
Experimenting With The JSON Column Type In MySQL 5.7.32 And Lucee CFML 5.3.7.47
At InVision, we are in the process of upgrading some of our MySQL database servers from MySQL 5.6.x to MySQL 5.7.32. While this is a "minor" upgrade (done so in order to remain within LTS - long-term support), this update does include something kind of cool: a JSON column type. I've never actually used any official JSON (JavaScript Object Notation) support in a relational database before. So, I thought it would be fun to sit down and try it out in Lucee CFML 5.3.7.47.
While the JSON support in latest version of MySQL - version 8.x - is more robust from what I have read, the initial JSON offering in MySQL 5.7 consists of schemaless validation, some JSON-related access methods, and explicit indexing of "virtual columns". When writing to a JSON column, the database validates that the non-NULL payload is a valid JSON structure; but, it doesn't constrain the contents in any other way. Nor does it require that the structure of the JSON column be the same across all rows in a table. When returning a JSON column value, the payload is returned as a String, leaving serialization and deserialization up to the ColdFusion application server.
Since I've ever experimented with this MySQL feature before, I won't go into any more detail than that. I hope that nothing I said above is overly incorrect.
The benefit - and often the drawback - of working with a schemaless document model is that it is very flexible. In most cases, you don't actually need that kind of flexibility in a data-persistence layer. But, one place that I thought it might be helpful is when storing user preferences and flags. An application's concept of user preferences will almost certainly change over time. And, it would be nice to have a data-persistence layer that rolls along with said evolution.
Take, for example, a flag that will determine if a user has "Seen the intro for Feature X". Early on in the application, "Feature X" didn't exist; so, there was no need to have such a flag. Once "Feature X" is introduced, the intro will only need to be shown to users that actively use the application (ie, old users don't need to know about it). And, in the future, if "Feature X" is ever removed, such a flag will no longer need to be considered.
In a strictly relational context, we could model these types of user-preferences and flags using an Entity-attribute-value model (EAV), where we have a database table with the following columns:
userID- our unique identifier.flagName- our preference or flag name (ex,hasSeenIntro)flagValue- the Stringified value of the given flag (ex,"false").
Then, as new flags are added to the application, it's just a matter of putting a new flagName in the application layer and adding new records - as needed - to our EAV table.
That said, this type of entity-attribute-value model maps really nicely onto the flexibility of a JSON column type. To explore this, let's create a user_flags table that contains a JSON column for these dynamic, key-value pairs:
CREATE TABLE `user_flags` (
`userID` int(11) NOT NULL,
`createdAt` datetime NOT NULL,
`updatedAt` datetime NOT NULL,
`flags` json NOT NULL,
PRIMARY KEY (`userID`),
UNIQUE KEY `byUser` (`userID`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
Now, as we add and remove user preferences and flags for a given user, all we have to do is modify the flags JSON column. However, since we'll want to treat flags as an on demand feature that evolves over time, we do have to take care not to overwrite the existing flags payload. Instead, we'll want to update it with new keys, as needed.
To do this, I'm going to try and use two features together:
An "Upsert" to insert a record, or conditionally update it on key-conflict.
The
JSON_MERGE_PATCH()function to merge twoJSONvalues together.
When used in conjunction, I think we'll be able to add new JSON payloads while safely updating existing JSON payloads that have already been associated with a given user.
To try this approach, I've created a ColdFusion database gateway component that provides various CRUD (Create, Read, Update, Delete) methods for the user_flags table. And, while the JSON column type is inserted and retrieved as a String, I don't want that concept to "leak" too much into the main application logic. As such, this data access gateway (DAG) is going to deal with Structs as inputs and outputs while managing the serialization / deserialization of the JSON behind a layer of encapsulation.
Note that several of these gateway methods call, setUserFlags(), which is our "patching" method that uses ON DUPLICATE KEY UPDATE for the aforementioned "upsert" functionality:
component
output = false
hint = "I provide data persistence methods for user flags."
{
/**
* I delete the given flag for the given user.
*
* @userID I am the user who owns the flags.
* @flagName I am the flag being removed.
*/
public void function deleteUserFlag(
required numeric userID,
required string flagName
) {
// When deleting a key from a JSON column, we need to assign NULL to the value.
// As such, we can just make a "patch" document and then persist it.
setUserFlags(
userID,
{
"#flagName#": nullValue()
}
);
}
/**
* I delete the given flags for the given user.
*
* @userID I am the user who owns the flags.
* @flagNames I am the collection of flags being deleted.
*/
public void function deleteUserFlagMulti(
required numeric userID,
required array flagNames
) {
var patchValue = [:];
// When deleting a key from a JSON column, we need to assign NULL to the value.
