
Centering An Image Annotating Using GraphicsMagick And Lucee CFML 5.2.9.31
At InVision, when a user leaves a comment in a prototype, we generate a "context image" for that comment to use in the header of an outgoing notification email. Currently, that context image is generated using ColdFusion's native CFImage functionality. In an effort to see if I can move all of our native ColdFusion image manipulation over to GraphicsMagick, I wanted to see if I can recreate this annotation on the command-line. This requires centering, clipping, annotating, and compositing an image using GraphicsMagick and Lucee CFML 5.2.9.31.
Users can upload images of any size. When we send out our comment notification emails, it wouldn't make sense to include the entire image in the email - there'd be no way to design a good user experience (UX) for that. Instead, we include a clipping of the image that attempts to provide as much visible context around the comment as possible.
To do this, we try to center the comment-annotation within the context image. However, if centering the annotation would leave part of the context image unoccupied by the user's image, we shift the user's image over to meet the edge of the context canvas. In doing so, we hope to the maximize the use of the image surrounding the annotation.
I know this sounds complicated; so, perhaps we should look at the outcome before we dive into the code. To explore this approach, I've taken my previous GraphicsMagick annotation demo, and modified it to create a fixed-clipping rather than an image of equivalent size.
In this version, the user can click anywhere within a given image. The {x,y} coordinates of that click-event then define the location of the annotation within the clipping:

As you can see, as the click-event moves towards the edges of the input image, so does the annotation move towards the edge of the context canvas. We end up clipping the input image; but, we try to retain as much as the visual context as possible.
In the above demo, the input image is larger than the clipping canvas, which means we actually have to clip the input image. In a situation in which the input image is smaller than the clipping, we just want to center the image on the canvas and the apply the annotation in it's natural spot:
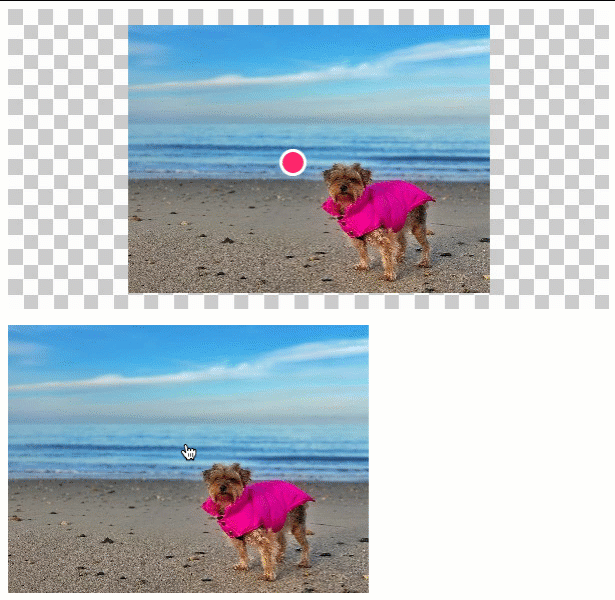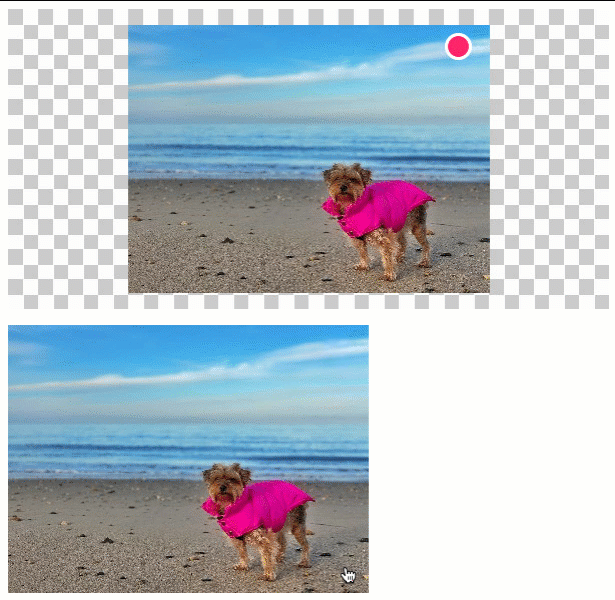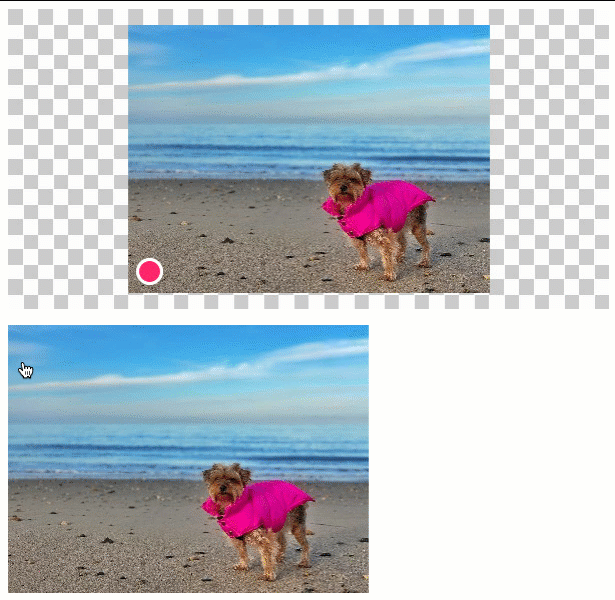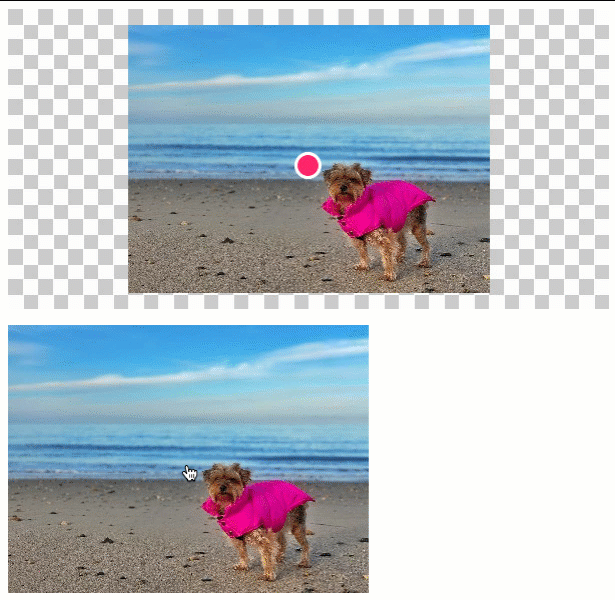
As you can see, when the input image is smaller than the canvas, we center the image and then place the annotation at its natural location within the centered image.
Now that we have a better sense of what we're trying to accomplish, let's look at the code. It takes a few steps:
Read the dimensions of the input image.
