
Parsing And Serializing Large Datasets Using Newline-Delimited JSON In Lucee 5.3.2.77
A couple of years ago, Adam DiCarlo taught me about the Newline-Delimited JSON format (NDJSON) for data storage. At the time, I took a look at using NDJSON in Node.js; and, since then, it's a format with which I've become quite enamored. Now that I'm starting to dig into Lucee CFML, I wanted to take a quick look at how easy it is to work with NDJSON data using Lucee's File and Compression functions. This is especially timely for me as I am considering ways to export large amounts of data from a Product in a way that can be easily consumed by end-users.
The Newline-Delimited JSON (NDJSON) format is exactly what it sounds like; it's a series of JSON (JavaScript Object Notation) payloads that are all stored in a single file, delimited by a newline character. The beauty of this format is that you can store a massive amount of data in a single file; and then, safely read it back, one line of a time, without running into memory or performance issues.
To see this in action, I'm going to loop over a collection of in-memory records (keeping it simple); and, for each record, I'm going to serialize the data as JSON and then append the JSON to a single export file. Each record will be appended as a new-line in the same file.
And, to make this demo a bit more exciting, I'm then going to use Lucee's compress() function to ZIP / archive the .ndjson file as .ndjson.zip:
<cfscript>
// This is the data we are exporting in NDJSON format.
records = [
{ type: "contact", data: { id: 1, name: "Kim" } },
{ type: "phone", data: { id: 101, contactID: 1, value: "2125551111" } },
{ type: "phone", data: { id: 102, contactID: 1, value: "2125551118" } },
{ type: "contact", data: { id: 2, name: "Sarah" } },
{ type: "contact", data: { id: 3, name: "Arnold" } },
{ type: "phone", data: { id: 321, contactID: 3, value: "9175558811" } },
{ type: "phone", data: { id: 208, contactID: 2, value: "9175559928" } }
];
// ------------------------------------------------------------------------------- //
// ------------------------------------------------------------------------------- //
// The export data file is going to be a Newline-Delimited JSON file (NDJSON). This
// means that each record is going to be stored as its own JSON payload within the
// single file, where each payload is delimited by a newline character.
exportPath = "./data.ndjson";
exportFile = fileOpen( exportPath, "write" );
for ( record in records ) {
// Serialize each record as JSON and write it to the export file on its own line.
// --
// NOTE: Looking at the Lucee Java source code, we can see that this function
// appends "\n" when writing the data to the target file stream wrapper.
fileWriteLine( exportFile, serializeJson( record ) );
}
fileClose( exportFile );
// Since this is text-data, it should be highly compressible. Let's ZIP this baby up!
compress( "zip", exportPath, "#exportPath#.zip" );
</cfscript>
As you can see, each record is serialized as JSON and then appended to the output file. And, when we run the above Lucee CFML code, we get the following file-output:

As you can see, each line of the export file contains an entire JSON payload.
Now, on the import side, instead of reading the entire file into memory and then parsing it - running the risk of performance and Out of Memory (OOM) issues - we can simply iterate over the file, reading it in one line at a time, parsing the smaller, isolated JSON payloads.
Lucee ColdFusion makes this particularly easy using the CFLoop tag. We can use CFLoop to iterate over a file, one line at a time, without having to worry about managing the mechanics of opening and closing the file reference:
<cfscript>
// When unzipping / extract an archive using extract(), we can't give it a "target
// file" - we can only give it a "target directory". As such, I'm going to extract
// the zip file to a temp directory where we can extract its contents without
// colliding with the original input file (from the first part of this demo).
tempDirectory = "./extract-#createUniqueId()#";
directoryCreate( tempDirectory, true );
try {
extract( "zip", "./data.ndjson.zip", tempDirectory );
records = [];
// Each line of the extracted NDJSON file contains a separate JSON payload. As
// such, we can just loop over the contents of the file and deserialize each
// line in order to access the original data.
loop
item = "recordJson"
file = "#tempDirectory#/data.ndjson"
{
records.append( deserializeJson( recordJson ) );
}
dump( label = "Imported NDJSON", var = records );
// No matter what happens, let's delete the temp directory we created.
