
Considering Data Workflows Within A MongoDB Data-Access Layer In Lucee CFML 5.3.6.61
At InVision, I've consumed MongoDB databases. But, I've never actually created a MongoDB data-access layer on my own - I've only ever consumed one that was created by another team. That is, until last week. I've been working on a project to fold a "microservice" back into the "monolith" for easier maintenance; and, as part of that migration, I had to create a data-access layer in ColdFusion to read-from and write-to the subsumed service's MongoDB collections. This was a very interesting exercise; and, made me think about the differences between data workflows in a relational database (ex, MySQL) and those in a document database (ex, MongoDB). This gave me an opportunity to think deeply about how I might want to organize data workflows within a data-access layer that communicates with MongoDB in Lucee CFML 5.3.6.61.
To be clear, I love relational databases. They easily fit into the vast majority of my use-cases; they have decades of battle-testing under their belt; they are fast; and, they are obvious. And, by "obvious", I mean that I can look at a relational database and know exactly what kind of data it contains because it has a schema that enforces the data inputs.
On the ColdFusion application side, I also love working with relational databases because I can crack-open a data-access component and leverage that same obvious behavior. Meaning, I can open up a ColdFusion component and see from the <cfquery> and <cfqueryparam> tags exactly what data is being stored and in what format:
<cfquery name="results">
INSERT INTO
contact
SET
name = <cfqueryparam value="#name#" sqltype="varchar" />,
email = <cfqueryparam value="#email#" sqltype="varchar" />,
createdAt = <cfqueryparam value="#createdAt#" sqltype="timestamp" />
;
</cfquery>
Other than possible NULL columns - which shouldn't be used unless absolutely required by the application logic - there's no ambiguity here. I can clearly see what columns are in the table; and, I can clearly see what data-types are being stored in those columns. And, what's even better, the <cfqueryparam> tag is going to implicitly cast any "loose" ColdFusion values into strict values required by the database schema.
Relational databases are just a joy to work with. SQL is an automatic Oxytocin inducer.
Document databases, on the other hand, tend to provide a much smaller sense of security. It's extremely hard to look at a document database and understand what is actually in it. Data can evolve over time; and, there's no requirement that developers migrate existing document structures when new properties are added or old properties are removed. As such, it's up to the data-access layer to bridge that gap.
ASIDE: It does look like MongoDB now has some features around schema validation. But, looking at the documentation for it made my head hurt. I don't think it can even be compared so the simplicity of a relational table schema definition.
Unfortunately, most MongoDB data-access layers that I've consumed in my career tend to treat the data inputs as a black-box. Meaning, they accept a data-transfer object (DTO) and just store it in a MongoDB collection with only minimal validation, leaning on the calling context (the Service layer) to do the heavy-lifting.
This leads to all kinds of issues, not the least of which is when a numeric property is accidentally stored as a string and can no longer be found by the .find() method which is expecting a numeric input.
Ideally, a MongoDB data-access layer should provide all the same amenities that a relational database data-access layer provides. Meaning, I should be able to open up a data-access component and:
See exactly what properties live in a collection.
See exactly what data-types are required for those properties.
See that the data-access layer enforces those data-types.
Essentially, a MongoDB data-access layer should take the flexible, schemaless power of a document database and wrap it in the predictable, intuitive, and self-documenting nature of a relational data-access layer.
Again, to be clear, I've never actually done this before. As such, what follows is just a thought experiment in how I might be able to make a MongoDB data-access layer as enjoyable to work with as a MySQL data-access layer. And, to explore this concept, I'm going to create a ContactGateway.cfc, which can create, read, and delete "Contact documents".
Each Contact document contains the following properties:
_id- ObjectIDname- Stringemail- StringisFavorite- BooleancreatedAt- DateTimephoneNumbers- Array of Structstype- Stringnumber- StringisPrimary- Boolean
tags- Array of Strings
Of course, these are the properties that the Contact document contains today. As is often the case with databases, the Contact document didn't always contain all of these properties - the Contact schema has evolved over time as the needs of the application have changed. As such, one job of the data-access layer is going to be to take the different raw documents and coerce them into a standard format.