// As such, we can just make a "patch" document in which each of the given keys
// is assigned it a NULL value and then persist it.
loop
value = "local.flagName"
array = flagNames
{
patchValue[ flagName ] = nullValue();
}
setUserFlags( userID, patchValue );
}
/**
* I delete all of the flags associated with the given user.
*
* @userID I am the user whose flags are being deleted.
*/
public void function deleteUserFlags( required numeric userID ) {
```
<cfquery name="local.results">
DELETE
f
FROM
user_flags f
WHERE
f.userID = <cfqueryparam value="#userID#" sqltype="integer" />
;
</cfquery>
```
}
/**
* I get the given flag value for the given user. If the user does not have a flag
* with the given name, the empty string is returned.
*
* @userID I am the user who owns the flags.
* @flagName I am the flag being accessed.
*/
public any function getUserFlag(
required numeric userID,
required string flagName
) {
```
<cfquery name="local.results">
SELECT
JSON_EXTRACT( f.flags, <cfqueryparam value="$.#flagName#" sqltype="varchar" /> ) AS flagValue
FROM
user_flags f
WHERE
f.userID = <cfqueryparam value="#userID#" sqltype="integer" />
;
</cfquery>
```
// NOTE: The database driver always returns JSON payloads - even sub-paths - as a
// String. As such, we need to convert the value back to its native type.
return( deserializeJson( results.flagValue ) );
}
/**
* I get the given flags for the given user. While the flag names are provided as an
* Array, the method returns a Struct in which each flag name is mapped to the
* associated value in the user's flags. If a flag does not exist, an empty-string
* value is used.
*
* CAUTION: This method is kind of janky since it returns a struct with flag names
* that MAY NOT ACTUALLY EXIST for the user. You might just be better off getting all
* the flags for the given user and then plucking-out the flags you need?
*
* @userID I am the user who owns the flags.
* @flagNames I am the collection of flags being accessed.
*/
public struct function getUserFlagMulti(
required numeric userID,
required array flagNames
) {
// NOTE: When I tried to code this method, I originally tried to use a single
// JSON_EXTRACT() call with its variadic signature, providing all flag paths at
// the same time: JSON_EXTRACT( JSON, path [, path [, path ]] ). However, that
// approach proved to be a non-starter since it returns the values in an array,
// but omits any values whose keys are NULL. As such, there was no way for me to
// map the resultant array indices back onto the right flag names. To keep the
// results consistent, I'm returning each flag as its own INDEX-based column.
```
<cfquery name="local.results">
SELECT
f.userID
<cfloop index="local.i" value="local.flagName" array="#flagNames#">
,
JSON_EXTRACT( f.flags, <cfqueryparam value="$.#flagName#" sqltype="varchar" /> ) AS '#i#'
</cfloop>
FROM
user_flags f
WHERE
f.userID = <cfqueryparam value="#userID#" sqltype="integer" />
;
</cfquery>
```
var flags = [:];
loop
index = "local.i"
value = "local.flagName"
array = flagNames
{
flags[ flagName ] = isJson( results[ i ] )
? deserializeJson( results[ i ] )
: ""
;
}
return( flags );
}
/**
* I get the flags for the given user.
*
* CAUTION: The database driver will return the `flags` column as a STRING. However,
* we want to encapsulate the JSON serialization / deserialization as an implementation
* detail. As such, we'll deserialize the `flags` column before we return it.
*
* @userID I am the user who owns the flags.
*/
public struct function getUserFlags( required numeric userID ) {
```
<cfquery name="local.results">
SELECT
f.userID,
f.createdAt,
f.updatedAt,
f.flags
FROM
user_flags f
WHERE
f.userID = <cfqueryparam value="#userID#" sqltype="integer" />
;
</cfquery>
```
results = results.map(
( row ) => {
return({
userID: arguments.row.userID,
createdAt: arguments.row.createdAt,
updatedAt: arguments.row.updatedAt,
// The calling context should always deal in STRUCTS. It should not
// know that the flags go through stringification.
flags: deserializeJson( arguments.row.flags )
});
}
);
return( results );
}
/**
* I set the given flag for the given user.
*
* @userID I am the user who owns the flags.
* @flagName I am the flag being accessed.
* @flagValue I am the flag value being persisted.
*/
public void function setUserFlag(
required numeric userID,
required string flagName,
required any flagValue
) {
// Since we want to store a NEW FLAG, but don't want to delete any existing
// flags, we'll just create a PATCH value and then persist it. This will append
// the given value to the existing JSON payload.
setUserFlags(
userID,
{
"#flagName#": flagValue
}
);
}
/**
* I persist the given user flags. This method is designed to be IDEMPOTENT in so much
* as that if a record already exists - if there are already flags associated with the
* given user - the old flags and the new flags are PATCHED together. Meaning, the
* old flags Struct is maintained but any NEW KEYS OVERWRITE old keys.
*
* @userID I am the user who owns the flags.