} finally {
directoryDelete( tempDirectory, true );
}
</cfscript>
For the sake of this particular demo, I'm extracting the ZIP archive to a temp directory so that I don't overwrite the original file from the "export" portion of the demo. And, when we run the above code, we get the following browser output:
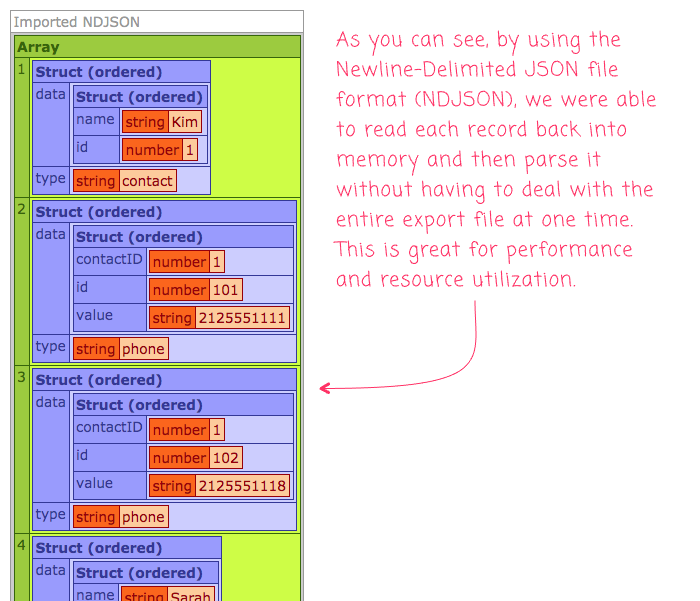
As you can see, using Lucee ColdFusion's file-loop construct, we were able to easily iterate over the export file, reading and processing one JSON payload at a time.
There's something so appealing to me about the NDJSON (Newline-Delimited JSON) file format. It holds the promise of storing a tremendous amount of data without the overhead of intensive CPU and Memory processing. It's basically the "divide and conquer" mindset applied to flat-file persistence. This, combined with Lucee's file and compression functions, is going to make it even easier to create export and import functionality for my ColdFusion applications.
Want to use code from this post? Check out the license.

Reader Comments
This is why I love reading your articles. I always learn something new. Especially, since you have embraced 'cfscript':
Are all new to me. I guess I haven't tried to zip anything, using 'cfscript'!
And, I always use:
When looping over stuff, so it's interesting to understand how to tackle lopping over a file's content in 'cfscript'.
In the past I have used:
But your version looks much more concise.
As for the NDJSON format stuff, this is totally ingenious. It's such a simple idea, but it completely eliminates the 'out of memory' issue. I always squirm at the thought of copying large chunks of file data into memory, especially when it's not always apparent, how much data needs to be copied.
I am now itching to try this out, in one of my projects.
@Charles,
Ha ha, I'm glad that I can uncover little nooks and crannies of the language. Though, as far as using
loopvs.cfloop, that's an interesting point. These days, all tags are supported in CFScript. But, in the older days, there was really only partial and duct-tape support for certain concepts.For example, we had things
savecontent,loop, andnew Http(). But, now that we have solid tag-support in CFScript, I wonder if it would be better to have more consistency with the tags. Meaning, I think it might be better to usecfloop()instead ofloop. That ways, all the script-based constructs are "Tags constructs."Though, I'm just thinking out-load. I am not sure how strongly I feel. Remember, I am moving from ColdFusion 10 to Lucee 5, so I'm taking a massive jump in functionality -- I'm still trying to figure out how to do all the things.
Yes. You may have a point. After all, it is only a 2 letter prefix difference and I guess it enforces the CF brand...
I prefer not having the cf prefix on the commands as it is redundant.
I know it is cf code and anybody that is viewing it should know it is CF code.
I am waiting for an equivalent of executeQuery for stored procedures.
@Jeff,
I do like it without the
cfprefix because the syntax is simpler. But, I don't feel very strongly. Also, having the parens makes it feel like a function call, which it is not.