
Ask Ben: Converting An XML Document Into A Nested ColdFusion Struct
It's been a long, long time since I've done an Ask Ben question; but, I recently received a question about XML document parsing in ColdFusion and I thought this would be a good opportunity to get back into the swing of things. In this post, I'm going to be using a recursive, depth-first traversal algorithm to iterative create a nested structure based on the an XML configuration document.
ASK BEN: I have created an XML document that I am going to use as a config file for an application. Ultimately creating an "application" scoped struct of settings. The problem is, that if the XML is nested I only ever get the last node. However if I add a "writeLog" to the loops, I can see all nodes and their values at all depths. The following is the XML and the CFML (Lucee) that I am using.
The ColdFusion XML parsing code submitted with this question (not shown here) was a series of nested for-loops. When dealing with a complex and open-ended structure like an XML document, nested loops can only get you so far because they bake assumptions into the structure of the document. And, if the structure of the document ever changes, you need to update your parsing algorithm to accommodate those changes.
Instead of using hard-coded for-loops, we can use recursion to walk over the nodes in the XML document, generating nested ColdFusion ordered structs as we go. Recursion can be a tricky thing to wrap your head around. But, I believe that when you see the code below you will actually find it quite straightforward.
Now, before we look at any code, we have to make some assertions about how our XML-to-Struct algorithm is going to work. The general complication with this type of problem is that XML documents don't map cleanly onto structs. While structs contain Names and Values, XML documents contains Names, Values, and Attributes. As such, to represent an XML document as a struct, we need to be explicit in how we simplify the data as we map it. Otherwise, we end up creating a new structure that is just as complex as the original XML document. In which case, the mapping would be a waste of time.
With our approach, we are making these XML-to-Struct mapping assertions:
We are not going to use XML attributes at all - all values will, ultimately, be reported as text (though perhaps in nested structures).
An XML node has either "text" or "children", but not both. This distinction will be based on whether or not the child-node collection length is non-zero.
XML children will be aggregated as a Struct, not as an Array. As such, all nodes in the same child-node collection must be uniquely named otherwise they will overwrite each other in the mapping.
All recursive algorithms must have a base case - a condition under which the recursive calls halt and a known value is returned. Given our mapping assertions, this is our base case:
! node.xmlChildren.len()
When a given XML node has no children, we have reached a leaf node at the bottom of an XML branch. In this base case, our recursive algorithm returns the .xmlText of the node instead of making any further recursive calls:
If there are children in the XML node, we need to aggregate those children into a Struct. In this case, we're going to use an ordered struct so that the key-iteration of our struct matches the order of the XML nodes in the original document. This is not necessary, per say, but it's nice stylistically.
Since each node may contain either text or other XML nodes, getting value of a node is where the recursion comes into play:
<cfscript>
public any function getXmlNodeValue( required xml node ) {
// Since we are performing a depth first traversal through the XML structure, our
// recursive BASE CASE is when we hit a node that has no children. In that case,
// we're going to use the node text as the value rather than recurse through the
// the children.
if ( ! node.xmlChildren.len() ) {
return( node.xmlText.trim() );
}
var result = [:];
for ( var childNode in node.xmlChildren ) {
// Traverse each child node, RECURSIVELY calling this function in a DEPTH
// FIRST workflow - each value here may become a string or another struct.
result[ childNode.xmlName ] = getXmlNodeValue( childNode );
}
return( result );
}
</cfscript>
Here, we have a ColdFusion user defined function (UDF) called getXmlNodeValue(). Notice that when we are aggregating our XML child nodes in the for-loop, we're calling this same getXmlNodeValue() function with the "next node down" as its argument. This recursion will continue until it hits the "base case", returns the .xmlText value, which will then allow the for-loop to move onto the next node in the child-node iteration.
