
Using jSoup To Extract Open Graph / Twitter Card Images In ColdFusion 2021
Over the past week, I've been using jSoup to parse, traverse, and modify HTML content in ColdFusion. Sometimes that means creating generative content; and, sometimes that means injecting new content. With the jQuery-like simplicity of content selection, it occurred to me that I could use jSoup to locate images embedded within each blog post. And then, use those images to augment the Open Graph / Twitter Card meta tags for my website's header.
The Open Graph protocol allows web pages to become "rich objects" when shared within a social context. For example, when you paste a URL into Slack or Facebook and those apps show you the title, description, and (sometimes) an image related to the given URL - that's the "link unfurling" outcome associated with that URL's Open Graph meta tags. Which means, we can use <meta> tags within the site <head> to determine (or at least influence) how that link unfurling works.
There's isn't a single set of <meta> tags that exhaustively defines link unfurling. Of course, the Open Graph protocol provides a standard set of tags that everyone can use; but, other sites - such a Twitter - extend that functionality with their own custom tag definitions. I was first introduced to this idea in the context of Twitter; so, I call this data-structure twitterCard in my blog rendering.
At the top of my main rendering template, I look for this twitterCard data; and, if it exists, I output both Open Graph and Twitter Card <meta> tags. Since I am still relatively new at this, I have a lot of redundancy in my rendering. But, apparently, Twitter will fall back to using Open Graph tags in most cases. As such, I can probably remove a lot of this duplication; but, for now, I'm erring on the side of safety.
In the following (truncated) template, the og: prefix stands for "Open Graph":
<!--- Reset the output buffer. --->
<cfcontent type="text/html; charset=utf-8" />
<cfoutput>
<!doctype html>
<html lang="en">
<head>
<meta charset="utf-8" />
<meta name="viewport" content="width=device-width, initial-scale=1" />
<title>
#encodeForHtml( request.template.metaTitle )#
</title>
<!--- ... truncated for demo ... --->
<!--- Twitter card. --->
<cfif ! twitterCard.isEmpty()>
<meta name="twitter:card" content="#encodeForHtmlAttribute( twitterCard.card )#" />
<meta name="twitter:site" content="#encodeForHtmlAttribute( twitterCard.site )#" />
<meta name="twitter:creator" content="@BenNadel" />
<meta name="twitter:title" content="#encodeForHtmlAttribute( twitterCard.title )#" />
<meta property="og:title" content="#encodeForHtmlAttribute( twitterCard.title )#" />
<meta name="twitter:description" content="#encodeForHtmlAttribute( twitterCard.description )#" />
<meta property="og:description" content="#encodeForHtmlAttribute( twitterCard.description )#" />
<meta property="og:url" content="#encodeForHtmlAttribute( twitterCard.url )#" />
<meta property="og:type" content="#encodeForHtmlAttribute( twitterCard.type )#" />
<cfif twitterCard.keyExists( "image" )>
<meta name="twitter:image" content="#encodeForHtmlAttribute( twitterCard.image )#" />
<meta property="og:image" content="#encodeForHtmlAttribute( twitterCard.image )#" />
</cfif>
<cfif twitterCard.keyExists( "imageAlt" )>
<meta name="twitter:image:alt" content="#encodeForHtmlAttribute( twitterCard.imageAlt )#" />
<meta property="og:image:alt" content="#encodeForHtmlAttribute( twitterCard.imageAlt )#" />
</cfif>
</cfif>
</head>
<body>
<!--- ... truncated for demo ... --->
</body>
</html>
</cfoutput>
As you can see, these <meta> tags are verbose but relatively simple. They're just structured content that helps describe the web page in a consistent, predictable way.
Now, let's get back to jSoup and the image extraction. As you can see above, I'm looking for an optional property, twitterCard.image, which will drive the image facet of the link unfurling. Not all of my posts have an embedded image; but, when they do, I'm going to arbitrarily select the first image in the content and use that for my Open Graph tag.
Here's the truncated version of my ColdFusion component that aggregates my blog data for rendering:
component {
/**
* I construct the Twitter / OpenGraph card for the given post.
