
Celebrating The Power And Simplicity Of CSV (Comma Separated Value) Data In Lucee CFML 5.3.7.47
Yesterday, I learned that one of our clients at InVision uses our comment export feature as a critical part of their product development life-cycle. This feature takes comments from across an entire prototype and serves them up as a CSV (Comma Separated Value) file. It's amazing - and, frankly, delightful - that such a simple data format continues to be such a source of empowerment in an increasingly complex world. And, the best part of it all is that generating CSV files is one of the easiest things you can do! As such, I wanted to take a moment to celebrate the power and simplicity of generating CSV files in Lucee CFML 5.3.7.47.
This is certainly not the first time that I've talked about CSV (Comma Separated Value) data on this blog. I've looked at both parsing and generating CSV files in both ColdFusion and JavaScript going back all the way to 2006! In fact, I think that my post on parsing CSV data in JavaScript (from 2009) has historically been one of my most popular posts. I think this only demonstrates the kind of longevity and power that the the CSV data format affords us as web developers.
At it's heart, the CSV format is just a two-dimensional array of values that get serialized as delimited lists. Each row is serialized as a comma-delimited (or tab-delimited) list. And, each of those lists is then further serialized as a new-line-delimited list. That's basically it! Simple, but super powerful!
So, let's take a look at how I do this in Lucee CFML. For the sake of this demo, I'm not going to run any database queries - I'm just going to create a mock set of rows at the top and then proceed with the serialization and serving-up of the CSV response. The demo has 4 steps:
Gather the raw data, usually from the database.
Prepare the raw data for serialization. For me, this means mapping the raw data onto stringified values. And, making sure that I'm applying the necessary formatting to things like date/time values and replacing enum data with human-friendly names. This may also include sanitizing data. The output of this step is a two-dimensional array with the first item containing the column headers.
Serialize the two-dimensional array as a CSV payload.
Serve up that sweet, sweet CSV data using
CFHeaderandCFContenttags.
I think you'll see that when we break this up into steps and various ColdFusion functions, each individual step is easy to understand. Again, this data format is simple but powerful!
<cfscript>
// Step 1: Gather the raw data from somewhere (probably your database).
users = [
{ id: 1, name: "Sarah ""Stubs"" Smith", role: "Admin", joinedAt: createDate( 2020, 1, 13 ) },
{ id: 2, name: "Tom Titto", role: "Manager", joinedAt: createDate( 2021, 3, 4 ) },
{ id: 3, name: "Kit Caraway", role: "Manager", joinedAt: createDate( 2019, 10, 27 ) },
{ id: 4, name: "Allan Allure, Jr.", role: "Designer", joinedAt: createDate( 2020, 8, 22 ) }
];
// Step 2: Prepare the raw data for encoding. This usually means adding a HEADER row
// and encoding non-string values as strings (such as formatting dates).
rows = [
[
"ID",
"Name",
"Role",
"Joined At"
]
];
for ( user in users ) {
rows.append([
user.id,
user.name,
user.role,
user.joinedAt.dateFormat( "yyyy-mm-dd" )
]);
}
// Step 3: Serialize the row data as a CSV (Comma Separated Value) payload.
csvContent = encodeCsvData(
rows = rows,
rowDelimiter = chr( 10 ),
fieldDelimiter = chr( 9 )
);
csvFilename = ( "users-" & now().dateFormat( "yyyy-mm-dd" ) & ".csv" );
// Step 4: Serve-up that sweet, sweet encoded data!
header
name = "content-disposition"
value = getContentDisposition( csvFilename )
;
// NOTE: By converting the CSV payload into a binary value and using the CFContent
// tag, ColdFusion will add the content-length header for us. Furthermore, the
// CFContent tag will also halt any subsequent processing of the request.
content
type = "text/csv; charset=utf-8"
variable = charsetDecode( csvContent, "utf-8" )
;
// ------------------------------------------------------------------------------- //
// ------------------------------------------------------------------------------- //
/**
* I encoded the given two-dimensional array as a CSV (Comma Separated Value) payload.