Many recursive algorithms require two functions: one to perform the recursive calls and one to initiate the recursive state. This is true in our case as well - we need another function that kicks-off the iteration and creates the root-struct. After all, we always want our mapping function to return a Struct even though the base-case recursion returns a String (.xmlText).
This initiation method does nothing more than setup the struct and make the first recursive call:
<cfscript>
public struct function getXmlAsStruct( required xml document ) {
return({
"#document.xmlRoot.xmlName#": getXmlNodeValue( document.xmlRoot )
});
}
</cfscript>
As you can see, this sets up our root struct and initiates the recursive tree walk using the .xmlRoot of the XML document. The result of that recursive call may be a String or it may be a Struct; but, in either case, our top-level function call will always return a Struct using the root node-name as the only key in the mapped value.
Recursion is one of those topics that sounds very complicated; and, it's an approach that can be hard to visualize in your head; but, I'm hopeful that seeing the above methods has removed a good deal of trepidation. As long as you can boil recursion down to a simple base case, thinking through the algorithm becomes a much more tractable problem.
With all that said, let's look at the overall algorithm that maps an actual XML document onto a ColdFusion struct:
<cfxml variable="doc">
<aws>
<vpc>My VPC data</vpc>
<instance>My Instance data</instance>
<privateIp>My Private IP</privateIp>
<publicIp>My Public IP</publicIp>
<region>My Region</region>
<s3>
<apiEndPoint />
<apiKey />
<accessKeyId />
<secretKey />
<bucketName />
<audio>
<bucketName>My Audio bucket</bucketName>
<regionName>My Audio region</regionName>
</audio>
<voc>
<bucketName>My VOC bucket</bucketName>
<regionName>My VOC region</regionName>
</voc>
</s3>
</aws>
</cfxml>
<cfscript>
writeDump( getXmlAsStruct( doc ) );
// ------------------------------------------------------------------------------- //
// ------------------------------------------------------------------------------- //
/**
* I convert the given XML document to a Struct.
*
* ASSUMPTIONS: This XML document does NOT USE attributes to convey information. All
* information is defined in the XML node names and the XML text values. As such, any
* nodes with the same name as the same level will overwrite each other.
*/
public struct function getXmlAsStruct( required xml document ) {
// NOTE: For the child nodes, we're going to use an ORDERED STRUCT so that the
// iteration order of the keys matches the order of the XML nodes. However, for
// the root node, we don't need it to be ordered since there is only one key.
return({
"#document.xmlRoot.xmlName#": getXmlNodeValue( document.xmlRoot )
});
}
/**
* I recursively translate the given XML node into either a simple text value or a
* struct of nested values.
*/
public any function getXmlNodeValue( required xml node ) {
// Since we are performing a depth first traversal through the XML structure, our
// recursive BASE CASE is when we hit a node that has no children. In that case,
// we're going to use the node text as the value rather than recurse through the
// the children.
if ( ! node.xmlChildren.len() ) {
return( node.xmlText.trim() );
}
var result = [:];
// NOTE: If we wanted to incorporate the XML attributes into this algorithm, we
// could do something like this, where we just append the key-value attribute
// pairs to the pending result. Doing it HERE would put attributes at a lower
// precedence than the child-nodes (which could overwrite them).
// --
// result.append( node.xmlAttributes );
for ( var childNode in node.xmlChildren ) {
// Traverse each child node, RECURSIVELY calling this function in a DEPTH
// FIRST workflow - each value here may become a string or another struct.