Before we look at the data-access layer, let's just look at the calling context to see how it's going to be used:
<cfscript>
contactGateway = new ContactGateway( new MongoClient() );
// Create the new contact using the given data-transfer object (DTO). This operation
// will return the primary key (_id) of the MongoDB object.
// --
// NOTE: In the following DTO, notice that I am using NON-STRICT VALUES for the
// "createdAt", "isFavorite", and "isPrimary" properties (using a String
// representation for Date and Boolean values, respectively). I am doing this in
// order to demonstrate that the ContactGateway will cast those values explicitly to
// the appropriate types that are expected by the underlying database.
id = contactGateway.createContact({
name: "Johnny Cab",
email: "johnny.cab@totalrecall.movie",
isFavorite: "TRUE",
createdAt: "2020/10/27",
phoneNumbers: [
{ type: "work", number: "+1 (917) 555-1210", isPrimary: "YES" },
{ type: "work", number: "+1 (917) 555-1211" }
],
tags: [ "Cab", "Taxi" ]
});
// Let's read the Contact record back out of the database to make sure it looks like
// the data we provided.
dump( contactGateway.getContactByID( id ) );
// contactGateway.deleteContactByID( id );
</cfscript>
As you can see, we're creating a Contact record and then reading it back out. For the sake of the exploration, notice that I am providing some ColdFusion values as "loosely defined" data types:
isFavorite:"TRUE"createdAt:"2020/10/27"isPrimary:"YES"
As I stated earlier, ColdFusion is more than happy to cast simple data types back and forth as needed. As such, it's perfectly OK to use the Strings TRUE and YES to defined Boolean values. However, storing those "loose" values into MongoDB is going to cause you, and everyone you know, pain and heartache. As such, the data-access layer must ensure that these values are cast to the appropriate type on write.
Now, if we run the above ColdFusion code, we get the following browser output:
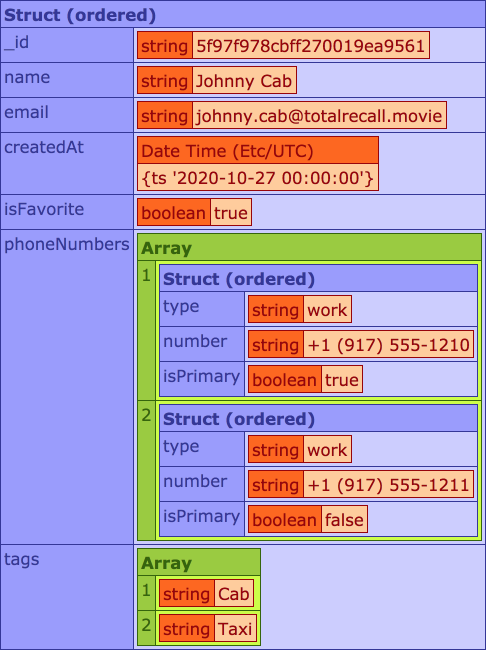
First off, we can see that the data returned from the data-access layer consists of native ColdFusion data-types - specifically no BSON documents. Also, we can see that the "loosely typed" input values (createdAt, isFavorite, and isPrimary) have all been cast to strict types (Dates and Boolean values).
And, now that we can see how this ContactGateway.cfc data-access component is being consumed, let's look at how it is implemented.
Remember, this is my first time implementing a MongoDB data-access layer from scratch. And, keep in mind that I am specifically trying to build-in the same self-documenting, intuitive, and obvious properties that we get for free in a relational database data-access layer.
To this end, I am using notions of wrapping and unwrapping data payloads. When I am writing to the MongoDB database, I am "wrapping" the data in a format that is needed for the database. Then, when I reading from the MongoDB database, I am "unwrapping" the persisted documents so that they are format that is best suited for the ColdFusion runtime:
component
output = false
hint = "I provide data-access methods for Contacts."
{
/**
* I initialize the Contacts data-access gateway using the given MongoDB client.
*
* @mongoClient I am the MongoDB drive to use for persistence.