*/
private function getTwitterCard( required struct post ) {
var twitterCard = {
card: "summary",
site: "@BenNadel",
title: post.name.left( 70 ),
description: post.metaDescription.left( 200 ),
type: "article",
url: "#config.url#blog/#post.filename#"
};
// By default, our Twitter card is just a "summary" card. However, if this post
// contains an image, we can "upgrade" the card to be an "image" card, which will
// include the image in the link unfurling. We can use jSoup to parse, traverse,
// and extract the image SRC and ALT attributes.
var nodes = jSoupJavaLoader
.create( "org.jsoup.Jsoup" )
.parse( post.content )
.body()
// We're looking for images in the uploads directory. Twitter Cards only
// support a subset of image types; but, those are the only types that I
// currently use, so we don't have to worry about file-extensions validation.
// And, since we're limiting the .select() call to IMG elements, we don't have
// to worry about false-positives on non-image files in the uploads directory.
.select( "img[src*='/resources/uploads/']" )
;
// If the post has upload images, we'll use the first one that we find.
if ( nodes.len() ) {
// CAUTION: This assumes that the CDN DOMAIN has already been prepended to all
// embedded image URLs and that all image URLs are now fully-qualified URLS.
twitterCard.card = "summary_large_image";
twitterCard.image = nodes[ 1 ].attr( "src" );
twitterCard.imageAlt = nodes[ 1 ].attr( "alt" ).left( 420 );
}
return( twitterCard );
}
}
As you can see, I'm using jSoup to parse the HTML content of my blog post. Then, I'm looking for <img> elements within the content that link to something in my /resources/uploads/ directory. I don't have to worry about checking the file-extension since I know that I've already limited my jSoup selection to Image Elements. As such, the given file is destined to be an image type.
And, of course, once I have the Image Element, extracting the src and alt attributes is one method call away.
With this extraction in place, and my CFML template rendering of Open Graph meta tags, when I grab a URL from my blog and paste into the Twitter Card Validator, I get the following preview:
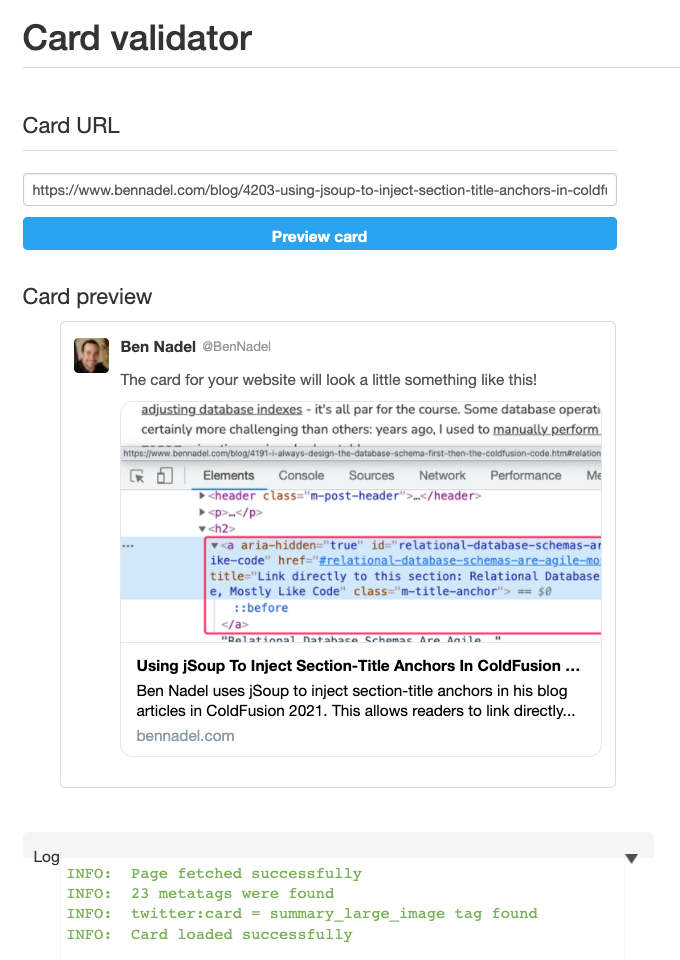
As you can see, the first image within that that blog post was successfully located and extracted with jSoup and ColdFusion and then included in the Twitter social graph meta tags.
Having jSoup available in my ColdFusion blogging platform has really been thrilling. With an accessible DOM (Document Object Model) at my fingertips, I'm starting to think of many interesting ways in which my content can be consumed and repurposed with ease!
Epilogue on Social Media Image Dimensions
I am not a social media marketer. Which is why I'm not spending any time curating images for social media - I'm just picking the first image in the post content. That said, it should be noted that there are "best practices" for image right-sizing in various social media contexts. Which I'm clearly not adhering to since my images weren't intended to be used outside of the post in which they are embedded.