* Rows and fields are serialized as lists using the given delimiters. All fields are
* wrapped in double-quotes.
*
* CAUTION: All values are assumed to have ALREADY BEEN STRINGIFIED. As such, if you
* want to have control over how things such as Dates are serialized, then that should
* have already been done prior to calling this function.
*
* @rows I am the two-dimensional collection being encoded.
* @rowDelimiter I am the delimiter used to serialized the encoded rows.
* @fieldDelimiter I am the delimiter used to serialize the encoded fields.
*/
private string function encodeCsvData(
required array rows,
required string rowDelimiter,
required string fieldDelimiter
) {
var encodedData = rows
.map(
( row ) => {
return( encodeCsvDataRow( row, fieldDelimiter ) );
}
)
.toList( rowDelimiter )
;
return( encodedData );
}
/**
* I encode the given collection of values for use in a CSV (Comma Separated Value)
* row. The values are then serialized as a list using the given delimiter.
*
* @row I am the collection being encoded.
* @fieldDelimiter I am the list delimiter used in the encoding.
*/
private string function encodeCsvDataRow(
required array row,
required string fieldDelimiter
) {
var encodedRow = row
.map( encodeCsvDataField )
.toList( fieldDelimiter )
;
return( encodedRow );
}
/**
* I encode the given value for use in a CSV (Comma Separated Value) field. The value
* is wrapped in double-quotes and any embedded quotes are "escaped" using the
* standard "doubling" syntax.
*
* @value I am the field value being encoded.
*/
private string function encodeCsvDataField( required string value ) {
var encodedValue = replace( value, """", """""", "all" );
return( """#encodedValue#""" );
}
/**
* I get the content-disposition (attachment) header value for the given filename.
*
* @filename I am the name of the file to be saved on the client.
*/
private string function getContentDisposition( required string filename ) {
var encodedFilename = encodeForUrl( filename );
return( "attachment; filename=""#encodedFilename#""; filename*=UTF-8''#encodedFilename#" );
}
</cfscript>
As you can see, generating a CSV file is really just a series of map and toList() operations. That's what makes it so magical - that a set of such simple operations can end-up providing so much value for our customers!
Of course, it can get more complicated than this if you start to deal with large volumes of data. But, I wouldn't even worry about that until it becomes an actual constraint. Then, only if you need to, you can start to think about streaming the values instead of compiling them all in memory at one time.
With that said, if we run the above ColdFusion page in the browser, we get prompted to download the following CSV text file:
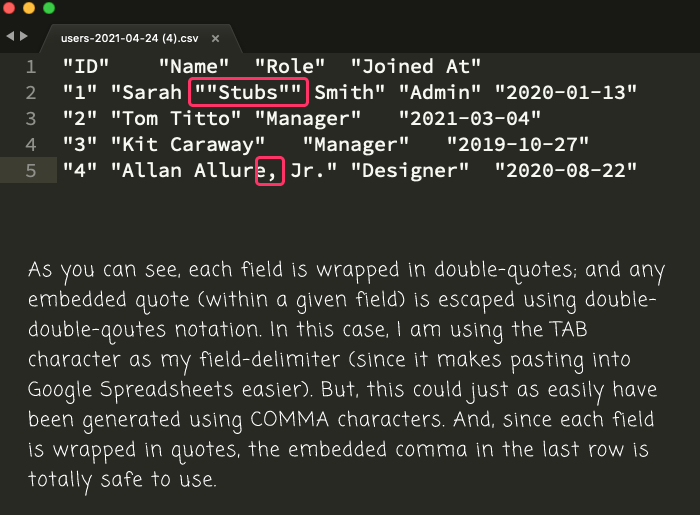
As you can see, each field is wrapped in double-quotes; and, all embedded quotes are escaped using double-double-quote notation. In this case, I opted to use the Tab character, rather than the Comma character, as my field delimiter because it makes copy-pasting into Google Spreadsheets easier. As such, I can copy this data and paste it right into a new Sheet with pain-free abandonment:
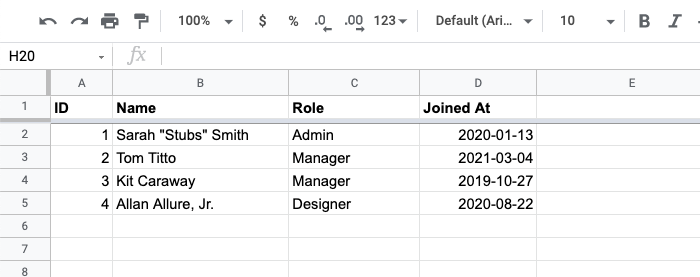
So easy, yet so powerful. And, once a customer has CSV data imported into a spreadsheet program, they get to flex all the slicing-and-dicing Jiu-Jitsu that they've built-up over the years: pivot tables, aggregations, charting, and derived sheets, oh my! I just love how easy Lucee CFML makes this kind of data work.
