
In Node.js, The error.stack Property Will Represent The Point In The Code At Which new Error() Was Called - Not When The Error Is Thrown
Yesterday, I was trying to help my co-worker figure out why one of his Node.js containers was throwing errors. When looking at the logs, however, I discovered that the errors weren't all that helpful. The stack-traces in the log only pointed to the line of code on which the Error objects were being instantiated - they were not pointing to the portion of the control flow in which the error was actually being thrown. Most of the time, these two gestures - construction and throwing - go hand-in-hand; however, in this case they were separated, which created a confusing and obfuscated audit trail.
To be clear, this is not a bug. Nor is it an unexpected behavior. If look at the Node.js documentation for the Error() constructor, it is stated clearly:
Creates a new Error object and sets the error.message property to the provided text message. If an object is passed as message, the text message is generated by calling message.toString(). The error.stack property will represent the point in the code at which new Error() was called. Stack traces are dependent on V8's stack trace API. Stack traces extend only to either (a) the beginning of synchronous code execution, or (b) the number of frames given by the property Error.stackTraceLimit, whichever is smaller.
To see why this is important to understand, consider the following Node.js (v8.3.0) code:
try {
// CAUTION: The .stack property of this error will indicate that the error occurred
// on line-6 - NOT on the subsequent line in which the error is throw()n.
var error = new Error( "Instantiated on Line-6." );
var rando = Math.random();
if ( rando > 0.6 ) {
error.randomValue = "high";
throw( error );
} else if ( rando > 0.2 ) {
error.randomValue = "low";
throw( error );
}
// NOTE: If we made it this far, there was no need to throw.
} catch ( caughtError ) {
console.error( caughtError );
}
As you can see, we're creating an Error() object on line-6; however, we're not throwing it until later on in the control-flow, after it has been augmented based on various conditional checks. As such, when we run this code, we [randomly] get the following terminal output:
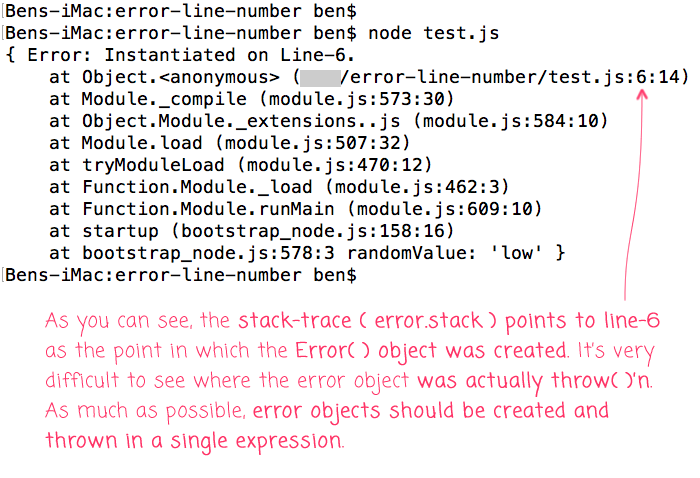
As you can see, the stack-trace (error.stack) points to line-6, which is where the Error() object was constructed. What we can't see very clearly in the stack-trace was which condition caused the error to finally be thrown. In this case, we happen to see the augmented property, "randomValue", showing a value of "low" which coincidentally gives us some insight. But, if that property weren't being output (such as in a case where a log-item serializer didn't look for non-standard error properties), then this stack-trace would be substantially less useful.
Ultimately, it is best to be instantiating and throwing errors in the same expression such that the line-number in the stack-trace actually points to the line on which the error is thrown. And, if you need to augment the error object properties, don't do it after the Error object is created - create a custom error object that extends the core Error and provides for more constructor arguments. Not only will this make the stack-traces more useful, it will also make the shape of the various error objects more predictable (which is a necessity in TypeScript and ts-node).
NOTE: In recent versions of Node.js that support ES6, you can create a class that simply "extends" the native Error object, making the sub-classing of Error a piece of delicious cake.
Want to use code from this post? Check out the license.

Reader Comments