
Using JSON.stringify() Replacer Function To Recursively Serialize And Sanitize Log Data
Yesterday, I took a look at how the JSON.stringify() method will recurse through an object graph, calling .toJSON() on each node, if it exists. The .toJSON() class methods provide a class-oriented way of customizing the serialization process. But, the JSON object provides another way to customize the serialization process: an optional "replacer" function. The "replacer" concept is very similar - as the stringification process visits each node in the object graph, it will pass the object and its keys to the replacer where they can be altered or replaced. It occurred to me that this would be the prefect mechanism for use with log data persistence: an intermediary function that could optimize and sanitize log items.
Good logging is absolutely essential for debugging issues in an application. But, logging is not the easiest feature to implement, especially not in Node.js where the two most important properties of an error object - message and stack - are not enumerable. This means that, on top of issues like PII (Personally Identifiable Information), circular references, and oversized log items, logging errors requires yet additional finesse.
That said, I think we can use the JSON.stringify() replacer function to simplify our lives. With the replacer function, we gain granular control over how data is moved into (or excluded from) the JSON (JavaScript Object Notation) result. This means that we can use the replacer function to implement:
- Automatic recursive serialization.
- Comprehensive serialization of all Error properties.
- PII sanitization.
- Large-value truncation (not shown in demo code).
To experiment with this, I've created a small demo in which I throw a native Error object which I then chain (as the rootCause) inside a custom AppError object. The AppError instance is then serialized using a replacer function and logged to the console:
// Require the core node modules.
var chalk = require( "chalk" );
var util = require( "util" );
// ----------------------------------------------------------------------------------- //
// ----------------------------------------------------------------------------------- //
// I provide a custom Error object that allows for more detail to be included with the
// Error object.
class AppError extends Error {
constructor( settings = {} ) {
// Pass the message up to the base constructor.
settings.type
? super( `Domain Error: ${ settings.type }` )
: super( `Technical Error` )
;
this.name = this.constructor.name;
this.detail = ( settings.detail || null );
this.extendedInfo = ( settings.extendedInfo || null );
this.rootCause = ( settings.rootCause || null );
Error.captureStackTrace( this, this.constructor );
}
}
// ----------------------------------------------------------------------------------- //
// ----------------------------------------------------------------------------------- //
// I provide a means to serialize log items for log persistence.
class LogItemSerializer {
// I serialize the given log item, returns the String version.
serialize( logItem ) {
try {
var serializedLogItem = JSON.stringify(
logItem,
// CAUTION: When the "replacer" function is invoked from within the native
// JSON.stringify() internals, the "this" context is [typically] the object
// in which the "key" was found. However, in this case, since we're using a
// FAT ARROW FUNCTION, the "this" reference will be bound to the current
// class [LogItemSerializer] instance. We are purposefully overriding the
// default behavior of the serializer so that we can call other class
// methods like _exposeErrorProperties().
( key, value ) => {
return( this._jsonReplacer( key, value ) );
},
4 // NOTE: Only using pretty-print for DEMO.
);
return( serializedLogItem );
} catch ( serializationError ) {
// If the JSON.stringify() method failed due a circular reference error,
// let's fall back to use the native node inspect method.
// --
// CAUTION: By using the util.inspect() method, we will lose out on the
// sanitization process. This means that we may end of persisting sensitive
// data like passwords, emails addresses, and credit card numbers. That said,
// the chances of running into a circular reference errors is extremely low!
if ( this._isCricularReferenceError( serializationError ) ) {
var serializedLogItem = JSON.stringify(
{
json: "failed",
inspect: util.inspect( logItem )
},
null,
4 // NOTE: Only using pretty-print for DEMO.
);
return( serializedLogItem );
}
throw( error );
}
}
// ---
// PRIVATE METHODS.
// ---
// I return a copy of the given Error class as a plain-old JavaScript object (POJO)
// that includes all of the fields that we want to serialize. The copy operation
// ensures that all relevant - INCLUDING NON-ENUMERABLE - fields are made available.
_exposeErrorProperties( error ) {
var copy = Object.assign( {}, error );
// In the native Error class (and any class that extends Error), the
// following properties are not "enumerable". As such, they won't be copied by
// the Object.assign() call above. In order to make sure that they are included
// in the serialization process, we have to copy them manually.
( error.name ) && ( copy.name = error.name );
( error.message ) && ( copy.message = error.message );
( error.stack ) && ( copy.stack = error.stack );
return( copy );
}
// I determine if the given key should be blacklisted from logging (because it is
// MORE LIKELY to contain sensitive information that we don't want persisted outside
// of our system boundary).
_isBlacklisted( key ) {
key = key.toLowerCase();
return(
/creditcard/.test( key ) ||
/email/.test( key ) ||
/expiration/.test( key ) ||
/password/.test( key ) ||
/ssn/.test( key )
);
}
// I determine if the given error is due to a circular reference error in an object
// that is trying to be serialized.
_isCricularReferenceError( error ) {
return( error.message.toLowerCase().includes( "circular structure" ) );
}
// I am the replacer method being used by JSON.stringify().
_jsonReplacer( key, value ) {
// If it's an error, ensure that all properties are made available.
if ( value instanceof Error ) {
return( this._exposeErrorProperties( value ) );
} else if ( key && this._isBlacklisted( key ) ) {
return( "[sanitized]" );
} else {
return( value );
}
// TODO: Consider adding truncation (or blacklisting) of really massive values.
// Large items can bog down your log aggregation engine and eat up storage and
// indexing costs.
