
Experimenting With Russian Doll Error Reporting In Node.js
Often times, when an error occurs in a Node.js application it is either passed, as-is, up the call stack (via callbacks or Promises); or, it is caught and a new error object is created and passed back. On their own, each one of these approaches works well enough. But, sometimes it would be great to get the best of both worlds: the originating error object plus some context-specific data. To explore this idea, wanted to look at some "Russian Doll" inspired error handling in which errors can be nested.
In the past, I've looked at creating custom error objects, in Node.js, using Error.captureStackTrace(). For this experiment, I'd like to bring that back; but, add an additional error property: rootCause. In this context, rootCause is just another error object. It could be a native error object; or, it could be another instance of "AppError." The point is, this property allows for error nesting. Each error can contain a rootCause, which itself may contain a rootCause, and so on.
// Require our core node modules.
var util = require( "util" );
// Export the factory function.
exports.createAppError = createAppError;
// Export the constructor function.
exports.AppError = AppError;
// ----------------------------------------------------------------------------------- //
// ----------------------------------------------------------------------------------- //
// I create a new instance of the AppError object.
function createAppError( settings ) {
// NOTE: We are overriding the "implementationContext" so that the createAppError()
// function is not part of the resulting stack trace.
return( new AppError( settings, createAppError ) );
}
// I am the custom error object for the application. The settings is a hash of optional
// properties for the error instance:
// --
// * type: I am the type of error being thrown.
// * message: I am the reason the error is being thrown.
// * detail: I am an explanation of the error.
// * extendedInfo: I am additional information about the error context.
// * errorCode: I am a custom error code associated with this type of error.
// * rootCause: I am the originating error that is being wrapped up in a new error.
// --
// NOTE: The implementationContext argument is an optional argument that can be used
// to trim the generated stack trace. If not provided, it defaults to AppError.
function AppError( settings, implementationContext ) {
// Ensure that settings exists to prevent reference errors.
settings = ( settings || {} );
// Override the default name property (Error). This is basically zero value-add.
this.name = "AppError";
// Set up the sub-classed error properties.
this.type = ( settings.type || "Application" );
this.message = ( settings.message || "An error occurred." );
this.detail = ( settings.detail || "" );
this.extendedInfo = ( settings.extendedInfo || "" );
this.errorCode = ( settings.errorCode || "" );
// I am the originating error object that is being wrapped up. This allows each
// error instance to include additional information without losing insight into the
// original error deep down in the call stack.
this.rootCause = ( settings.rootCause || null );
// This is just a flag that will indicate if the error is a custom AppError.
this.isAppError = true;
// Capture the current stack trace and store it in the property "this.stack". By
// providing the implementationContext argument, we will remove the current
// constructor (or the optional factory function) line-item from the stack trace;
// this is good because it will reduce the implementation noise in the stack property.
Error.captureStackTrace( this, ( implementationContext || AppError ) );
}
util.inherits( AppError, Error );
Once we have this nesting-enabled error object, we can then start to "roll up" errors as they move back up the call stack. At each call-level, we can chose to either pass-through the originating error; or, we can create a new instance of AppError, with contextual data points, and store the originating error as the "rootCause".
Once the error bubbles back up to a point within the application control-flow where it can be logged, we have to reverse the process to some degree. Since the "stack" property of the error object is not enumerable, we have to "unroll" the error before it can be properly logged. This means recursively walking through the rootCause tree and ensuring each error property is copied over into the current log entry.
To see this in action, I've created a small demo in which an error is triggered due to invalid data. This error is caught, wrapped, and passed back up the call stack where it is logged:
// Require our core node modules.
var util = require( "util" );
// Require our core application modules.
var createAppError = require( "./app-error" ).createAppError;
// ----------------------------------------------------------------------------------- //
// ----------------------------------------------------------------------------------- //
try {
// NOTE: We know this is going to fail since "null" is not a valid name.
createFriend( null );
} catch ( createError ) {
logError( createError );
}
// I attempt to create a friend with the given name.
function createFriend( name ) {
try {
validateName( name );
// Rather than just letting any validation errors bubble back up, we're going to
// catch them and wrap them in a custom error with invocation-specific data.
} catch ( validationError ) {
// NOTE: When I throw the error, I am including the validation error as the
// "root cause" of the problem. This way, we will be able to log instance-
// specific data without losing the underlying error.
throw(
createAppError({
type: "App.InvalidArgument",
message: "Name is not valid",
detail: util.format( "The argument name [%s] is not valid.", String( name ) ),
extendedInfo: util.inspect( arguments ),
rootCause: validationError
})
);
}
// ... create the friend (not the point of the demo).