* @flags I am the set of key-value flags to persist.
*/
public void function setUserFlags(
required numeric userID,
required struct flags
) {
// Since user flags are an "ad hoc" - meaning, flags are added to the system as
// needed by the product requirements - we going to perform an "upsert" such that
// we'll treat all flag assignments as an INSERT; and then, fallback to an UPDATE
// if the user already has flags assigned to their account.
// --
// NOTE: There is a UNIQUE KEY on the userID field.
```
<cfquery name="local.results">
INSERT INTO
user_flags
SET
userID = <cfqueryparam value="#userID#" sqltype="integer" />,
createdAt = <cfqueryparam value="#now()#" sqltype="timestamp" />,
updatedAt = <cfqueryparam value="#now()#" sqltype="timestamp" />,
flags = <cfqueryparam value="#serializeJson( flags )#" sqltype="longvarchar" />
ON DUPLICATE KEY UPDATE
updatedAt = <cfqueryparam value="#now()#" sqltype="timestamp" />,
flags = JSON_MERGE_PATCH( flags, <cfqueryparam value="#serializeJson( flags )#" sqltype="longvarchar" /> )
;
</cfquery>
```
}
}
Notice that all the values from within the flags JSON column are passed-through the database driver as a String. As such, I have to run deserializeJson() on the values before I return them to the calling context.
And, to test this data access gateway, I just ran some some inserts, updated, and deletes:
<cfscript>
gateway = new UserFlagsGateway();
// Reset the demo - deletes all flags for the given user.
gateway.deleteUserFlags( 1 );
// Set multiple flags at the same time.
gateway.setUserFlags(
1,
{
"nickname": "benben",
"hasSeenSiteIntro": true,
"hasSeenTourV1": true,
"hasSeenTourV2": false,
"hasAgreedToTOS": false
}
);
// NOTE: Since all of the ad hoc flag access is performing an UPSERT, I want
// to include a small sleep here so that the updatedAt and createAt date/time stamps
// are actually different. Just to make sure that the UPSERT it working properly.
sleep( 2575 );
// Set a few one-off flags.
gateway.setUserFlag( 1, "colorScheme", [ "##121212", "##f0f0f0" ] );
gateway.setUserFlag( 1, "prefersNoAnimation", true );
// The system no longer needs this flag, so let's get rid of it.
gateway.deleteUserFlag( 1, "hasSeenTourV1" );
// Try to delete a few flags at the same time.
gateway.deleteUserFlagMulti( 1, [ "hasSeenTourV1", "hasAgreedToTOS" ] );
// Try to access a few single flags.
echo( "<h3> Trying a few one-off flag reads. </h3>" );
dump( gateway.getUserFlag( 1, "nickname" ) );
dump( gateway.getUserFlag( 1, "colorScheme" ) );
// Try accessing multiple flags at the same time.
// --
// NOTE: This was intended to be a bit of an optimization where we can read-in
// multiple flags without having to return the entire JSON payload from the database.
// To be honest, I have NO IDEA if this approach is even better or more performant
// than just returning the whole JSON payload and then plucking out what you need.
echo( "<h3> Trying a multi-flag read. </h3>" );
dump( gateway.getUserFlagMulti( 1, [ "hasSeenTourV1", "hasSeenTourV2", "colorScheme" ] ) );
// Try reading all the flags associated with the user.
echo( "<h3> Reading all flags. </h3>" );
dump( gateway.getUserFlags( 1 ) );
</cfscript>
When we run this ColdFusion code against the MySQL 5.7.32 database, we get the following browser output:
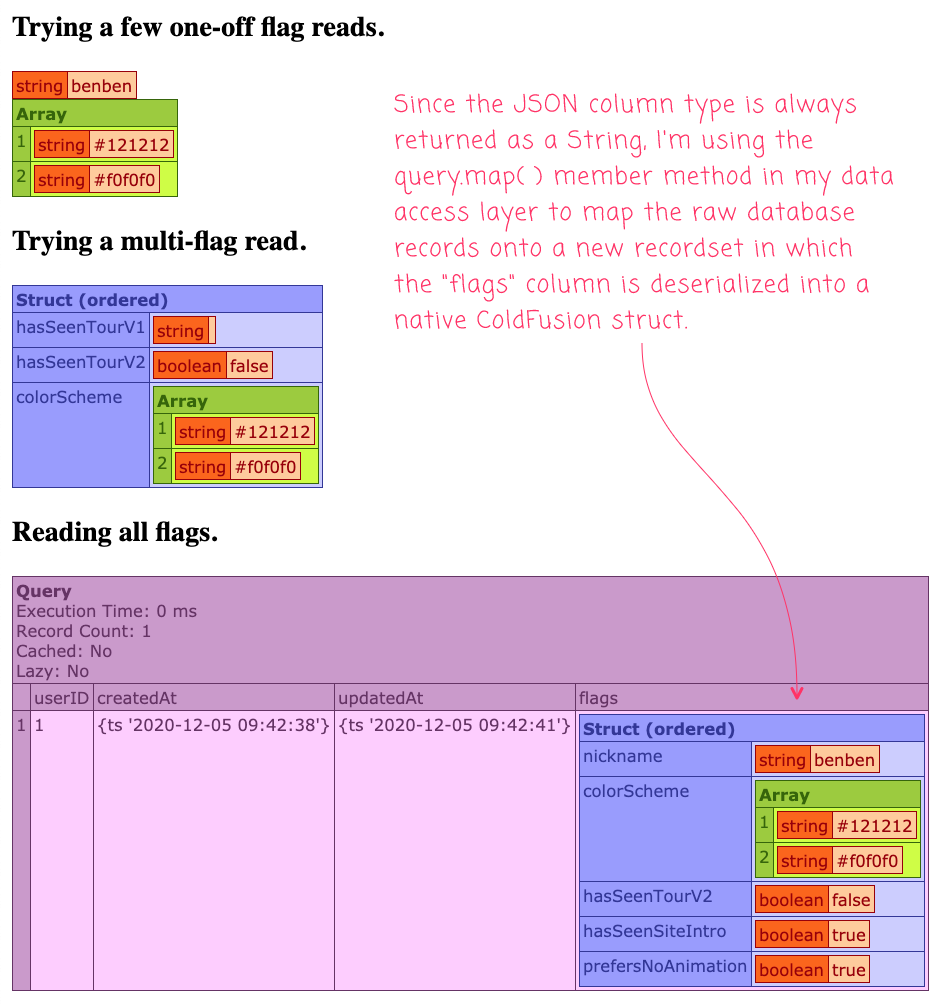