Epilogue on Providing Clients With Raw Data
Early in my career, the thought of providing a client with raw data was completely abhorrent! Instead of giving them data, what I wanted to do was give them the answers that they were looking for in the raw data. So, I pushed-back - often-times hard - drilling customers with questions about what it was exactly that they were trying to do with the data.
As I've gotten old, fatter, and (hopefully) wiser, I've come to understand that while my early views on data may have been well-intentioned, they were coming from a place of hubris. By assuming that I had the power to solve all my client's needs, I felt that there should be no need to ever provide them with raw data.
Ultimately, it was a lack of empathy on my part. For some clients, raw data is their happy place. And, my job is to make my clients happy. So if data is what does it for them, data is what they get. One of the most important lessons that I've learned in my career is to never be the limiting factor (thank you Carl Wilson). If I have the ability to spark joy in someone, it's never my place to apply arbitrary constraints.
Want to use code from this post? Check out the license.

Reader Comments
If you're generating really large datasets, wrapping all values in quotes can really grow the files size. You should only need to wrap values when they contain double quotes, commas or a CRLF.
I was just working on generating CSVs this week that contains hundreds of thousands of rows and only applying the quoted values when necessary ended up really reducing the file size.
@Dan,
Oh, very interesting point! I don't think I have ever considered that. Usually, I just go with the path-of-least-resistance. I also don't think I deal with such a large volume of data. But, your point makes a lot of sense. And, even if GZip would negate any network-size, once decompressed on the client, it would still be an on-disk file-size issue.
@All,
After writing this post, it occurred to me that CSV data might be a nice context in which to finally experiment with Lazy Queries in Lucee CFML. This is something I found while reading through the documentation; but, couldn't really think of a use-case before:
www.bennadel.com/blog/4034-experimenting-with-lazy-queries-and-streaming-csv-comma-separated-value-data-in-lucee-cfml-5-3-7-47.htm
In theory, a lazy-query could result in lower resource utilization. But, at least locally, I didn't see a difference. Still, an interesting feature to know about!
@All,
On the flip side of generating CSV data is consuming CSV data. Based on some prompting from Adam Cameron, I decided to update my CSV parser for modern ColdFusion:
www.bennadel.com/blog/4037-modernizing-my-csv-comma-separated-value-parser-in-lucee-cfml-5-3-7-47.htm
This is a ColdFusion component that can parse both CSV values and CSV files. I do this much less that generating CSV output; but, still worthwhile nonetheless.
Ben,
That's a lot of wisdom in the epilogue. I try to remember that ultimately we're all on this journey to better understanding of and empathy for each other. Life is sure a lot more satisfying when I do.
@Mark,
100% well said. And, a big part of that is being kind to ourselves when we make mistakes and learn from our past. Sometimes, it's so much easier to have empathy for others than it have leniency for ourselves.
@All,
On the results of our latest PenTest (Penetration Test), something called a CSV Injection Attack (see OWASP) showed up. I had never heard of this attack vector before; but it related to malicious data in a CSV file. I wanted to look at how I can remediate this in ColdFusion:
www.bennadel.com/blog/4330-remediating-csv-injection-attacks-in-coldfusion.htm
Amazing how people find ways to attack a system and/or technology.