
Experimenting With Lazy Queries And Streaming CSV (Comma Separated Value) Data In Lucee CFML 5.3.7.47
CAUTION: I've never actually used "lazy" queries before. And, I've never used them outside of my development environment. As such, this is just me experimenting in public. Do not take anything in this post as a suggestion of best practices. There may also be factual errors in what I discuss.
In my last post, I celebrated the power and simplicity of CSV (Comma Separated Value) data. It's an old data format; and yet, it continues to act as an easy medium for the interoperability of systems. ColdFusion makes generating CSV data effortless. And as I was demonstrating that much over the weekend, it occurred to me that CSV reporting may be a fun context in which to finally try out the lazy queries feature of Lucee CFML.
To create a lazy query, all you have to do is add lazy="true" to the CFQuery tag. Lazy queries work by keeping a reference to the database; and then, reading records only as needed instead of proactively reading all records into memory as part of a single operation. In theory, this can help to reduce the usage of RAM because you don't need to keep records around after they've been consumed.
Lazy queries do have some limitations. Since Lucee CFML won't read all of the records into memory at once, we can't know ahead of time how many rows we'll get. As such, we can't use the .recordCount property until after all rows have been retrieved from the database.
Furthermore, lazy queries do not get wrapped in a two-dimensional structure. From what I can tell, this means that the underlying Java values are not "wrapped" in ColdFusion values. Which means that we don't get to use member methods. Instead, we have to use the built-in functions (BIFs) when manipulating query column values.
NOTE: When you dump-out a lazy query,
NULLvalues look like they areNULL; however, they still present as empty-strings in the code. This is confusing sinceisNull()will returnfalseon these values.
To play with this, I'm going to use a lazy query to read in mock audit-log data. Then, I'm going to convert that audit-log data into a CSV payload and serve it up to the user. Of course, if we serve-up the entire CSV payload at once (as we did in the last post), we somewhat (though not entirely) negate the laziness of the query. As such, I'm going to also incrementally stream the response using the PageContext's output stream.
So, to recap, I'm going to:
Lazily read each audit-log record from the database.
Serialize each individual row as a CSV line-item.
Write the serialized line-item to the output stream of the ColdFusion response.
Close the lazy query.
I don't really have clarity on whether or not I really have to close the lazy query (using queryClose()). I think this might only be necessary if I don't read all the records?
With that said, here's my exploratory ColdFusion code:
<cfscript>
// Allow lazy/non-lazy nature of query to be driven via URL for demo.
param name="url.lazy" type="boolean" default=true;
startedAt = getTickCount();
// Unlike a normal CFQuery execution, a LAZY query does not load all records into
// memory at one time. Instead, it keeps a pointer to the database and reads results
// as necessary from the database. A LAZY query also DOES NOT WRAP the results, which
// means that we are getting the native Java values and cannot use the traditional
// CFML "member methods".
```
<cfquery name="entries" datasource="testing" lazy="#url.lazy#">
SELECT
l.id,
l.userID,
l.eventType,
l.eventMetadata,
l.ipAddress,
l.createdAt,
l.isSuspicious -- May be NULL.
FROM
audit_log l
ORDER BY
l.id DESC
</cfquery>
```
// NOTE: I am using a Try/Catch so that I can make sure that I always call the
// queryClose() function at the end. I am NOT SURE if this is strictly necessary. The
// docs say this is necessary; but, I think it might only be necessary if I don't
// read all the records (since the query seems to auto-close once all the records
// have been returned)????
try {
// Since we're not loading all of the database records into memory at once, we
// want to incrementally stream the response to the user. Otherwise, we end up
// having to aggregate all the records in memory anyway (which counteracts the
// lazy nature of our query). Under the surface of each ColdFusion page request
// is a Java Servlet Response. By, dipping down into the Java layer, we can get
// access to the actual Binary Output Stream to which we can write raw binary
// content. In this case, we're going to create a DataOutputStream which will
// allow us to write our serialized CSV String data to the underlying ColdFusion
// Byte output stream.
cfmlResponse = getPageContext().getResponse();
cfmlOutputStream = cfmlResponse.getOutputStream();
csvOutputStream = createObject( "java", "java.io.DataOutputStream" )
.init( cfmlOutputStream )
;
fieldDelimiter = chr( 9 ); // Tab.
rowDelimiter = chr( 10 ); // Newline.
// NOTE: Unlike in the previous blog post (on CSV generation), where I was using
// the CFContent tag, we don't have access to the body content at this point
// (since we're going to stream it). As such, we have to explicitly provide the
// CFHeader for Content-Type. This also means that we DO NOT have the "Content-
// Length" ahead of time - I am not sure if this will cause an issue with any
// browsers????
header
name = "Content-Type"
value = "text/csv; charset=utf-8"
;
header
name = "Content-Disposition"
value = getContentDisposition( "audit-log-" & now().dateFormat( "yyyy-mm-dd" ) & ".csv" )
;
// Write the header-row to the CSV output stream.
csvOutputStream.writeBytes(
encodeCsvDataRow(
row = [
"ID",
"User ID",
"Event Type",
"Event Metadata",
"IP Address",
"Created At",
"Is Suspicious"
],
fieldDelimiter = fieldDelimiter
)
);
csvOutputStream.writeBytes( rowDelimiter );
csvOutputStream.flush();
cfmlOutputStream.flush();
// As we loop over the LAZY query, Lucee will read records from the database
// pointer as needed. IN THEORY, this should keep the memory consumption lower,
// (though I was not able to see a meaningful different in FusionReactor).
