
Parsing HTML Natively With htmlParse() In Lucee 5.3.2.77
Parsing HTML isn't a task that I often have to perform during the "normal operation" of a ColdFusion application. However, parsing HTML can be a helpful feature when it comes to data migration. For example, when migrating from an old, HTML-based content management system (CMS) to a Markdown-based content management system. And, as someone who recently started using Flexmark and Markdown to author blog posts, this might be a migration that I attempt to take-on. In the past, I would have reached for TagSoup or jSoup to perform such parsing. But, it turns out that Lucee 5.3 now provides HTML-parsing natively with the htmlParse() function. This function accepts a string and returns an XML document.
The htmlParse() function is simple. You pass it a String; it returns an XML document. You can then traverse the returned XML data structure manually; or, you can use XPath to query for target elements. The complexity with the XPath option is that the htmlParse() function applies a Name Space to the document. Which means that instead of using simple queries like:
xmlDoc.search( "//p" )
... you have to use somewhat janky queries like this:
xmlDoc.search( "//*[ local-name() = 'p' ]" )
The degree to which this bothers you is strictly personal. That said, to make this exploration a bit more interesting, I wanted to create a wrapper function for htmlParse() that uses XSLT (XML Transforms) to remove name spaces from the resultant data structure.
I created a function called, htmlParseNoNamespaces(). To see it in action, I'm going to parse a simple (but invalid) HTML string and then query for the paragraphs:
<!---
CAUTION: The htmlParse() function is very forgiving with invalid markup. But, it
seems to work most consistently when there is a single ROOT NODE in the given markup.
For example, in the following markup, if I remove the "body" wrapper, the structure
of the parsed document completely changes, placing one SECTION element inside the
other SECTION element (presumably because I am not closing the P-tag).
--->
<cfsavecontent variable="markup">
<body class=dark-mode>
<section>
<!-- Testing some cool things. -->
<p id=intro class='content'>This is very interesting!
</section>
<section>
<p>I agree, this is <u class="em">player!</u>
<p>But, will it <strong>work</strong>!</p>
</section>
<p>One wonders.
</body>
</cfsavecontent>
<cfscript>
doc = htmlParseNoNamespaces( markup );
// Gather all of the text from the P-elements. Since the parsed HTML document is
// returned as an XML document, we can use XPath to locate the paragraphs.
paragraphs = doc
.search( "//p" )
.map(
( node ) => {
// For each paragraph, aggregate the string value of the entire node,
// which will include all of the descendant nodes as well.
return( node.search( "normalize-space( string( . ) )" ) );
}
)
;
dump( label = "P-Text", var = paragraphs );
echo( "<br />" );
dump( label = "HtmlDoc", var = doc.search( "//body" )[ 1 ] );
// ------------------------------------------------------------------------------- //
// ------------------------------------------------------------------------------- //
// ------------------------------------------------------------------------------- //
/**
* When the native htmlParse() function runs, it includes XML name-spaces which make
* it much harder to search the subsequent document using XPath. This method strips
* those XML name-spaces from the parsed document, allowing XPath to target node-names
* more directly.
*
* @htmlMarkup I am the HTML string being parsed.
* @output false
*/
public any function htmlParseNoNamespaces( required string htmlMarkup ) {
// To strip out the name-spaces, we're going to use XSLT (XML Transforms). The
// following XSLT document will traverse the parsed HTML document and copy nodes
// over to a new output string using only the node names.
// --
// Read More: https://www.ibm.com/support/knowledgecenter/en/ssw_ibm_i_74/rzasp/rzaspxml4369.htm
var removeNamespacesXSLT = trim('
<xsl:stylesheet
version="1.0"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:output
method="xml"
version="1.0"
encoding="UTF-8"
indent="yes"
/>
<!-- Keep comment nodes. -->
<xsl:template match="comment()">
<xsl:copy>
<xsl:apply-templates />
</xsl:copy>
</xsl:template>
<!-- Keep element nodes. -->
<xsl:template match="*">
<!-- Remove element prefix. -->
<xsl:element name="{ local-name() }">
<!-- Process attributes. -->
<xsl:for-each select="@*">
<!-- Remove attribute prefix. -->
<xsl:attribute name="{ local-name() }">
<xsl:value-of select="." />
</xsl:attribute>
</xsl:for-each>
<!-- Copy child nodes. -->
<xsl:apply-templates />
</xsl:element>
</xsl:template>
</xsl:stylesheet>
');
// In order to remove the name-spaces, we have to parse the document twice -
// once to parse the HTML into an XML document. Then, once again to parse the
// transformed XML string (less the name-spaces) back into an actual XML
// document that we can search using XPath.
return( xmlParse( htmlParse( htmlMarkup ).transform( removeNamespacesXSLT ) ) );
}
</cfscript>
As you can see, I'm using the htmlParse() function to parse the incoming HTML string. Then, I use the .transform() method to remove the name spaces (using the given XSLT document), which produces a serialized XML string. I then parse that XML string back into an XML Document which be searched easily with XPath and simple Element selectors.
