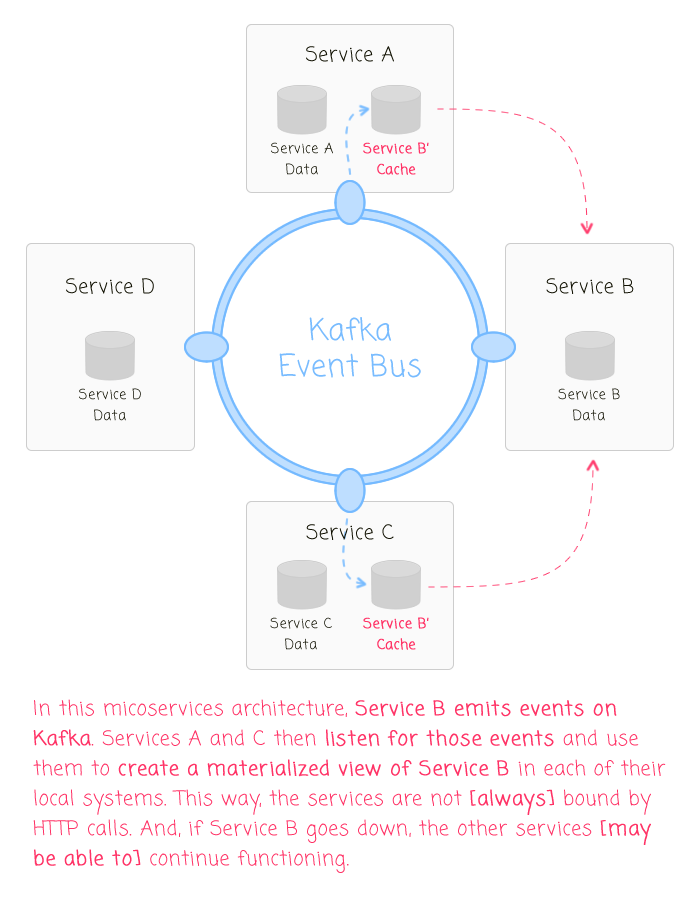
An event-driven microservices architecture might look something like this:
| |
|
|
||
| |
 |
|
||
| |
|
|
As you can see, in this microservices architecture, rather than [always] making HTTP requests to "Service B," some of the other services are listening for events on the event-bus. These events are used to create and update materialized views of B-relevant data in each service. By doing this, it allows the services to operate with lower coupling and better isolation. Should "Service B" crash, the services with materialized views are much more likely to be able to stay online and serve client-requests.
NOTE: It is as much a "business constraint" as it is an "architectural constraint" as to how stale a materialized view can get and still be usable. For example, if "Service B" is a "permissions" service, how long can stale permissions be used to serve requests in "Service C" before it has to flush its cache?
Now, this isn't really a post about microservices - it's about Redux and Flux-style architectures. And, when I look at the above graphic, I don't have to squint all that hard to see Redux. After all, isn't Kafka basically the Redux .dispatch() method? And, aren't the databases basically reducers? And, aren't the individual services basically Single Page Application (SPA) features?