Compare the dimensions of the input image to the dimensions of the clipping canvas in order to calculate how to best position the annotation.
Create a blank canvas with the traditional checkerboard background.
Paste the input image onto the blank canvas.
Add the annotation on top of the pasted image.
This exploration is a good deal more complicated than my previous GraphicsMagick explorations. As such, I've tried to factor-out some functionality that isn't key, leaving the main chunk of code as clear as I think I can. I've also put in a lot of comments to help clarify my thought process:
<cfscript>
param name="url.image" type="string" default="beach-small.jpg";
param name="url.x" type="numeric" default=-1;
param name="url.y" type="numeric" default=-1;
startedAt = getTickCount();
// CAUTION: For the sake of the demo, I am not validating the input image. However,
// in a production setting, I would never allow an arbitrary filepath to be provided
// by the user! Not without some sort of validation.
inputFilename = url.image;
inputFilepath = expandPath( "../images/#inputFilename#" );
// Setup the output filepath for our generated clipping.
// --
// NOTE: The file-extension of this output filename will be used by GraphicsMagick to
// figure out how to encode the final image.
outputFilename = "out.jpg";
outputFilepath = expandPath( "./#outputFilename#" );
// As a first step, we need to figure out how large the input image is so that we can
// calculate the clipping and annotation boundaries. To do that, we can use the
// Identify utility.
inputDimensions = getImageDimensions( inputFilepath );
inputWidth = inputDimensions.width;
inputHeight = inputDimensions.height;
// Setup our clipping dimensions - the size of the output image into which our input
// image is going to be pasted.
clipWidth = 600;
clipHeight = 300;
// Setup the size of our annotation circle.
annotionRadius = 12;
// If the user selected a point on the input image, let's generate the clipping.
if ( ( url.x >= 0 ) && ( url.y >= 0 ) ) {
// Ideally, we want our X,Y annotation to be centered within the clipping in
// order to provide as much visual context as possible. However, if we are close
// the edge of the input image; or, if the input image is smaller than the
// clipping; then, we're going to try and include as much of the input image into
// the clipping as possible (regardless of centering).
centerX = fix( clipWidth / 2 );
centerY = fix( clipHeight / 2 );
// If the input image is narrower than the clip width, we want to center the
// input image HORIZONTALLY within the clipping.
if ( inputWidth <= clipWidth ) {
pasteX = fix( ( clipWidth - inputWidth ) / 2 );
// If the annotation is farther LEFT than the center of the clipping, attempting
// to center the annotation would leave a transparent left-border. As such, we
// want to paste the image against the left-border of the clipping.
