
Using jSoup To Generate Blog Post Previews In ColdFusion 2021
Now that I have jSoup running on my ColdFusion blogging platform, I've been thinking about various ways to enhance my content experience and to simplify my workflows. And, it occurred to me that I can use jSoup to generate the preview text that I show on my home page. Historically, in my list of recent posts, I've rendered the first 300-characters of text from each post. But, by parsing the HTML of each post into a true DOM (Document Object Model), I can make that process "smarter" by using the content of the first paragraph as the preview text for each post in the list.
Before jSoup, generating the preview text involved a lot of .reReplace() calls to try and strip-out HTML tags within the content. Then, normalizing the spaces and entities. And then, getting a substring of that data. It was sloppy; and, Ray Camden recently pointed out rendering issues with this old approach.
With jSoup, I can use selectors to isolate the first paragraph. And then, use the .text() method in implicitly strip-out all the formatting for me. To demonstrate, consider this sample markdown blog post:
# Demonstrating Blog Post Preview Generation With jSoup
**Happy Friday** my strong, strong friends! I've been waiting for Friday _since
Monday_ and—ermahgerd—it's _finally_ here! I don't know why, but
I've just been exhausted all week. And now, I can't wait to get into bed and
execute a few `<code>sleep(3000);</code>` cycles. Maybe watch a few videos
about massage ([amping me up][youtube-1] and then [cooling me down][youtube-2]).
If nothing else, I gotta finish reading my book on modern JavaScript.
[youtube-1]: https://www.youtube.com/watch?v=zVmsS-ebYWs "Next Stage Injury Prevention"
[youtube-2]: https://www.youtube.com/watch?v=treVpfZfZQI "World Massage Championship"
This is the second paragraph - it won't show up in the preview. It would be the
second element child and is not to be selected.
As you can see, the first paragraph of this post contains formatting (bold and italic), HTML entities (em-dash), inline code blocks, and embedded links to YouTube. When I convert this markdown into HTML using ColdFusion, what I end up with in the database is this:
<p><strong>Happy Friday</strong> my strong, strong friends! I've been waiting
for Friday <em>since Monday</em> and-ermahgerd-it's <em>finally</em> here! I
don't know why, but I've just been exhausted all week. And now, I can't wait to
get into bed and execute a few <code><code>sleep(3000);</code></code>
cycles. Maybe watch a few videos about massage (<a href="https://www.youtube.com/watch?v=zVmsS-ebYWs" title="Next Stage Injury Prevention">amping me up</a>
and then <a href="https://www.youtube.com/watch?v=treVpfZfZQI" title="World Massage Championship">cooling me down</a>).
If nothing else, I gotta finish reading my book on modern JavaScript.</p>
For the preview, I want to get just the plain-text version of this paragraph. Which I am now doing using jSoup:
NOTE: The overall ColdFusion component in this snippet is truncated for the demo. The
jSoupJavaLoaderis the class-loader for the jSoup Java library; and, was discussed in my previous post on using jSoup in ColdFusion.
component {
/**
* I generate the preview HTML from the given blog post content. The returned value is
* expecting to be rendered inside a block-container (such as a Paragraph tag).
*/
private string function getPostPreview( required string content ) {
// The jSoup library allows us to parse, traverse, and mutate HTML documents on
// the ColdFusion server using a familiar, fluent jQuery-inspired syntax.
var dom = jSoupJavaLoader
.create( "org.jsoup.Jsoup" )
.parse( content )
.body()
;
var previewText = dom
// The .child() method only considers Element nodes. As such, we can be sure
// that the zeroth child is the first PARAGRAPH in the blog post (and not a
// white-space text node). We'll use the entire content of the first paragraph
// as the preview text for the post.
.child( 0 )
// The .text() method gives us the COMBINED, NORMALIZED, AGGREGATE of all the
// text contained within the element and its children. As such, this will
// implicitly strip out any formatting tags, links, and inline code blocks.
