
Using jSoup To Extract JSON+LD Structured Data In ColdFusion 2021
On it's own, Google does a great job of parsing, inspecting, and conveying the content of web-pages in their search results. However, as content creators, we can help Google understand the meaning of a page by embedding structured data in our markup. In a perfect world, I'd have all of this structured data ready to go. But, in reality, I'm going to try and retroactively squeeze my current content into a structured data format: JSON+LD. And, to get this done, I'm going to use jSoup to locate and extract image URLs in my ColdFusion 2021 blog.
For a while now, I've been using jSoup to cleanup and normalize my content. In fact, this isn't even the first time that I've used jSoup to transform my content for new use-cases: earlier this year, I looked at using jSoup to extract Open Graph / Twitter cards in ColdFusion.
In this post, I'm applying that same strategy: using jSoup to parse my blog post into a Document Object Model (DOM) such that I can query it and extract free-form data-points for use within my JSON+LD page element.
JSON+LD is a light-weight "Linked Data" format that uses JSON (JavaScript Object Notation) to define machine-readable information. And, we can provide this data to Google's search bot by including a <script> tag of type="application/ld+json" in our <head> element. For example:
<!doctype html>
<html lang="en">
<head>
<title>
ColdFusion is so Wonderful!
</title>
<script type="application/ld+json">
{
"@context": "https://schema.org",
"@type": "NewsArticle",
"headline": "ColdFusion is so Wonderful!",
"image": [],
"datePublished": "2022-08-21T07:05:00Z",
"author": [
{
"@type": "Person",
"name": "Ben Nadel",
"jobTitle": "Principal Engineer",
"url": "https://www.bennadel.com/about/about-ben-nadel.htm"
}
]
}
</script>
</head>
<body>
<!--- Body of your document. --->
</body>
</html>
With the data above, there's really no need for jSoup. It's that image property that requires a little more elbow-grease. I need to use jSoup to parse my content so that I can search for embedded images, extract them, and provide them in the JSON+LD structure.
Here's a truncated version of the ColdFusion component that prepares the data from my blog-detail page. Notice that I am querying the Document Object Model for image tags with a src attribute that point to my uploads folder:
component {
/**
* I get the JSON+LD structured data for the given post.
*/
private struct function getStructuredData( required struct post ) {
var dom = jSoupJavaLoader
.create( "org.jsoup.Jsoup" )
.parse( post.content )
.body()
;
// CAUTION: We know that the partial-normalizer has replaced all of the resource
// uploads with CDN-based URLs. As such, all of the uploaded images should already
// be fully-qualified URLs.
var images = dom
.select( "img[src*='/resources/uploads/']" )
.map(
( node ) => {
return( node.attr( "src" ) );
}
)
;
var data = {
"@context": "https://schema.org",
"@type": "NewsArticle",
"headline": "#encodeForHtml( post.name.left( 110 ) )#",
"image": images,
"datePublished": dateTimeFormat( post.datePosted, "iso" ),
"dateModified": dateTimeFormat( post.updatedAt, "iso" ),
"author": [
{
"@type": "Person",
"name": "Ben Nadel",
"jobTitle": "Principal Engineer",
"url": "https://www.bennadel.com/about/about-ben-nadel.htm"
}
]
};
return( data );
}
}
As you can see, I'm locating my <img> elements, mapping them onto an array of fully-qualified URLs, and then I'm using that array to define the image property in the JSON+LD structure. The only real funky thing here is that I have to encode the headline for an HTML context. Since this data is going to be rendered inside a <script> tag, I have to make sure that a closing </script> tag in my headline doesn't accidentally break-out of the JSON-LD definition.