} else if ( url.x < centerX ) {
pasteX = 0;
// If the annotation is farther RIGHT than the center of the clipping, attempting
// to center the annotation would leave a transparent right-border. As such, we
// want to paste the image against the right-border of the clipping.
} else if ( ( inputWidth - url.x ) < centerX ) {
pasteX = ( clipWidth - inputWidth );
// If the annotation allows the input image to fill the clipping entirely, we
// want to paste the image such that the annotation is centered horizontally.
} else {
pasteX = ( centerX - url.x );
}
// If the input image is shorter than the clip height, we want to center the
// input image VERTICALLY within the clipping.
if ( inputHeight <= clipHeight ) {
pasteY = fix( ( clipHeight - inputHeight ) / 2 );
// If the annotation is farther UP than the center of the clipping, attempting to
// center the annotation would leave a transparent top-border. As such, we want
// to paste the image against the top-border of the clipping.
} else if ( url.y < centerY ) {
pasteY = 0;
// If the annotation is farther DOWN than the center of the clipping, attempting
// to center the annotation would leave a transparent bottom-border. As such, we
// want to paste the image against the bottom-border of the clipping.
} else if ( ( inputHeight - url.y ) < centerY ) {
pasteY = ( clipHeight - inputHeight );
// If the annotation allows the input image to fill the clipping entirely, we
// want to paste the image such that the annotation is centered vertically.
} else {
pasteY = ( centerY - url.y );
}
// Now that we know where the input image is going to be pasted into the
// clipping, we can arrange the composition. To do this, we're going to use the
// Convert utility and then DRAW the input image and the annotation onto the
// clipping canvas.
result = gm([
"convert",
// Start with a "blank" canvas with the desired clipping dimensions. Since
// the input image may be smaller than the clipping, let's use the
// traditional "checkerboard" background to represent portions of the canvas
// not covered by the input image. GraphicsMagick provides a built-in pattern
// image that we can use: CHECKERBOARD.
"-size #clipWidth#x#clipHeight# tile:image:checkerboard",
// The built-in CHECKERBOARD image has two colors: "666666" and "999999".
// Since these colors are static, we can use the -opaque option to re-color
// them with two other colors of our choosing. In this case, I'm going to
// lighten-up the checkerboard colors.
"-fill ##fdfdfd -opaque ##666666",
"-fill ##cacaca -opaque ##999999",
// Now, let's paste the input image onto our checkerboard canvas. If the
// input image is smaller than the clipping canvas, some checkerboard will
// show through; otherwise, the input image will entirely fill the canvas.
// --
// CAUTION: I cannot yet figure out how to explicitly provide a READER for
// the input image in this draw operation. I've opened a Help thread on this
// topic: https://sourceforge.net/p/graphicsmagick/discussion/250738/thread/71a6a6a8e8/
"-draw 'image over #pasteX#,#pasteY# #inputWidth#,#inputHeight# #inputFilepath#'",
// And, once the image is pasted-in, we can apply our annotation marker.
"-fill ##ff3366",
"-stroke ##ffffff",
"-strokewidth 2.5",
// NOTE: We are using "translate" (scoped to the current draw operation), to
// move the coordinate system such that X,Y point is relative to the ORIGINAL
// image, not the clipping canvas.
"-draw 'translate #pasteX#,#pasteY# ; circle #url.x#,#url.y# #( url.x + annotionRadius )#,#url.y#'",
// And, finally, output our composite image!
"-quality 90",
outputFilepath
]);
} // END: If clipping.
duration = ( getTickCount() - startedAt );
// ------------------------------------------------------------------------------- //
// ------------------------------------------------------------------------------- //
/**
* I prefix the given filepath with an explicit reader. We want to be EXPLICIT about
* which input reader GraphicsMagick should use when reading in an image. If we leave
* it up to "automatic detection", a malicious actor could fake the file-type and
* potentially exploit a weakness in a given reader. As such, we want to align the
* reader with the articulated file-type.
