
Understanding The Query Plan "Explained" By the Find Plugin In PouchDB 6.2.0
When the Mango .find() plugin runs in PouchDB 6.2.0, there is an option to turn on debugging so that you can see how your .find() selector is being applied to the PouchDB database. At first, I found the output of the .find() debugging rather confusing; so, I just turned it off. But, once I developed a better mental model for how the query planner was executing my query, I realized that the debugging output actually contained a lot of helpful information. As such, I wanted to put together a quick tutorial on how to read the query planner output so that others might be able to embrace it sooner than I did.
Run this demo in my JavaScript Demos project on GitHub.
In the Mango query documentation, it clearly states that the .find() plugin is built on top of the existing Map / Reduce functionality in PouchDB. However, this didn't really hit home until I started to understand that the .find() plugin operates in phases. Things finally clicked for me when I read Garren Smith's article from 2015 in which he explains that only equality-based operators can be applied to indices:
- $eq
- $gt
- $gte
- $lt
- $lte
NOTE: In my previous post, I use the $in operator to act like a collection of $eq operators using monkey-patching of the .find() plugin.
Then, any non-equality-based operators are applied after-the-fact in memory:
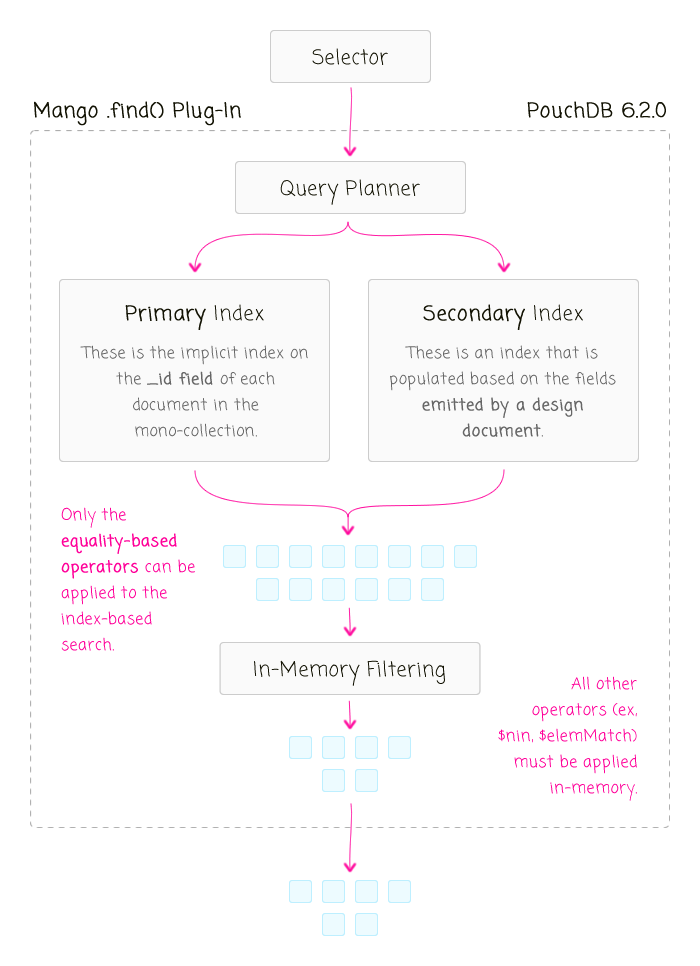
Once I understood this PouchDB query execution workflow, the debugging output by the query planner suddenly made sense. The debugging output gives you several pieces of valuable insight:
- What selector you passed to the .find() method.
- Which index is being used for the query (it always uses an index).
- Which selector criteria are being applied to the index (and how that criteria was transformed).
- Which selector criteria are being applied in-memory to the intermediary results.
NOTE: The output actually includes more than this; but, for the sake of this explanation, these are the key-points that I am focusing on.
To see how this information can shed light on your query performance, let's walk through a few PouchDB query operations. First, let's setup the demo with some documents:
var dbName = "javascript-demos-pouchdb-find-playground";
// Enable debugging for the .find() plugin. This will output the Selector that
// each query uses as well as the Query Plan that has been chosen to run on top
// of the map / reduce infrastructure.