}
}
// ----------------------------------------------------------------------------------- //
// ----------------------------------------------------------------------------------- //
try {
// Here, we're going to wrap a native Error instance inside our AppError instance
// so we can see that the JSON.stringify() method recurses through each object.
try {
throw( new Error( "NetworkError" ) );
} catch ( innerError ) {
throw(
new AppError({
type: "RepositoryError",
rootCause: innerError,
extendedInfo: {
context: "Demo for JSON replacer.",
email: "missy@test.com",
password: "icantstandtherain/gainstmywindow"
}
})
);
}
} catch ( error ) {
var serializedLotItem = new LogItemSerializer().serialize( error );
console.log( colorizeForDemo( serializedLotItem ) );
}
// ----------------------------------------------------------------------------------- //
// ----------------------------------------------------------------------------------- //
// I colorize the log-output for easier reading in the demo. This turns the keys into
// colorized BOLD text. This only works because we know that the value serialized using
// the "pretty print" with indentation (hence the multi-line RegExp pattern).
function colorizeForDemo( output ) {
var replacement = output.replace(
/^(\s+")([^"]+)(":)/gm,
function( $0, pre, key, post ) {
var color = ( key === "rootCause" )
? chalk.cyan.bold
: chalk.red.bold
;
return( pre + color( key ) + post );
}
);
return( replacement );
}
The actual serialization process is being encapsulated inside the LogItemSerializer class since the means of generting JSON is an implementation detail that the calling context doesn't need to know about. Ultimately, however, the LogItemSerializer does little more than proxy the call to the JSON.stringify() method using the following replacer:
// I am the replacer method being used by JSON.stringify().
_jsonReplacer( key, value ) {
// If it's an error, ensure that all properties are made available.
if ( value instanceof Error ) {
return( this._exposeErrorProperties( value ) );
} else if ( key && this._isBlacklisted( key ) ) {
return( "[sanitized]" );
} else {
return( value );
}
// TODO: Consider adding truncation (or blacklisting) of really massive values.
// Large items can bog down your log aggregation engine and eat up storage and
// indexing costs.
}
Here, you can see that if the current value - in the object graph being serialized - is an instance or subclass of the Error class, I return a shallow copy of the Error object in which the "name", "message", and "stack" properties are explicitly copied. By copying these properties out of the error and into the POJO (Plain-Old JavaScript Object), it makes the properties enumerable during the serialization process. This allows the JSON.stringify() method to move these properties into the JSON result.
Notice, also, that the replacer function is a perfect place to blacklist certain values that contain sensitive information like password and email address. You could also implement the large-value truncation here by checking value.length; but, that's more of a fuzzy concern, so I chose not to include it in this exploration (see video).
That said, when we run the above code through node.js, we get the following terminal output:
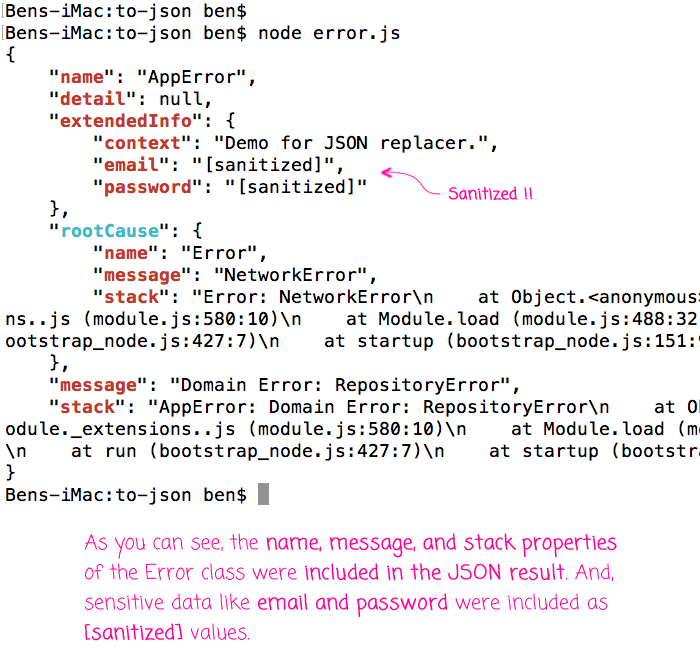
As you can see, then entire AppError object gets included in the serialized, JSON result. This includes the traditionally non-enumerable properties like "message" and "stack" as well as the rootCause Error object. And, we were able sanitize PII / sensitive data like "email" and "password".
For this demo, I am trying to be extra safe with my call to JSON.stringify(). The JSON.stringify() method does not offer a "Never Throw Guarantee" because it can't handle circle references. As such, if the JSON.stringify() call fails, I'm falling back to using Node's util.inspect() method. This method doesn't offer us a replacer hook; but, it will handle circular references. As such, it means we'll be able to get something in the logs, even if the logged data is less consumable and contains sensitive information.
Of course, this fall back may be overkill since the chance of hitting a circular reference in the data that your own application is logging is fairly low. That said, I'm including here if, for no other reason, to showcase the fact that this scenario is possible.
The replacer function option for the JSON.stringify() method is awesome. It handles the problem of recursion during the serialization process; and, it gives us powerful hooks that offer fine control over how the data is serialized, including which values are included or excluded. This makes it a great resource when it comes to logging data that may contain nested errors and sensitive information.
Want to use code from this post? Check out the license.

Reader Comments
@All,
One note about the util.inspect() method. It looks like it defaults to "2" in terms of the depth that it will recurse. But, this can be overridden by setting the options.depth. If you want to remove the limit you can set options.depth to null (according to the docs).