
I Am Struggling To Understand The Atomic Boundaries Of Redux Actions
CAUTION: This post contains no answers, only questions and statements of confusion. I'm writing it in hopes that by getting it out of my head and onto paper, I might be able to make more sense of it.
For the last few weeks, I've been noodling on the implementation of state management in JavaScript applications using tools like Redux and NgRx/Store. And, to be honest, I feel completely lost. Every time that I think I'm making progress, I see something or consider something that completely calls everything into question. Over the weekend, I was banging my head against RxJS Streams; and now, this morning, I realize that I have no mental model for the atomic boundaries of a state store action.
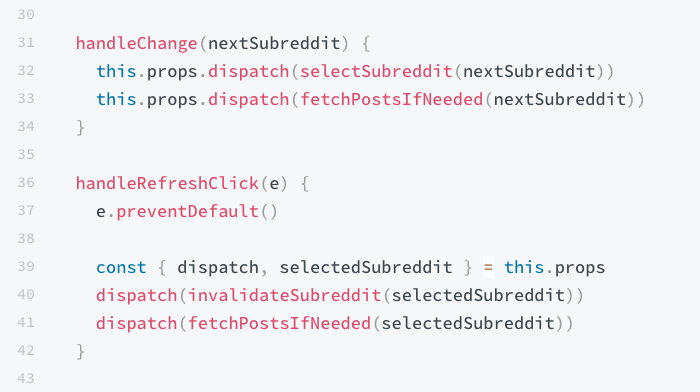
Consider this snippet of code from the official Redux documentation (advanced example):
| |
|
|
||
| |
 |
|
||
| |
|
|
Notice that each one of these user interaction event handlers dispatches two synchronous actions back-to-back. This means, in one tick of the event loop, we're sending multiple mutation requests to the internal state tree.
Now, you may wish to call out that the fetchPostsIfNeeded() action has an asynchronous aspect to it; which is true. But, that's only after it dispatches a synchronous action first. So really, in each one of these user interaction event handlers, we have three actions under the hood:
- synchronous action.
- synchronous action (fetch state initiated).
- asynchronous action (fetch state resolved).
My concern is not with the asynchronous action but with the fact that two synchronous actions are taking place with temporal coupling. Which begs the question: why not dispatch an event that implicitly couples these actions rather than relying on the calling context to explicitly couple them?
Now, you may wish to call out that the fetchPostsIfNeeded() action only happens sometimes. So, it's possible that - depending on the existing state - each one of these user interaction event handlers will only dispatch a single synchronous action against the store. But, such logic could still be encapsulated in such a way that only a single action would need to be dispatched from the stand-point of the calling context, thereby removing the responsibility of the temporal coupling in the calling context.
Drawing on the mental model of a relational database, I can't help but think about possible rules around "atomic" changes. That is, changes that have to succeed or fail together. Up until now, I've been thinking about a single action as having to implement atomic state changes based on a user interaction. But, in this example, what we see is a single user interaction leading to two separate atomic actions. Which begs the question: how does one define the atomic boundary of an action in a state store?
Or, perhaps articulated in another way: which temporal coupling is controlled by the application and which temporal coupling is controlled by the state?
I have no idea. I am flummoxed.
The only inkling that I have is that it is somehow related to "business logic." I believe that I read that you are not supposed to implement business logic in your state reducers. So, temporal coupling that is driven by business logic would remain in the calling context. And, temporal coupling that is related to the fundamental nature of a data-structure (perhaps akin to the "Aggregate" in Domain-Driven Design) is encapsulated inside the state reducers.
But, at the same time, I feel like I see violations of this theory all over the place (such as reducers that increment counters and change data at the same time - something that is clearly business logic).
I just don't get it.
What I need is someone to clearly explain how something like the abstraction of a database maps to the abstraction of a state store. If I could line those two things up, then maybe I would be able to make some progress.

Reader Comments
Hi, Ben. We've chatted a couple times on Twitter before.
