
Reading XmlText Values From The XML Document Produced By htmlParse() In Lucee CFML 5.3.4.80
Over the weekend, I spent about 2-days trying to retrofit Markdown onto 15-years of HTML-based content using htmlParse() in Lucee CFML. It was an iterative process with a lot of trial and error. And, even after I posted my article, I continued to find new and interesting caveats. One thing that caught me off-guard was that escaped HTML entities within the original HTML source-code became un-escaped when being accessed through the resultant .xmlText properties. As such, I wanted to take a quick look at how I might be able to access the original, escaped-value using htmlParse() and Lucee CFML 5.3.4.80.
To understand what I mean, imagine parsing HTML that contains the following source:
<p> Ben + JavaScript --> Happy </p>
... where the "greater than" character is HTML-encoded so that it doesn't mess up the HTML DOM (Document Object Model). Now, if I were to run this HTML through the htmlParse() function and then access the .xmlText property of that Paragraph node, I would get the following:
Ben + JavaScript --> Happy
Notice that the "greater than" symbol is no longer escaped. In this particular scenario, the fallout may not be bad since the "greater than" symbol is rather innocuous. However, if this were the "less than" symbol, the outcome may corrupt subsequent processing. As such, it's important that we be able to access the original, escaped version of the source.
The only way that I could figure out how to do this was to pass the XML Text Node to Lucee's toString() function and then strip-off the XML DOCTYPE from the resultant value.
To see the various approaches I tried, let's look at some demo code. In the following ColdFusion script, I am parsing a simple HTML snippet with some escaped HTML entities into an XML document; and, then, using various techniques to try an extract the original, escaped value:
<cfscript>
// Let's create some HTML that contains escaped HTML entities ( lt / gt ).
```
<cfsavecontent variable="htmlContent">
<p id="target">
I love the <main> tag!
</p>
</cfsavecontent>
```
// Using Lucee's native htmlParse() function, we can parse the HTML snippet into an
// XML document. From there, we can locate the <p> node.
// --
// NOTE: I am using "//*" because the produced XML document includes XML NameSpaces
// that prevent me from search based on xmlName.
paragraphNode = htmlParse( htmlContent )
.search( "//*[ @id = 'target' ]" )
.first()
;
hrule = ( chr( 10 ) & "<hr />" & chr( 10 ) );
// Let's try to extract the original text-value of the Paragraph tag.
echo( paragraphNode.xmlText );
echo( hrule );
echo( paragraphNode.xmlCData );
echo( hrule );
echo( paragraphNode.xmlNodes[ 1 ].xmlText );
echo( hrule );
echo( paragraphNode.search( "string( ./text() )" ) );
echo( hrule );
echo( encodeForHtml( paragraphNode.xmlNodes[ 1 ].xmlText ) );
echo( hrule );
echo( encodeForXml( paragraphNode.xmlNodes[ 1 ].xmlText ) );
echo( hrule );
echo( toString( paragraphNode.xmlNodes[ 1 ] ) );
echo( hrule );
echo( toString( paragraphNode.xmlNodes[ 1 ] ).listRest( ">" ) );
</cfscript>
Ultimately, what we want is to be able to read the original <main> substring of the source HTML. And, when we run the above ColdFusion code, we get the following browser output:
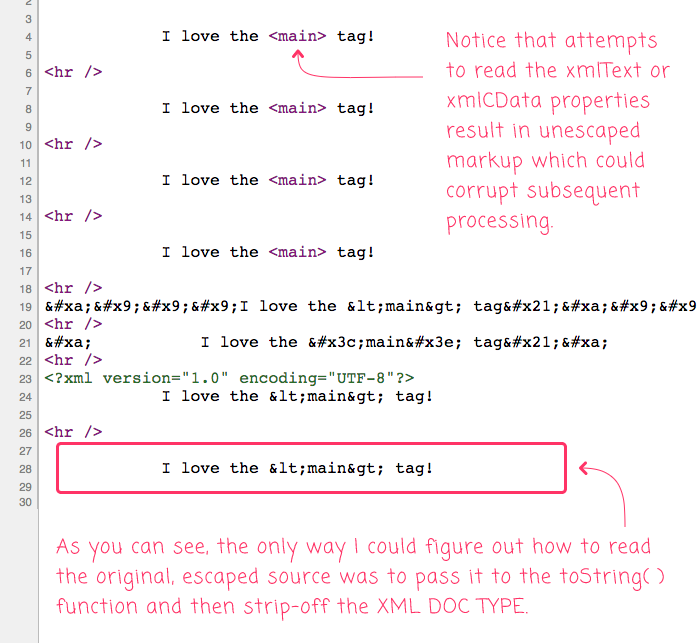
As you can see, any attempts to read the node-text using .xmlText, .xmlCData, or text() resulted in a string that contained unesacped HTML entities. For me, this is highly problematic because I'm attempting to generate Markdown; and, in Markdown anything that looks like inline HTML will be rendered as HTML. Which means, if I attempted to use that <main> snippet of text, it would be interpreted as an HTML Element, not as plain text.
Ultimately, the only thing that I could get to work was:
toString( textNode ).listRest( ">" )
The toString() function produces the following String:
<?xml version="1.0" encoding="UTF-8"?> I love the <main> tag!
And then, the .listRest( ">" ) method call takes everything after the closing-angle-bracket of the XML DOCTYPE, leaving us with just the original, escaped source code.
To be fair, I'm not really a wizard with XML documents. And frankly, I don't even know if this is the expected behavior or not? This also gets further complicated by the fact that we're producing an XML document using htmlParse(). As such, it's not entirely clear if this is an issue with the XML? Or, how the XML is being produced by the HTML-parser? Regardless, this was the only approach that I could use to read the original, escaped HTML entities when using htmlParse() in Lucee CFML 5.3.4.80.
Want to use code from this post? Check out the license.

Reader Comments