
Parsing GitHub Gist Embeds Into A Normalized Data Structure Using jSoup In ColdFusion
As I mentioned yesterday, I've been using GitHub Gists to add the syntax highlighting / formatting in my blog post content. This has been working great; but, I've never liked the idea of having to reach out to a 3rd-party system at render time in order to provide my full content experience. As such, I've been considering ways to cache the GitHub Gist data locally (in my system) for both better control and better performance. Unfortunately, GitHub Gists aren't provided in the most user-friendly format. To that end, we can use jSoup in ColdFusion to read-in, parse, and normalize the Gist contents.
When you create a GitHub Gist and then go to embed it, what you get is a JavaScript file resource. Something like this (I've removed the host for brevity):
/bennadel/b41f05e9e5aef523153ef2c2a41efcb3.js
If you try to load this JavaScript file, what you get is a series of document.write() calls that render the Gist data inline into the current website. Not only is the document.write() call a serious "code sell", this approach severely limits your ability to alter the way in which the embed is rendered.
Thankfully, we can access the Gist Embed data more directly by replacing the .js file extension with a .json file extension:
/bennadel/b41f05e9e5aef523153ef2c2a41efcb3.json
Hitting this .json URL gives us the following JSON (JavaScript Object Notation) payload:
descriptionpublic(boolean)created_atfiles- An array of the names of the files contained within the embed. This list appears to be in the same order as the code snippets (which will become helpful in our parsing).ownerdiv- A string that contains the HTML for all of the files contained within the embed.stylesheet- A URL to the CSS stylesheet needed to format the Gist content.
The main problem with this data structure is the div property. It's just one large HTML string that contains all of the files defined within our GitHub Gist. This would be OK if we didn't care how the data was being rendered. But, in my case, I need to pick the Gist data apart and surgically interpolate each file, individually, into my blog post.
To do this, I'm going to use jSoup to parse the div string, locate each file node, and then extract it into its own HTML payload. Then, once I have the Gist data collated into a predictable data structure, I'm going to output it to the page:
NOTE: For the sake of simplicity, I'm leveraging the fact that ColdFusion can treat remote URLs like files. And, I'm using a vanilla
fileRead()operation in order to download the remote file data. In a production setting, you would want to useCFHttpin order to apply more fine-grained control over failure cases.
<cfscript>
// This is the EMBED URL, except I've replaced the ".js" extension with ".json". This
// provides us with the Gist data in a quasi-usable data format.
// --
// CAUTION: For simplicity of demo, I'm using ColdFusion's ability to read remote
// files using the file I/O functions.
gistData = deserializeJson(
fileRead(
"https://gist.github.com/bennadel/b41f05e9e5aef523153ef2c2a41efcb3.json"
)
);
// All of the files in the Gist are rendered inside a single "div" property. In order
// to make them more accessible / consumable, I'm going to parse the "div" property
// and then break each file out into its own container.
gistDoc = javaNew( "org.jsoup.Jsoup" )
.parseBodyFragment( gistData.div )
;
// When the GitHub gist is rendered, it uses "white-space: pre" in order to maintain
// indentation on a given line of code. By default, jSoup will remove leading and
// trailing white space (during serialization of nodes) since it doesn't know anything
// about CSS. In order to get jSoup to keep the leading white space / indentation, we
// have to disable the pretty-print feature.
gistDoc.outputSettings().prettyPrint( false );
// Now, we want to locate each file NODE within the monolithic "div" DOM tree and map
// it onto a normalized data structure.
files = gistDoc
.select( ".gist-file" )
.map(
( fileNode, i ) => {
// When the Gist embed is delivered, all of the files are wrapped in a
// common parent. However, now that we want to break the Gist up into
// separate files, we need to re-wrap each file in the expected parent.
// This is done primarily for CSS / styling reasons.
fileNode = fileNode
.wrap( "<div class='gist'></div>" )
.parent()
;
// Since there's no JavaScript in the embed, there's no need to have
// templates - not sure what purpose these would be serving (in our case).
// They won't cause harm to be left in; but, they are added bloat.
fileNode
.select( "template" )
.remove()
;
// We are taking it on faith that the file-names and the gist-files are
// listed in the same order (this is not documented, but appears to be
// consistent).
return([
name: gistData.files[ i ],
htmlContent: fileNode.outerHtml()
]);
}
)
;
// Each Gist comes with its own stylesheet reference.
// --
// NOTE: I do not know how unique this stylesheet content is. The filename appears to
// contain a hash (likely related to the contents of the stylesheet). As such, if I
// were going to cache this locally, I'd likely use a hash of the content as well in
// order to de-duplicate stylesheets across Gists. Also, by caching the CSS locally,
// we will be breaking the "sourceMappingURL" value.
cssContent = fileRead( gistData.stylesheet );
// ------------------------------------------------------------------------------- //
// ------------------------------------------------------------------------------- //
// At this point, we've read-in and parsed our GitHub Gist data into a predictable,
// consumable data structure. Now, we can render it however we want. Note that we are
// rendering each file separately.
```
<cfoutput>
<style type="text/css">
#cssContent#
</style>
<!---
In order to override CSS properties in the Gist Embed stylesheet, we have to
scope them to the BODY (as one means to increase the specificity of our styles
vs the provided styles).