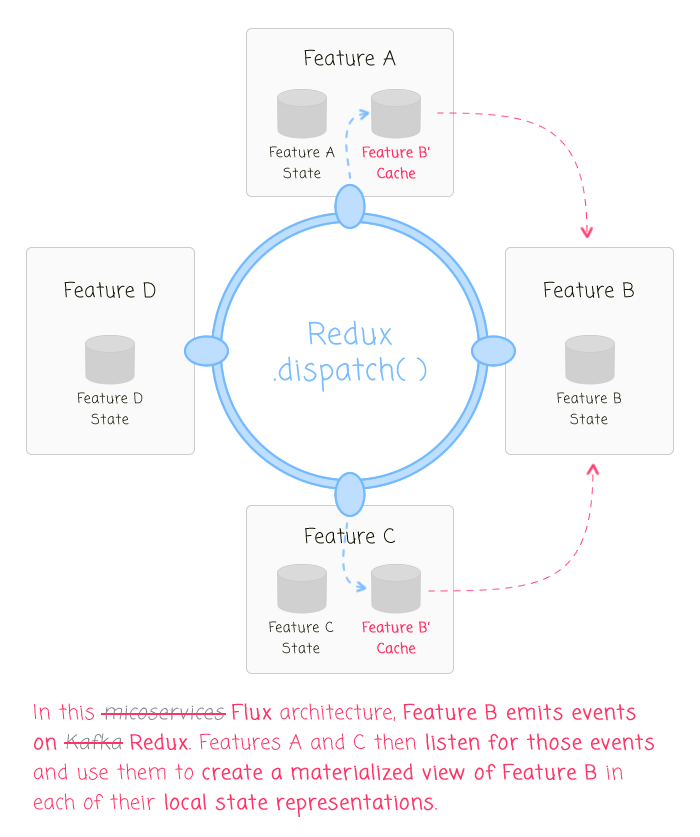
If we take the above microservices architecture and overlay a Single Page Application (SPA) model, we may get something like this:
| |
|
|
||
| |
 |
|
||
| |
|
|
In this Redux / Flux architecture, just as with a microservices architecture, each feature emits events based on application activity. Then, each feature reducer listens for those events in order to make append-only (ie, immutable) changes to the local state model. This keeps the features very decoupled and highly cohesive. And, perhaps as the most important side-effect, this keeps the features extremely easy to add and delete because every piece of relevant functionality is contained locally to the feature.
Of course, the Redux / Flux model isn't a one-to-one match for microservices. And, I think the differences are just as interesting as the similarities. In a Single Page Application (SPA), each feature has its own data; but, the "ultimate source of truth" in a SPA is still a remote data store on the other side of an AJAX (Asynchronous JavaScript and JSON) call. And, since the client-side data, by its very nature, is always ephemeral, each feature is really just a materialized view that is initialized with said remote data.
This may seem unnecessarily hand-wavey and hair-splitty, but I think this has implications on how we think about cross-feature communication in a Redux application. Specifically the use of "selectors" and what it means to be a "source of truth". The more I think about it, the more I think that all cross-feature communication in a Redux architecture should be implemented with .dispatch() events. Meaning, "Feature A" can consume events emitted by "Feature B"; but, "Feature A" cannot use a selector that exposes "Feature B" state. Or more generally, a feature can only consume its own state (alongside all events exposed to the reducers).
What this means is that if three features need some variation on "user list", all three features will have local state representations of the "user list". And, if an event that mutates a user is dispatched, all three features will independently have reducers that consume said event (if they want to) such that they can mutate their own local materialized view of "user list."
At first blush, this may seem like a duplication of effort. But, I don't believe it is. This approach allows each feature to evolve independently. And, be added and removed to and from the Single Page Application (SPA) with very little effort. I think any perceived duplication of work is outweighed by the high degree of feature decoupling.
Now, in the microservices architecture, each service was still the "source of truth" for its own data. Which means that if "Service B" comes online for the first time and needs data from "Service A", "Service B" has to query "Service A" for that data. "Service A" is the source of truth. In a Redux / Flux application, the initial "source of truth" for each feature is the remote data store. As such, if "Feature B" is loaded into the application and needs to initialize its own local state with remote data, it has to get that remote data from an API call - not from the state of another feature. In other words, "Feature A" is never the "source of truth" for the state of "Feature B" - the remote data store is the source of truth for both features.
The one exception to this may be a truly cross-cutting concern like the "user session." The "user session" necessarily precedes all other features. As such, all features are implicitly coupled to the "user session". The "user session" is not an independent feature of the application - it is the essence of the application. That said, it would certainly be possible for a feature to pull the user from the server when it went to initialize its own local state.
Anyway, my brain is just bubbling and marinating on all of these new architectures and libraries and calculated trade-offs. Unfortunately, I still have far more questions than I have answers. This post is just an attempt to take the random thoughts whirling around in my head and start to partition them into more meaningful insights. Maybe I'm crazy... crazy like a fox!

Reader Comments
@All,
I'm taking this line of thinking and starting to codify it a bit more:
www.bennadel.com/blog/3525-considering-state-management-boundaries-and-the-separation-of-concerns.htm
This actually moves my mental model even more in the direction of a microservie-esque type of structure, where each "runtime" has its own encapsulated store, and can synchronize via a message bus.