*
* READ MORE: http://www.graphicsmagick.org/security.html
*
* @filepath I am the filepath being decorated.
*/
public string function applyReader( required string filepath ) {
switch ( listLast( filepath, "." ).lcase() ) {
case "jpg":
case "jpeg":
var reader = "jpg";
break;
case "png":
var reader = "png";
break;
default:
throw( type = "UnsupportedImageFileExtension" );
break;
}
return( reader & ":""" & filepath & """" );
}
/**
* I return the Width and Height of the image at the given path.
*
* @filepath I am the filepath being inspected.
*/
public struct function getImageDimensions( required string filepath ) {
// NOTE: Trailing comma after -format being included on purposes. It delimits
// multi-page images (like GIFs). While I don't have any GIFs in this demo, I am
// leaving it in so I don't forget why I have it.
var result = gm([
"identify",
"-format %w,%h,",
applyReader( filepath )
]);
var dimensions = result.listToArray();
return({
width: dimensions[ 1 ],
height: dimensions[ 2 ]
});
}
/**
* I execute the given options against the GM (GraphicsMagick) command-line tool. If
* there is an error, the error is dumped-out and the processing is halted. If there
* is no error, the standard-output is returned.
*
* NOTE: Options are flattened using a space (" ").
*
* @options I am the collection of options to apply.
* @timeout I am the timeout to use during the execution.
*/
public string function gm(
required array options,
numeric timeout = 5
) {
execute
name = "gm"
arguments = options.toList( " " )
variable = "local.successResult"
errorVariable = "local.errorResult"
timeout = timeout
;
// If the error variable has been populated, it means the CFExecute tag ran into
// an error - let's dump-it-out and halt processing.
if ( local.keyExists( "errorVariable" ) && errorVariable.len() ) {
dump( errorVariable );
abort;
}
return( successResult ?: "" );
}
</cfscript>
<cfoutput>
<!--- If we have annotation coordinates, render the resultant canvas. --->
<cfif ( ( url.x gte 0 ) && ( url.y gte 0 ) )>
<p>
<img
src="./#outputFilename#"
width="#clipWidth#"
height="#clipHeight#"
/>
</p>
</cfif>
<p>
<!--- This is our input image that the user is annotating. --->
<img
id="image"
src="../images/#inputFilename#"
width="#inputWidth#"
height="#inputHeight#"
style="cursor: pointer ; display: block ;"
/>
</p>
<p>
Reset image:
<a href="./index.cfm?image=beach-small.jpg">Normal</a>,
<a href="./index.cfm?image=beach-tiny.jpg">Tiny</a>
</p>
<p>
Duration: #numberFormat( duration )# ms
</p>
<script type="text/javascript">
// When the user clicks anywhere on the demo image, we want to translate the
// viewport coordinates to image-local coordinates and then refresh the page
// with the given offset.
document.getElementById( "image" ).addEventListener(
"click",
( event ) => {
// Get viewport coordinate data.
var viewportX = event.clientX;
var viewportY = event.clientY;
var imageRect = event.target.getBoundingClientRect();
// Translate viewport coordinates to image-local coordinates.
var localX = Math.round( viewportX - imageRect.left );
var localY = Math.round( viewportY - imageRect.top );
var params = [
`image=${ encodeURIComponent( "#encodeForJavaScript( url.image )#" ) }`,
`x=${ localX }`,
`y=${ localY }`
];
window.location.href = `index.cfm?${ params.join( "&" ) }`;
}
);
</script>
</cfoutput>
I think the math portions of this end up being the most complicated part: trying to figure out how to best position the annotation by shifting the image around within the clipping context. Ultimately, however, I do think that I've mostly re-created the annotation outcome that we currently perform with ColdFusion's native CFImage tag. I'm really enjoying GraphicsMagick!
Want to use code from this post? Check out the license.

Reader Comments
@All,
As a quick follow-up to this post, I took a look at using the
-drawcommand to resize the image as it is pasted onto the canvas. The speed and quality of the resize operations seems pretty good; but, has some issues with CMYK colorspaces (presumably when pasting onto an RGB canvas):www.bennadel.com/blog/3814-scaling-an-image-during-a-draw-operation-using-graphicsmagick-and-lucee-cfml-5-2-9-31.htm
I use two approach, the latter of which uses an intermediary image file, which allows me the opportunity to convert the CMYK colorspace to RGB prior to the
-drawoperation.Thanks Ben. Just the job :-)
@Michael,
Ha ha, outstanding! Love it when something so specific actually is helpful!