PouchDB.debug.enable( "pouchdb:find" );
// Creating the PouchDB database instance is a synchronous operation. This means
// that we can immediately start to interact with the "db" object.
var db = new PouchDB( dbName );
// When I am playing around with PouchDB, I like to destroy and recreate the
// database on each test run. This way, any conflicts with existing data are
// explicitly coded into the experiment and not a byproduct of dirty data.
db.destroy().then(
function() {
// Once we destroy the database, we have to create a new one otherwise
// we'll get an error, "Error: database is destroyed".
db = new PouchDB( dbName );
}
)
// At this point, we have a pristine PouchDB instance to experiment with. Every
// PouchDB operation returns a Promise (though you could use a Callback if you
// wanted to for some reason). So, to start experimenting, we can just chain the
// "thenable" operations together.
.then(
function() {
// Let's insert some Friend data.
var promise = db.bulkDocs([
{
_id: "friend:kim",
type: "friend",
name: "Kim",
age: 42,
interests: [ "Movies", "Computers", "Cooking" ],
favoriteMovies: [
{ imdbId: "tt0103064", title: "Terminator 2: Judgment Day" },
{ imdbId: "tt0093773", title: "Predator" },
{ imdbId: "tt0093894", title: "The Running Man" }
]
},
{
_id: "friend:sarah",
type: "friend",
name: "Sarah",
age: 35,
interests: [ "Museums", "Working Out", "Movies" ],
favoriteMovies: [
{ imdbId: "tt0112508", title: "Billy Madison" },
{ imdbId: "tt0116483", title: "Happy Gilmore" },
{ imdbId: "tt0103064", title: "Terminator 2: Judgment Day" }
]
},
{
_id: "friend:joanna",
type: "friend",
name: "Joanna",
age: 29,
interests: [ "Working Out", "Poetry", "Dancing" ],
favoriteMovies: [
{ imdbId: "tt0210075", title: "Girlfight" },
{ imdbId: "tt0179116", title: "But I'm a Cheerleader" },
{ imdbId: "tt0112697", title: "Clueless" }
]
}
]);
return( promise );
}
)
As you can see, we start off with a database full of friends that each contain some simple and complex values.
The .find() plugin can be used to search both the primary index and the secondary indices. When it comes to the secondary indices, .find() can only consume indices created with the .createIndex() method, presumably because that's the only way the query planner can know which fields map to which index. But, since the query planner knows that the _id field always maps to the primary key index, we can use the .find() plugin to search the primary index right out of the box:
.then(
function() {
// The .find() plugin allow us to search both the primary key index as
// well as the indices we create using .createIndex(). Let's select a
// subset of friends using a range on the primary key.
var promise = db.find({
selector: {
_id: {
$gte: "friend:",
$lte: "friend:kim"
}
}
});
promise.then(
function( results ) {
console.group( "ONE: Found %s friends by _ID range.", results.docs.length );
results.warning && console.warn( results.warning );
results.docs.forEach(
function( doc ) {
console.log( doc.name, "-", doc._id );
}
);
console.groupEnd();
}
);
return( promise );
}
)
As you can see, our selector is limited to a range-selection on the _id field, which can be applied to the primary key index. And, when we run this, we get the following query explanation:

As you can see, the inMemoryFields property tells us that none of the selector criteria was used to perform in-memory filtering; the index property tells us which index was being consumed - the primary key index; and, the queryOps property tells us how our selector criteria were being applied to the primary-key index (ie, which values were being passed into the .allDocs() method, in this case).
Now, let's create a secondary index using the .createIndex() method and then use that index to search for friends:
.then(
function() {
// The .find() plugin will also search secondary indices; but, only the
// indices created using the .find() plugin (presumably because those
// are the only indices that offer insight into which fields were emitted
// during the index population).
var promise = db.createIndex({
index: {
fields: [ "type", "age" ]
}
});
return( promise );
}
).then(
function() {
// Now that we have our [ type, age ] secondary index, we can search
// the documents using both Type and Age.