}
// I validate the given friend name.
function validateName( name ) {
// CAUTION: If name is NULL, .length call will fail.
return( name.length && ( name.length < 100 ) );
}
// ----------------------------------------------------------------------------------- //
// ----------------------------------------------------------------------------------- //
// I log the given error to the console.
function logError( error ) {
var logEntry = {
_time: Date.now(),
_pid: process.pid,
_level: "error"
};
// Since this may be an instance of our custom AppError error object, including
// referencing to underlying root-cause errors, we need to "unroll" the error,
// making sure all of the data points of loggable.
logEntry.error = unrollError( error );
console.error( logEntry );
}
// I unroll the error, making sure that it, as well as any embedded root-cause errors
// are accessible from a serialization / stringification standpoint.
function unrollError( error ) {
// If this isn't an instance of the Error object, just return it - we don't know
// enough about it, otherwise, to be able to ensure key transfers.
if ( ! ( error instanceof Error ) ) {
return( error );
}
var errorData = {};
// Copy over the natively enumerable data points.
for ( var key in error ) {
errorData[ key ] = error[ key ];
}
// Since the stack trace on an error object doesn't appear to be an enumerable
// property during serialization, let's check to see if it was copied over during
// the key iteration above. If not, let's manually copy it. We're gonna need this
// value in order to get use out of logging.
if ( error.stack && ! errorData.stack ) {
errorData.stack = error.stack;
}
// Since our custom application errors have the opportunity to append the
// underlying root error, we should try to unroll that as well, if it exists.
// This way, errors can be passed back up the stack for more clarity.
// --
// NOTE: We are recursively unrolling errors which means that this "root cause"
// error can be another custom application error that, itself, has a root cause.
if ( error.rootCause ) {
errorData.rootCause = unrollError( error.rootCause );
}
return( errorData );
}
As you can see, this code will throw an error because ".length" cannot be called on "null". When that error is caught, it is wrapped inside an AppError instance which records more of the contextual data before rethrowing, so to speak, the error. And, when we run the above code, we get the following terminal output:
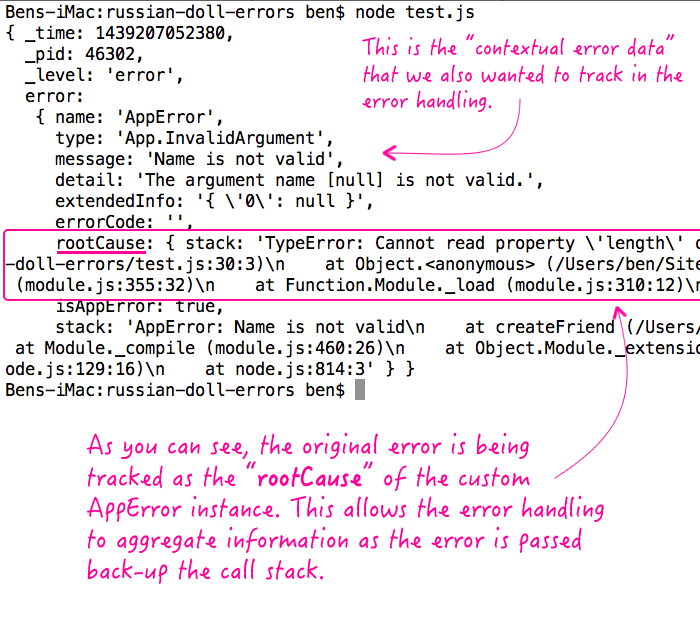
As you can see, the underlying error was recorded as the "rootCause" of the error that was eventually logged. This allows us to see both the actual error as well as any other data that might be relevant for debugging.
I am not saying that this kind of "Russian Doll" approach makes sense all of the time. But, that's kind of the beauty of the error handling - it's entirely optional. If you need it, you wrap the originating error; if you don't, you just pass it through or let it go entirely unhandled. It's a value-add only when it needs to be.
Want to use code from this post? Check out the license.

Reader Comments
This is a very useful pattern! This encourages you to catch errors, describe them yourself, but without losing the stack or original cause. Nice!
@Scott,
Thank you kind sir. I've been finding this especially helpful when I need to know more about the context in which the error occurred. Often time, the actual originating error will just tell me that something went wrong, but not give me enough "why" data.
Did you give simple exception handling example