result[ childNode.xmlName ] = getXmlNodeValue( childNode );
}
return( result );
}
</cfscript>
Now, when we run this Adobe ColdFusion 2021 we get the following page output:
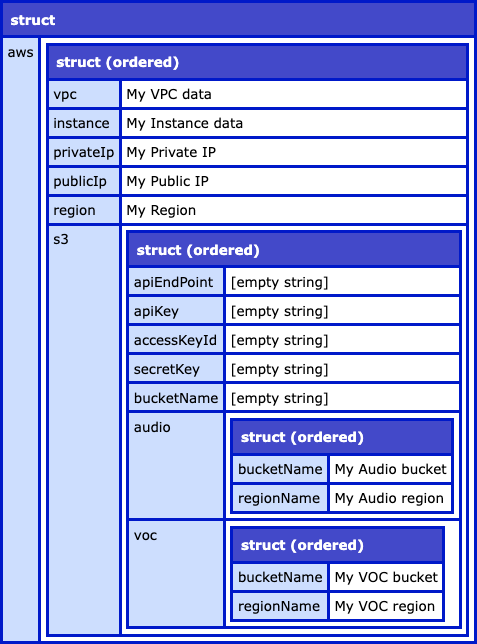
As you can see, we've taken our arbitrarily nested XML document and converted it into an arbitrarily nested ColdFusion struct (given our set of assumptions and constraints about the "lossy" mapping algorithm).
Epilogue on Replacing Recursion With Looping
At the top of this post, I said that using nested for-loops was problematic with an arbitrarily nested structure because you have to keep adding another loop for every depth of your input. This, however, doesn't mean that you can't replace recursion with looping. You can - only not with for-loops. You can replace recursion with a while loop by tracking the "known unknown" nodes within a tree structure. This is true for both depth-first and breadth-first tree traversal.
That said, using a while-loop is somewhat more complicated and harder to follow. But, it is more memory efficient since it doesn't grow the call-stack for each new node to explore.
Want to use code from this post? Check out the license.

Reader Comments
Hi Ben,
Absolute champion. Thanks very much. I sincerely appreciate the time you spent on helping me out.
As you assumed; I have only used the element name and text - no attributes. And I used the for loops because I knew the max depth of the xml tree. And since I was having issues with getting it to work - the loops (with a writeLog() of the xmlName and xmlText) Proved to describe the XML doc perfectly. Thus my confusion when trying to get ALL the nodes into the struct.
As an aside I am learning Scala and Functional Programming at the moment and it still didn't occur to me to use recursion in this instance!
Sincerely thanks very much again - I really love it when I am able to learn something new.
@Gavin,
Absolutely my pleasure, good sir! You've actually inspired me to try and open my "Ask Ben" form again - or merge it with the Contact form. This is something I'd like to put more effort into.
Hi Ben,
How would you adapt this in the event that one of the sub structures has keys of the same name?
@Ross,
Good question. I think there's probably two possible approaches:
"Last one wins" - where the last child with a given name overwrites whatever values existed before hand.
Instead of a simple key-value relationship, the value would be an array of values. This is, I think, how HTTP Headers work. Normally, an HTTP header is just a simple value; but, if you have headers of the same name, they get condensed down into an array of values.
Or, you could just throw an error and consider the data invalid.
I don't think there's a right option here - depends on what you are expecting in your application.
@Ross,
I hade the same problem with duplicate key names. This did the trick for me.
Thanks Ben for saving me a bunch of time.
@Adrian,
Always glad to help. I am not quite sure that I follow your inner-inner-
ifcondition. You seem to be conditionally settingArrayNew()based on the child-child relationship. But, you're looking at the child name (not the child-child name) when you go to.append()the value. I might just be missing something there. Regardless, it sounds like it's working for you, so that's noice!@Ben,
Great catch, I was missing appending to the array for the current iteration.
it now looks like this....
@Adrian,
Awesome, that makes more sense :D
Hey Ben, I'm trying to make create a loop of some kind over YouTube's playlist XML. Have you ever tried to parse that out into a neat query or loop? That's something the CFM World would love to have!
https://dev.lucee.org/t/pulling-a-youtube-playlist-xml-into-a-query-result/13814
@Mik, I'll take a look later today (or, at least I'll try 😛).
@Mik,
Ah, checking back on the Lucee Dev list, it loos like you got everything sorted. Great!