One thing that might be fun to try is programmatically generating right-sized images specifically for social media. Chris Coyier discussed this on CSS Tricks recently; and, it could be a fun experiment to do with ColdFusion and the CFImage functionality.
Want to use code from this post? Check out the license.

Reader Comments
Ben,
For image sizing, we deployed a backend service running Thumbor. We moved away from cfimage for multiple reasons.
We've been super happy with Thumbor's smart cropping which uses face and object detection to make intelligent cropping decisions.
https://thumbor.readthedocs.io/en/latest/enabling_detectors.html
I recently found another project that claims to be a more efficient drop-in replacement for Thumbor. So I've tagged it for consideration
https://github.com/cshum/imagor
@Aaron,
Those projects look very cool!! This is where I start to get quite jealous! It's one thing to do something like this at "work" where I could maybe have a team of people responsible for setting up a service that runs these image processors; but, it's another thing for me to try and do this on my own for personal projects. I just don't have that comfort level yet 😨 But, I want to get there eventually. That's one of the nice things about something like
CFImageand GraphicsMagick - nothing is "running", it's just some code that I call. Of course, there's all kinds of downsides to that as well, such as it all running on the same box and consuming the same CPUs and RAM.But, I'm gonna keep this stuff in my back-pocket and dig in a little more. Because, it really does look very powerful.
@Ben,
Yeah, would be overkill on a personal site where you are in full control of the images.
At work the main thing was getting the ram usage of cfimage out of the JVM. Nothing like a 100KB PNG causing a 300MB ram spike due to cfimage's internal 8-bit TIFF (or whatever it uses internally) representation of it. We moved CFIMAGE out of our front end CFML app several years ago to back end servers where we could better handle the app resets the ram spikes would sometimes cause.
We deal with a lot of user generated content. We'd also had to deal with more and more "problem" images over the years … CMYK JPGs, JPG w/ embedded color profiles.
I'm sure ImageMagik handles those weird cases just fine.
Our dockerized Thumbor has been rock solid for just about three years now.
Here's the image we run: https://github.com/MinimalCompact/thumbor
@Aaron,
I still have trouble wrapping my head around why it takes so much memory to process an image. Even in our ImageMagick / GraphicsMagick pathways, we have to limit the overall size of the image (something like 10k by 10x pixels), cause otherwise it would eat up too much memory. But, I'm like, this file only takes like 5mb on the file-system, why would it take a gig of RAM to process?!? 😳 I don't understand image formats and storage, really.
Anyway, Thumbor sounds really cool! I'll have to look in it some more.
@Ben,
Yeah, I'm with you.
Here are a few snippets about the ImageMagick Pixel Cache .... their internal format.
In short, a uniform way to handle the needs of all of the supported image formats and the ease of coding/debugging were prioritized over memory/disk/CPU usage concerns.
https://imagemagick.org/script/architecture.php
Another Option to file away ...
Libvips is the image processing library used by several image transformation projects -- including the imagor project I shared earlier.
https://github.com/libvips/libvips
It claims to prioritize speed/memory use
https://github.com/libvips/libvips/wiki/Speed-and-memory-use
It has a command-line option and bindings for Ruby, Python, PHP, .NET, Go, and Lua.
Since you're on ACF, maybe you could use directly use the .net stuff.
We're full lucee over here, so we'd have to do cfexecute with the command-line version.
@Aaron,
Yeah, we use
cfexecutefor all the GraphicsMagick stuff, so I'm not too worried about that. But, I am quite fuzzy on is all theapt-getinstall-related stuff; especially around pinning versions and dealing with dependencies. Somehow, it feels so easy with npm and so relatively mysterious with Unix installers. I think part of the problem is that the documentation feels so much more complicated. For example, I just Googled for "How to pin version in apt-get" and the first result (for me) has this:Ummm, what?! With npm, you just include the version and it just works.
But anyway, thanks for the links - we're like a million miles off-topic at this point 🤪 but, definitely good stuff to have in my back pocket. Thanks!
I just started using jSoup for another fun SEO-adjacent concept: embedding structured data (
JSON+LD) in my document head:www.bennadel.com/blog/4312-using-jsoup-to-extract-json-ld-structured-data-in-coldfusion-2021.htm
JSON+LD is a "linked data" format that can help Google better understand what my blog page is about. In the linked post, I'm using jSoup to locate embedded images and explicitly link them to the post content. I have no idea if this makes any difference at all; but, it seemed like a fun experiment.