--->
<style type="text/css">
body .gist .gist-file {
border: 4px solid hotpink ;
}
</style>
<h1>
Gist: #encodeForHtml( gistData.description )#
</h1>
<p>
There are #numberFormat( files.len() )# file(s) in this Gist.
CSS content hash: #hash( cssContent ).lcase()#
</p>
<cfloop index="i" value="entry" array="#files#">
<h2>
(File #i#): <code><mark>#encodeForHtml( entry.name )#</mark></code>
</h2>
#entry.htmlContent#
</cfloop>
</cfoutput>
```
// ------------------------------------------------------------------------------- //
// ------------------------------------------------------------------------------- //
/**
* I create a new Java class wrapper using the jSoup JAR files.
*/
public any function javaNew( required string className ) {
var jarPaths = [
expandPath( "./jsoup-1.16.1.jar" )
];
return( createObject( "java", className, jarPaths ) );
}
</cfscript>
As you can see, I'm using jSoup to parse the div string into a Document Object Model (DOM) tree. Then, I'm locating each file via the CSS selector, .gist-file, where I can extract its HTML content. And, once I've collected all the files, I'm just looping over them and outputting them to the screen:
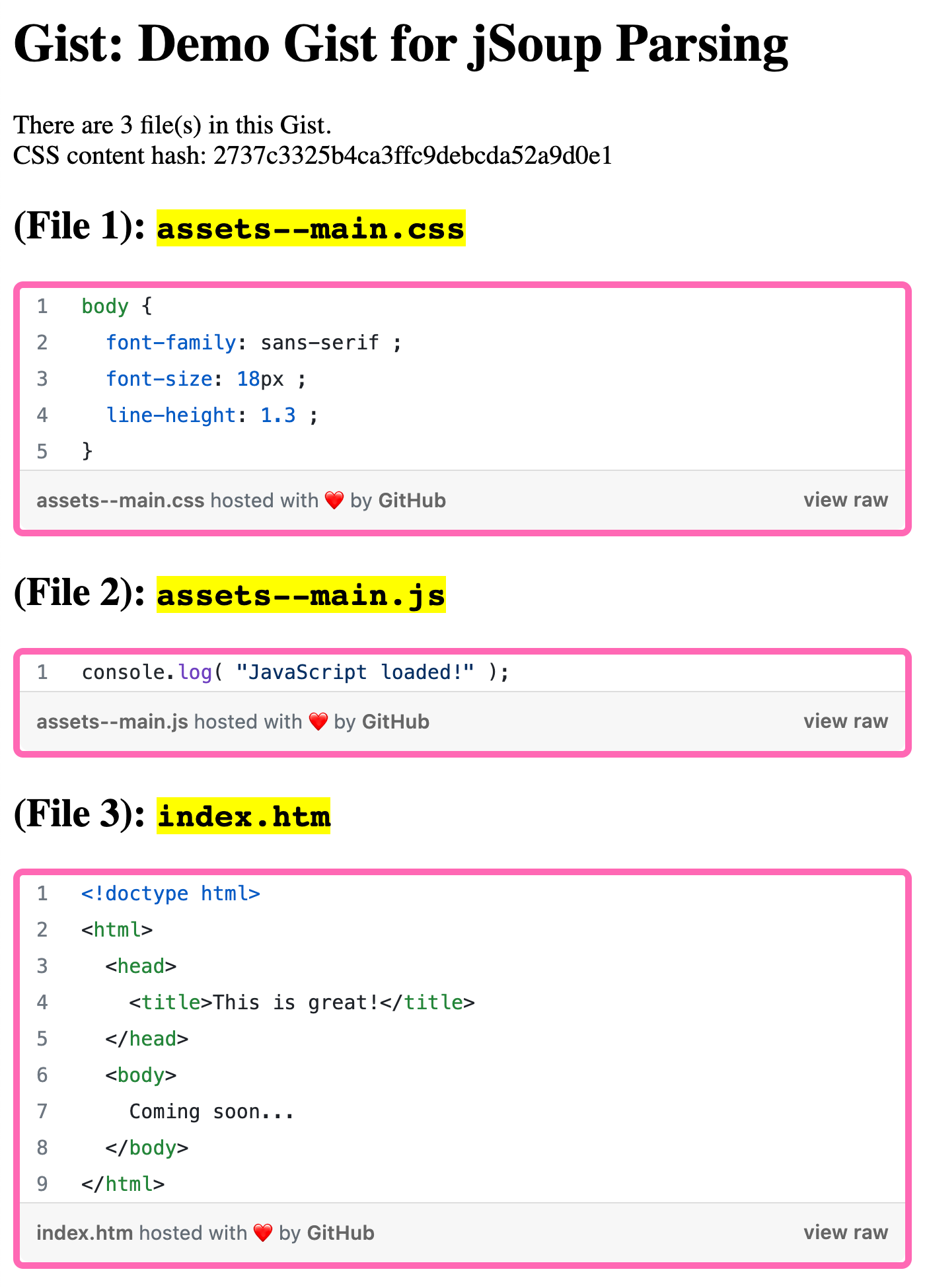
In this demo, I'm just outputting the files in turn; but, now that I have them associated with a filename, I can easily index them and then output them in any order that I want (or, in my case, replace them into the blog content at their appropriate location).
Want to use code from this post? Check out the license.

Reader Comments
Post A Comment — ❤️ I'd Love To Hear From You! ❤️
Post a Comment →