I know you use your blog as a form of exploratory thinking, and that's great. That said, you really ought to spend some time reading through the "Idiomatic Redux" and "Practical Redux" series on my blog :) I think you'll find answers to a lot of your questions in my posts, or at least some food for thought.
To more specifically answer this post: how you design your actions is up to you, both in terms of literal terminology ("SET_THING" vs "SOMETHING_HAPPENED"), and how your reducers respond to any given action.
Dan's original intent for Redux was definitely more along the lines of "publishing events", but in the real world, a lot of people have wound up treating them as "setters at a distance". Both are valid ways to view actions conceptually, but treating actions as "setters" is perhaps one of the things that leads to people viewing Redux as being complex - "why do I have to write a reducer, etc, just to update a value"?.
If you do need to specifically group some actions together as a "transaction", or cut down the number of store update events, there's plenty of addons available to do that.
Similarly, whether you put "business logic" in your reducers is also entirely up to you. I've seen apps whose reducers are nothing more than
return {...state, ...action.payload}for any given action type. I've also seen reducers with very complex logic inside. I would personally lean towards putting more logic in reducers myself.Lemme give you a few specific links to look through. Beyond that, please ping me on Twitter or Reactiflux at @acemarke if you have questions - I'm always happy to try to answer things :)
https://blog.isquaredsoftware.com/series/idiomatic-redux/ (all of them, really, but especially "Thoughts on Thunks" and "The Tao of Redux, Part 2" in relation to this post)
https://blog.isquaredsoftware.com/series/practical-redux/
https://redux.js.org/faq/codestructure#how-should-i-split-my-logic-between-reducers-and-action-creators-where-should-my-business-logic-go
https://redux.js.org/faq/performance#how-can-i-reduce-the-number-of-store-update-events
https://redux.js.org/faq/actions#is-there-always-a-one-to-one-mapping-between-reducers-and-actions
https://redux.js.org/recipes/structuringreducers/normalizingstateshape
@Mark,
I really appreciate the feedback and the links. I will definitely check out your Idiomatic Redux series -- sounds like exactly the kind of rundown I am looking for.
I guess what I'm trying to do is get the bottom (or the top?) of the problem. Meaning, I've built Angular applications before that are non-trivial and have synchronized state. But, it was with home-grown patterns and it's complex and can be hard to maintain (especially when more cooks get in the kitchen). So, what I'm looking for is a way to make it simple. But, when everyone starts doing different things - and calling it the same thing - it makes me feel like there's some lower-level more unifying thought.
Like, maybe the core value-add with all of this is simply push-based value updates. And then the rest is just implementation details?
I don't know - my head is swirling. That's why i try to look for rules that I build on top of.
I'll read the links, and hopefully they help a bit :D
If you really want to go back to basics, there's the "Three Principles" listed in the docs:
To some extent, everything else on top of that is convention (which is part of what my posts talk about).
One of my favorite quotes that I've run across is: "A platform for developers to build customized state management for their use-cases, while being able to reuse things like the graphical debugger or middleware".
I suppose if I were to summarize the "core value proposition", I'd say that it's being able to see exactly where, when, why, and how a given piece of state changed, and leveraging that both for the development process and the app's capabilities.
One other link to toss out. Earlier this year, I did a 2-day "Redux Fundamentals" workshop. A lot of workshops and courses focus on the "building an app" approach, and that's fine. However, I wanted to de-mystify Redux, show exactly what goes on internally, and show that there truly is no "magic" inside. The workshop wasn't recorded, but I did publish my slides on my blog. You might want to skim through those as well:
https://blog.isquaredsoftware.com/2018/06/redux-fundamentals-workshop-slides/
@Mark,
I think those truths make a lot of sense, regardless of how everything is wired together. If I reflect on the biggest mistakes that I've made early in my app development, it was allowing the state to be changed by areas of the app that didn't "own' the data. That was the hardest thing to cope with as time went on because it became difficult to know when the data changed. And, speaking of knowing "when", that's what appeals to me so much about "push" (ie, subscribe) based updates.
Ok, time to sit down and read though those links :)