Now, when I run this Lucee CFML document, I get the following output:
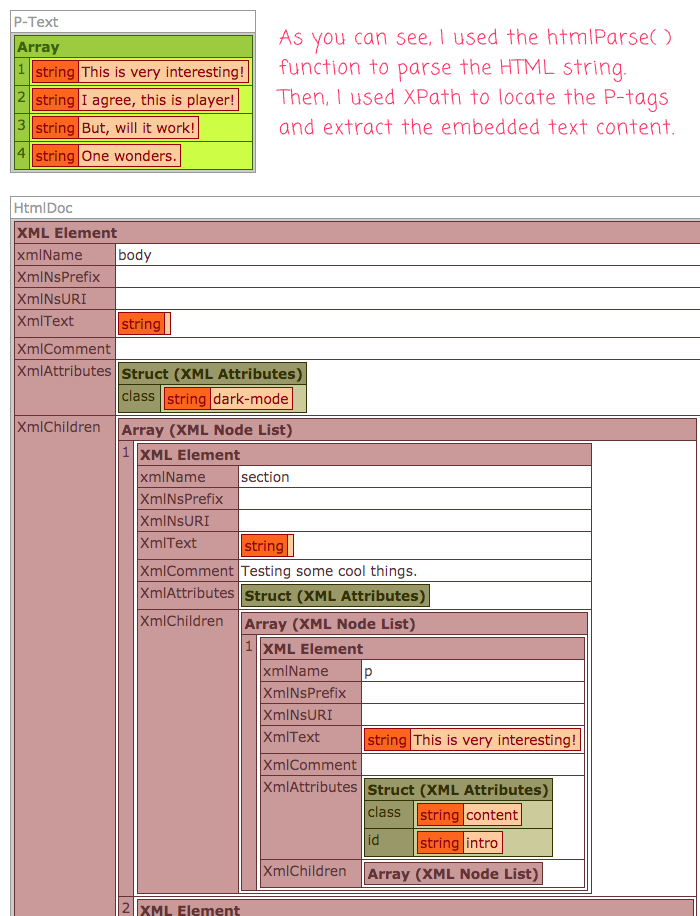
As you can see, one the non-name-space XML document is produced, I can use a simple XPath query like //p to search for the Paragraph nodes. I then use a .map() method to map the P-nodes onto String values.
Again, parsing HTML isn't something that I have to do very often in my ColdFusion code. That said, it's really cool that parsing HTML is now a native feature of Lucee 5.3.2.77. It will making the few times that I do need the functionality all that much easier to consume.
Want to use code from this post? Check out the license.

Reader Comments
This is amazing. I actually never got on too well with jSoup, so I am looking forward to using:
And, I actually like using 'XPath'. It's also great that it still parses everything, even when some of the paragraph tags are not closed.
Impressive stuff...
@Charles,
Pretty exciting, right? One of the things that I would like to be able to do with it eventually is extract fenced-code-blocks from my markdown content. I explored this idea this morning:
www.bennadel.com/blog/3651-dynamically-loading-java-classes-from-jar-files-using-createobject-in-lucee-5-3-2-77.htm
Having to use XPath is not great, when compared with somethings like CSS-based selectors. But, for small things, like my aforementioned exploration, it's a perfectly enjoyable option.
Hi Ben,
I read this article with great interest and it brings me to a thought about a problem that has been bothering me for a long time.
There is a table. Rows (first column) are attribute of something, the columns (first row) are numbers / ratings. The position of an X in the table determines the rating of an attribute.
Is it possible to extract the information out of the table like that?
Attribute A - 2
Attribute B - 3
Attribute C - 1
Attribute D - 2
@Christian,
Sorry for the late reply. But, I assume (without knowing the exact data model here), that you could
.map()the rows onto the given structure you are looking for. So, some pseudo-code for this might look like:I don't know what those internal
.search()values would actually look like since I don't know what kind of HTML you are working with. But, essentially, each.map()iteration would give you access to the parsedTRrow. Then, you can perform a.search()off of theTRcontext to get your specific values (and maybe apply some different logic to translate locations to ratings).Hopefully that helps a little bit.
@All,
After working extensively with
htmlParse()over the weekend, I stumbled upon something interesting - escaped HTML entities are no longer escaped when I read them out through the.xmlTextproperty of the resultant XML document:www.bennadel.com/blog/3789-reading-xmltext-values-from-the-xml-document-produced-by-htmlparse-in-lucee-cfml-5-3-4-80.htm
.... I had to get around this by using the
toString()function on the givenTEXT_NODEand then stripping off the XML DOCTYPE.Excellent information. I just ran into this myself thinking, "Hey, I'll use HTMLParse() and XMLSearch() to do some quick HTML work", but then I was surprised when my xpaths didn't return any results.
This would be a nice feature in Lucee to have an option to remove the namespaces for you. Oooh, look-- there's already a ticket!
https://luceeserver.atlassian.net/browse/LDEV-839
I'll put a link to this blog post there.
Whoa, look at this weird behavior I found while trying to re-parse the cleaned XML. It appears that when you use the
XMLParse()BIF in Lucee to parse an XML document that has a root element ofhtmland a nested element ofhead, Lucee will ADD an invalid meta tag (not self-closing) to the XML that wasn't there. This of course, will throw an error if you convert the XML to a string and then try to re-parse it!Note, I'm not using
HTMLParse()in that example, so I wouldn't expect Lucee to do ANYTHING related to HTML. When I cfdump the parsed XML, the meta tag isn't there, so it seems to get added as part of thetoString()from what I can tell.I have added a ticket here:
https://luceeserver.atlassian.net/browse/LDEV-3913