*/
public void function init( required any mongoClient ) {
variables.mongoClient = arguments.mongoClient;
// ColdFusion is very lenient about how data-types are represented; and, it will
// freely cast one simple value to another as needed by a given context. MongoDB,
// on the other hand, is much more strict about how values are represented and,
// more importantly, indexed. As such, when we push data into the MongoDB
// database, we have to be VERY EXPLICIT about what data-types are using. To that
// end, I'm going to be casting ColdFusion values to JAVA types as I store them.
// To do that, I'm going to copy some "caster" methods from the driver.
variables.asBoolean = variables.mongoClient.asBoolean;
variables.asDate = variables.mongoClient.asDate;
variables.asLong = variables.mongoClient.asLong;
variables.asString = variables.mongoClient.asString;
}
// ---
// PUBLIC METHODS.
// ---
/**
* I create a new Contact using the given data-transfer object (DTO).
*
* @contact I am the data-transfer object being persisted.
*/
public string function createContact( required struct contact ) {
var results = wrapContact( contact );
mongoClient
.getCollection( "contact" )
.insertOne( results )
;
// The MongoDB driver will automatically generate and append the _id to the
// document pre-persistence. We can now return this primary-key.
return( results._id.toString() );
}
/**
* I delete the contact with the given id. If there is no contact with the given id,
* the delete operation will fail silently.
*
* @_id I am the contact being deleted.
*/
public void function deleteContactByID( required string _id ) {
mongoClient
.getCollection( "contact" )
.deleteOne(
mongoClient.toBson([
"_id": mongoClient.toObjectID( _id )
])
)
;
}
/**
* I get the contact with the given id. If there is no contact with the given id, an
* error is thrown.
*
* @_id I am the contact being accessed.
*/
public struct function getContactByID( required string _id ) {
var results = mongoClient
.getCollection( "contact" )
.find(
mongoClient.toBson([
"_id": mongoClient.toObjectID( _id )
])
)
.into( [] )
.map(
( document ) => {
return( unwrapContact( document ) );
}
)
;
if ( ! results.len() ) {
throw(
type = "ContactNotFound",
message = "The contact with the given ID could not be found.",
extendedInfo = serializeJson( arguments )
);
}
return( results.first() );
}
// ---
// PRIAVTE METHODS.
// ---
/**
* I convert the persisted MongoDB contact into a native ColdFusion data structure.
*
* @contact I am the payload being unwrapped.
*/
private struct function unwrapContact( required struct contact ) {
// CAUTION: In the following operation, note that some of the values use the
// Elvis (null coalescing) operator. This is because (for the sake of the demo),
// those properties were not always present in the database. As such, when we
// pull the data out of the database, we have to normalize those properties into
// an expected format.
// --
// ASIDE: Of course, we could have "migrated" the entire data-set when the new
// properties were added to the application. However, in my experience, this is
// NOT what most developers have been doing.
var unwrapped = [
"_id": contact._id.toString(),
"name": contact.name,
"email": contact.email,
"createdAt": contact.createdAt,
"isFavorite": ( contact.isFavorite ?: false ),
"phoneNumbers": unwrapPhoneNumbers( contact.phoneNumbers ),
"tags": unwrapTags( contact.tags ?: [] )
];
return( unwrapped );
}
/**
* I convert the persisted MongoDB phoneNumbers into a native ColdFusion data
* structure.
*
* @phoneNumbers I am the payload being unwrapped.
*/
private array function unwrapPhoneNumbers( required array phoneNumbers ) {
var unwrapped = phoneNumbers.map(
( phoneNumber ) => {
// CAUTION: Again, you will see the null coalescing operator being used
// to normalize the shape of the data structure so as to account for
// properties that were added later on in the application life-cycle.
return([
"type": phoneNumber.type,
"number": phoneNumber.number,
"isPrimary": ( phoneNumber.isPrimary ?: false )
]);
}
);
return( unwrapped );
}
/**
* I convert the persisted MongoDB tags into a native ColdFusion data structure.
*
* @tags I am the payload being unwrapped.
*/
private array function unwrapTags( required array tags ) {
// NOTE: The tags data structure could probably have just been returned as-is;
// however, I am using the .map() operation here just to be consistent with the
// way that I am treating the reset of the data.
var unwrapped = tags.map(
( tag ) => {
return( tag );
}
);
return( unwrapped );
}
/**
* I convert the contact data into an explicit format for persistence in the MongoDB
* database.