.text()
;
// CAUTION: When jSoup parses the HTML of the blog post, it will translate HTML
// entity escapes - like """ - into regular values, just like the browser
// does when rendering the page. As such, when we go to render the preview
// content, we have to be sure to re-escape the content.
return( encodeForHtml( previewText ) );
}
}
As you can see, we're parsing the HTML blog post content into a structure Document Object Model (DOM), selecting the first paragraph, and then extracting the text from it. So simple, so clean, so easy! The one thing I have to take into account is that jSoup interprets the escaped HTML entities in the same way that the browser would. Meaning, it converts the escaped values into "normal" values. As such, after I grab the text, I have to make sure to re-encode the content so that aspects like my inline <code> blocks don't end-up being processed as code blocks.
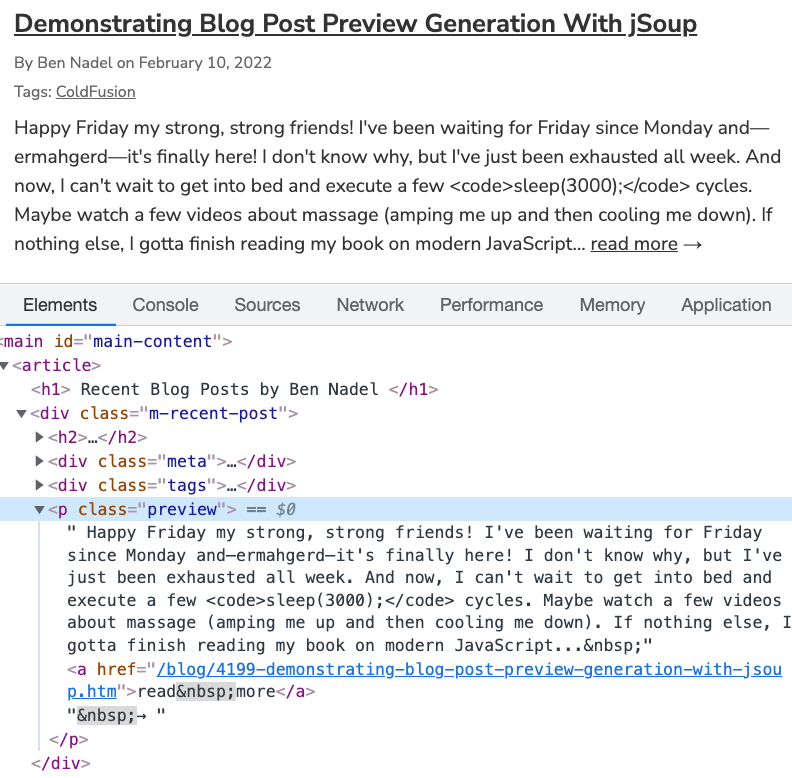
Now, when I render this preview on my home page:
<p class="preview"> #post.previewHtml# </p>
... it's rendered as this HTML:
<p class="preview">
Happy Friday my strong, strong friends! I've been waiting for
Friday since Monday and—ermahgerd—it's finally here!
I don't know why, but I've just been exhausted all week. And now,
I can't wait to get into bed and execute a few
<code>sleep(3000);</code> cycles. Maybe
watch a few videos about massage (amping me up and then cooling me
down). If nothing else, I gotta finish reading my book on modern
JavaScript.
</p>
As you can see, we have all the text from the first paragraph and none of the embedded tags. The .text() method on the jSoup Element node property aggregated and normalized all the text content into a single value; which, we then extracted and re-escaped for HTML output:
Now, don't get me wrong, I love Regular Expression. But, they shouldn't be used to solve every problem. And, somewhat notoriously, they shouldn't be used to parse HTML. Thankfully, I can dump that janky solution and start using jSoup to solve all my HTML parsing needs in ColdFusion. I'm already cooking up a host of other exciting use-cases!
Want to use code from this post? Check out the license.

Reader Comments
Apologies, I'm seeing that the
<code>tags in my GitHub gists aren't being encoded properly. I'll have to look into why that is happening. It's likely some funky sanitization step I'm performing before making the API call to GitHub.For now, I'm going to try and manually fix that in the Gist itself. So, sorry if you see something that looks odd.