With this data in place, I then serialize and output in my site's layout template:
<!--- Reset the output buffer. --->
<cfcontent type="text/html; charset=utf-8" />
<cfoutput>
<!doctype html>
<html lang="en">
<head>
<meta charset="utf-8" />
<title>
#encodeForHtml( request.template.metaTitle )#
</title>
<script type="application/ld+json">
#serializeJson( request.template.structuredData )#
</script>
<!--- Truncated for demo. --->
</head>
<body>
<!--- Truncated for demo. --->
</body>
</html>
</cfoutput>
Once I had this live, I was able to validate it using Schema.org's JSON+LD Validator:
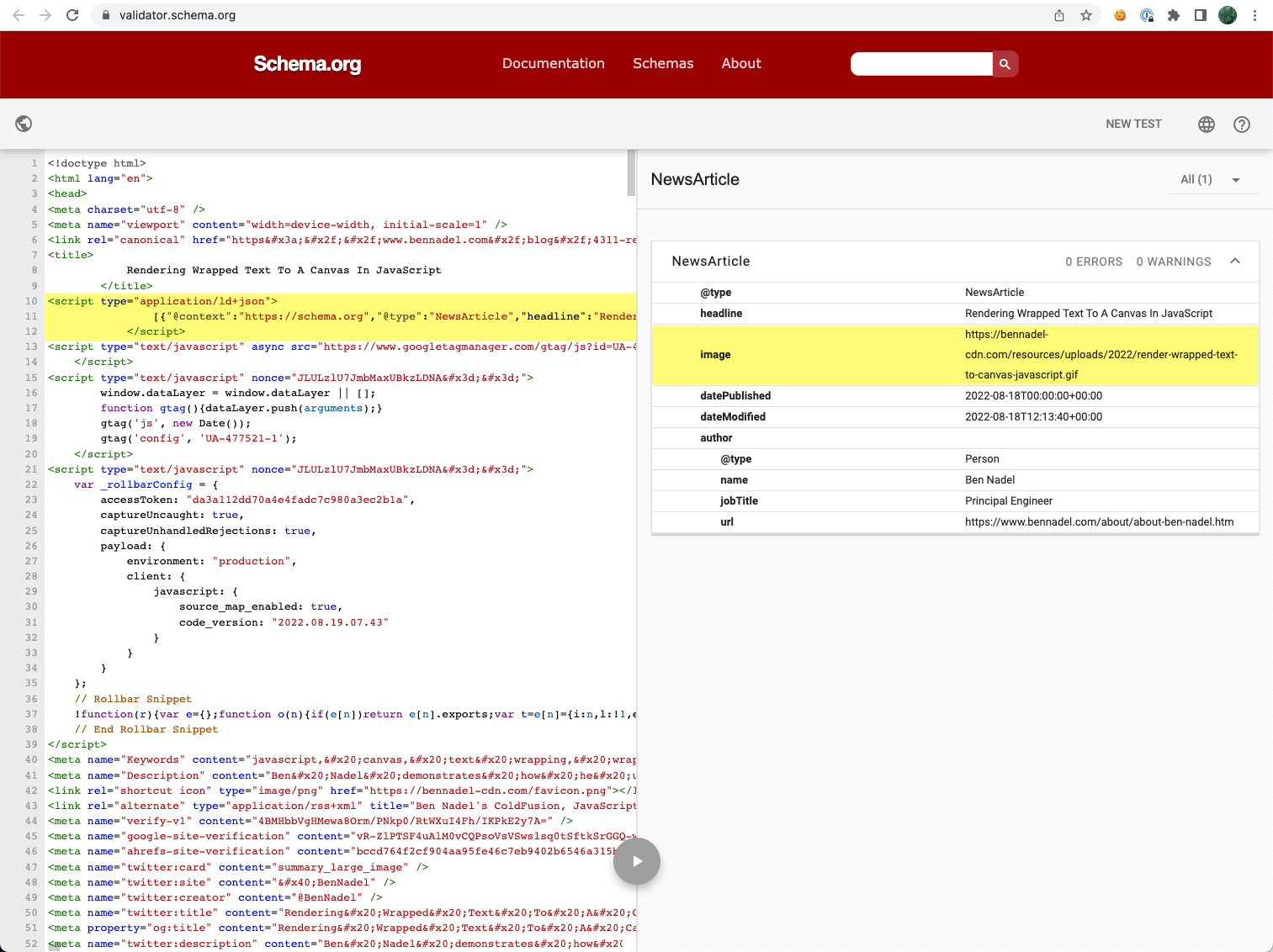
As you can see, I was able to successfully extract the image within the given blog post and include it within my JSON+LD schema markup.
At this time, I only have JSON+LD data embedded within my blog's article pages; but, I do believe that I can define different types of entries for the various pages on my ColdFusion blog. And, to be clear, I have no idea if this will actually make one iota of a difference in terms of how the world (of machines) sees my blog post. But, I figured it would be worth an experiment. If nothing else, it just gave me one more excuse to play with jSoup in ColdFusion.
Want to use code from this post? Check out the license.

Reader Comments