*
* @contact I am the payload being wrapped.
*/
private struct function wrapContact( required struct contact ) {
// CAUTION: In the following operation, note that some of the values use the
// Elvis (null coalescing) operator. This is because I am allowing some of the
// properties to be OPTIONAL on write. However, I want to keep a consistent
// format for persisted documents. As such, I am going to explicitly provide
// default value for those properties not being provided by the calling context.
var wrapped = mongoClient.toBson([
"name": asString( contact.name ),
"email": asString( contact.email ),
"createdAt": asDate( contact.createdAt ),
"isFavorite": asBoolean( contact.isFavorite ?: false ),
"phoneNumbers": wrapPhoneNumbers( contact.phoneNumbers ?: [] ),
"tags": wrapTags( contact.tags ?: [] )
]);
return( wrapped );
}
/**
* I convert the phoneNumbers data into an explicit format for persistence in the
* MongoDB database.
*
* @phoneNumbers I am the payload being wrapped.
*/
private array function wrapPhoneNumbers( required array phoneNumbers ) {
var wrapped = phoneNumbers.map(
( phoneNumber ) => {
// CAUTION: Again, you will see the null coalescing operator being used
// to normalize the shape of the data structure so as to provide default
// values for optional properties as write time.
return(
mongoClient.toBson([
"type": asString( phoneNumber.type ),
"number": asString( phoneNumber.number ),
"isPrimary": asBoolean( phoneNumber.isPrimary ?: false )
])
);
}
);
return( wrapped );
}
/**
* I convert the tags data into an explicit format for persistence in the MongoDB
* database.
*
* @tags I am the payload being wrapped.
*/
private array function wrapTags( required array tags ) {
var wrapped = tags.map(
( tag ) => {
return( asString( tag ) );
}
);
return( wrapped );
}
}
There's obviously a lot more code in a MongoDB data-access layer than there is in a MySQL data-access layer. But, that's because 1) the database documents are more complex than relational database rows; and 2) we have to explicitly build a lot of the "magic" that the <cfquery> and <cfqueryparam> tags give us for free.
The other point of complexity is that, because a document collection can evolve over time, we have to move schema enforcement into the application layer. To that end, you can see that I am making use of the Elvis / null coalescing operator to provide default inputs and outputs to keep the structure of the data uniform.
I am also explicitly casting every input to be the required, native data-type. This way, numbers and booleans (for example) don't accidentally get stored as strings. I'm not going to show the MongoClient.cfc, since it's "just enough" to get the demo to work; but, I will share the casting methods that I borrow from it:
<cfscript>
// ... truncated code ...
public boolean function asBoolean( required boolean value ) {
return( javaCast( "boolean", value ) );
}
public date function asDate( required date value ) {
// NOTE: We need to use the dateAdd() in order for ColdFusion to cast any string-
// based dates into Date/Time objects. This should be sufficient for giving us
// data type that we need.
return( dateAdd( "d", 0, value ) );
}
public numeric function asLong( required numeric value ) {
return( javaCast( "long", value ) );
}
public string function asString( required string value ) {
return( javaCast( "string", value ) );
}
// ... truncated code ...
</cfscript>
I love working with relational databases. And, for the type of work that I do, they really satisfy the vast majority of use-cases. But, when I do have to work with a document database like MongoDB, I want to try and find a way to bring all the security and self-documenting characteristics of a relational data-access layer to the document data-access layer. It requires a bit more code and a lot more explicit data management. But, so far, I am liking the track that I am on.
Want to use code from this post? Check out the license.

Reader Comments
@All,
One thing that got me thinking so much about MongoDB data-access layers in ColdFusion is the fact that I just discovered (ie, deployed a bug) that the BSON documents coming out of MongoDB are case-sensitive:
www.bennadel.com/blog/3915-mongodb-bson-structs-are-case-sensitive-in-lucee-cfml-5-3-6-61.htm
Normally, this wouldn't matter one way or another. But, I'm working with legacy code; and, the code contained inconsistent key-casing which was causing some logic-blocks to be skipped since it didn't appear that the MongoDB results has the expected keys.