// --
// NOTE: I am not 100% clear on whether or not we can use a FOR-IN loop. As such,
// I'm using the native CFLoop tag.
loop query = entries {
csvOutputStream.writeBytes(
encodeCsvDataRow(
row = [
entries.id,
entries.userID,
entries.eventType,
entries.eventMetadata,
entries.ipAddress,
// CAUTION: Since LAZY queries do not wrap the results, we DO NOT
// GET to use MEMBER METHODS on the query column values - these
// are the raw JAVA types. As such, we have to use the built-in
// functions, instead, when formatting special values.
dateTimeFormat( entries.createdAt, "medium" ),
// If isSuspicious is NULL, leave it blank - we only want to
// populate explicit "Yes" values.
( val( entries.isSuspicious ) ? "Yes" : "" )
],
fieldDelimiter = fieldDelimiter
)
);
csvOutputStream.writeBytes( rowDelimiter );
csvOutputStream.flush();
cfmlOutputStream.flush();
}
} finally {
// For lazy queries, I THINK we have to explicitly close them in order to free up
// the memory.
if ( url.lazy ) {
queryClose( entries );
}
// Close out output streams, and make sure no other data is sent to the browser.
csvOutputStream?.close();
cfmlOutputStream?.close();
}
systemOutput( "Runtime( lazy = #url.lazy# ): #( getTickCount() - startedAt )#", true, true );
// ------------------------------------------------------------------------------- //
// ------------------------------------------------------------------------------- //
/**
* I encode the given collection of values for use in a CSV (Comma Separated Value)
* row. The values are then serialized as a list using the given delimiter.
*
* @row I am the collection being encoded.
* @fieldDelimiter I am the list delimiter used in the encoding.
*/
private string function encodeCsvDataRow(
required array row,
required string fieldDelimiter
) {
var encodedRow = row
.map( encodeCsvDataField )
.toList( fieldDelimiter )
;
return( encodedRow );
}
/**
* I encode the given value for use in a CSV (Comma Separated Value) field. The value
* is wrapped in double-quotes and any embedded quotes are "escaped" using the
* standard "doubling" syntax.
*
* @value I am the field value being encoded.
*/
private string function encodeCsvDataField( required string value ) {
var encodedValue = replace( value, """", """""", "all" );
return( """#encodedValue#""" );
}
/**
* I get the content-disposition (attachment) header value for the given filename.
*
* @filename I am the name of the file to be saved on the client.
*/
private string function getContentDisposition( required string filename ) {
var encodedFilename = encodeForUrl( filename );
return( "attachment; filename=""#encodedFilename#""; filename*=UTF-8''#encodedFilename#" );
}
</cfscript>
As you can see, the lazy attribute in the CFQuery tag is controlled by a URL parameter. I did this so that I might discern a difference in resource utilization between the lazy and non-lazy queries. However, when I open-up FusionReactor locally and interweave two lazy and two non-lazy queries, I don't see much of a difference:
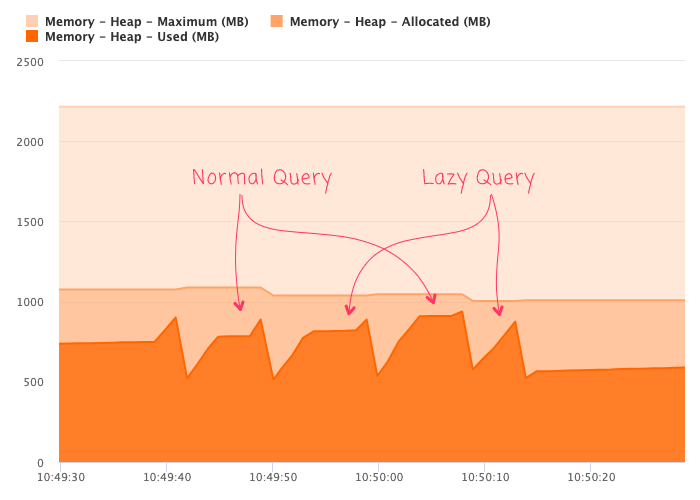
All of the queries have about 50,000 records in them. And, the resultant CSV data files are 4.5MB in size. It's possible that this is just not enough data for the lazy nature of the database read to make a meaningful difference. It's also possible that I am missing something fundamental in this experiment that is causing an issue?
Lazy queries are definitely a curious feature of the Lucee CFML runtime. I don't have any plans to integrate them into my work life at this time; but, it's nice to know that they exist; and, that they might be useful when doing large-scale data-transformation tasks. For small-scale / every-day work, attempting to make queries lazy is almost certainly premature optimization.
Want to use code from this post? Check out the license.

Reader Comments
QueryClose() isn't required, Lucee will close the connection itself, but it's there if you want to manage it yourself
https://luceeserver.atlassian.net/browse/LDEV-2097
https://github.com/lucee/Lucee/commit/dbff9da97c76a47267c074ecfdc76b8934ba4342
As I mentioned on twitter, a good use case for this would be fetching big BLOBs or CLOBs from a database, as you don't want to read them all into memory, using a database cursor (which is what lazy exposes) allows you to efficiently work thru the result set without blowing up your memory usage
@Zac,
Yeah, that's a great use-case. It's been a while since I played around with BLOBs in the DB -- these days, I usually store object-data on S3; but, it's great to keep this in the back of my mind.