As you can see, the values being returned from the data access layer are native ColdFusion data-types. This is because I'm using the deserializeJson() method internally to translate the stringified values in the database layer into "hydrated" values within the application layer.
From what I've read, there's a lot more that you can do with JSON column types (even in the 5.7 release); but this was just my first look at them, so I wanted to keep it as simple as possible (and no simpler). This was also my very first use of the ON DUPLICATE KEY UPDATE technique, which is really exciting! So, for me, this whole exploration was a massive value-add for my mental toolbox. Hopefully there's something interesting in it for you as well.
Epilogue: Why Not Just Use a LONGTEXT Field?
Since we have to serialize and deserialize the JSON within our data-access component, it may be tempting to ask why we don't just use a LONGTEXT field? And, in fact, prior to MySQL 5.7, this is exactly what people on my team have done when trying to shoe-horn JSON into a relational database model.
ASIDE: We've discovered that reading-in a
LONGTEXTfield can be garbage for performance in high throughput scenarios. After having discovered this after the fact, we've had to jump through hoops to do "just in time" reading ofLONGTEXT"JSON" if - and only if - we need the values.
Hopefully, the answer to this question can already be seen, in part, in this post. For starters, we can extract a subset of the JSON payload, which you can't do with a LONGTEXT field. We can also safely merge two JSON types, which you can't do with a LONGTEXT field.
Not covered in this post, you can also index values within a JSON column by creating "virtual fields". And, I'm sure there are a whole host of other performance-related reasons that I am still naive to.
Want to use code from this post? Check out the license.

Reader Comments
@All,
This morning, I wanted to share a quick follow-up post in which I continue my exploration of the
JSONcolumn-type in MySQL 5.7:www.bennadel.com/blog/3934-more-experimenting-with-the-json-column-type-in-mysql-5-7-32-and-lucee-cfml-5-3-7-47.htm
In this follow-up post, I look at trying to improve upon an old, janky design in which I was / am storing foreign keys in a comma-delimited list. I try to improve on that approach by using a
JSONhash in which the foreign IDs end-up being keys in the hash.@All,
A quick follow-up to this post, I've been thinking about the delta between the MySQL
JSONsupport and the feature-set we get in more robust "document" databases (and the like). And, one thing I wanted to see if I could do was atomically increment a value within aJSONcolumn:www.bennadel.com/blog/3935-atomically-incrementing-json-column-values-in-mysql-5-7-32-and-lucee-cfml-5-3-7-47.htm
Turns out, since MySQL is build with ACID properties, this is actually fairly easy to build (if not a bit verbose).
@All,
I don't know how I missed this in my earlier exploration, but it seems that there are also two new JSON aggregation functions that can be used with
GROUP BYand other aggregation approaches:www.bennadel.com/blog/4217-goodbye-group-concat-hello-json-arrayagg-and-json-objectagg-in-mysql-5-7-32.htm
The
JSON_ARRAYAGG()andJSON_OBJECTAGG()functions are going to be super helpful!