var promise = db.find({
selector: {
type: "friend",
age: {
$gte: 30,
$lt: 50
}
}
});
promise.then(
function( results ) {
console.group( "TWO: Found %s friends by AGE.", results.docs.length );
results.warning && console.warn( results.warning );
results.docs.forEach(
function( doc ) {
console.log( doc.name, "-", doc.age );
}
);
console.groupEnd();
}
);
return( promise );
}
)
As you can see, our secondary index contains two fields: Type and Age. When we go to query this index, we provide only Type and Age in our selector. As such, we should end up with a query in which all filtering is done at the index level. And, when we run this, we get the following query explanation:
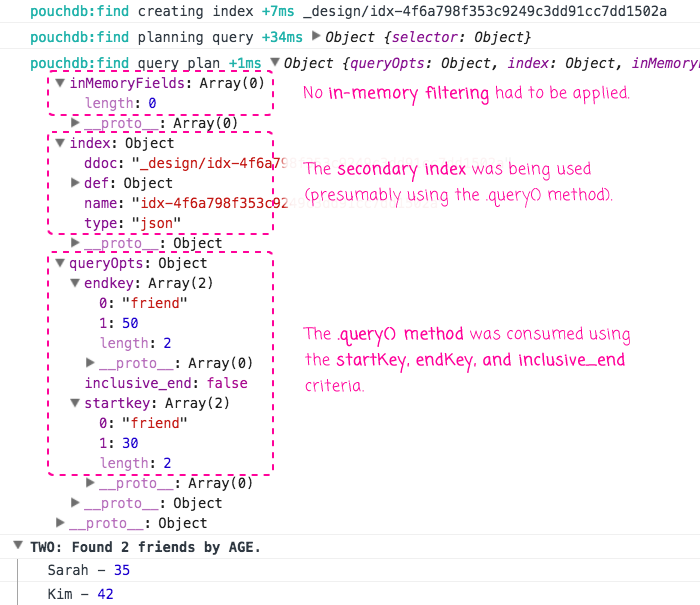
As you can see, the inMemoryFields property tells us that none of the selector criteria was used to perform in-memory filtering; the index property tells us that our recently-created secondary index was being consumed; and, the queryOps property tells us how our selector criteria was being applied. Notice that our use of the $lt operator was translated into a "inclusive_end" .query() criteria.
In the previous example, we consumed all of the fields identified in the secondary index. However, much like a SQL database, we can leverage an index "prefix" in our query. Meaning, we can provide .find() criteria that can be satisfied by only the first field of the index, essentially ignoring the second field. However, unlike a SQL database, we still have to tell PouchDB about the second field in the index; only, we'll provide it as a sort of wildcard (or complex key range):
.then(
function() {
// In the previous example, we used all of the fields [ Type, Age ] in
// the query's selector; but, we can also use an index PREFIX to locate
// documents efficiently. In this case, we'll use the [ Type, Age ] to
// search for friends REGARDLESS OF AGE; then, we'll perform some
// additional IN-MEMORY filtering based on favorite movies.
var promise = db.find({
selector: {
type: "friend",
// In order to leverage the index we created above (for Type and
// Age), we have to include all the fields that were part of the
// index definition. However, since we don't actually care about
// the Age for this query, we can use a "wildcard" (so to speak).
// --
// NOTE: Using the {} as the field equality (complex key range)
// is the same as explicitly defining the range:
// --
// age: {
// $gte: null,
// $lte: {}
// }
age: {},
// CAUTION: The $elemMatch operator is an IN-MEMORY OPERATOR,
// which means that it cannot be run against an index. As such,
// we have to rely on the preceding "key prefix" index to return
// the bulk of the payload.
favoriteMovies: {
$elemMatch: {
imdbId: {
$eq: "tt0112697" // Clueless.
}
// NOTE: In the preceding condition, you CANNOT used the
// implied equality operator (imdbId: "abc"). Doing so
// throws the rather confusing error:
// --
// Error: unknown operator "0" - should be one of $eq,
// $lte, $lt, $gt, $gte, $exists, $ne, $in, $nin, $size,
// $mod, $regex, $elemMatch, $type or $all
}
}
}
});
promise.then(
function( results ) {
console.group( "THREE: Found %s friends by IMDB-ID.", results.docs.length );
results.warning && console.warn( results.warning );
results.docs.forEach(
function( doc ) {
console.log( doc.name, "-", doc.favoriteMovies );
}
);
console.groupEnd();
}
);
return( promise );
}
)
As you can see, we're providing the Type field and the Age field so that we can leverage our secondary index. But, in this case, we don't actually care about the Age so we're providing it as "{}", which is essentially a wildcard on that index field. Unlike the previous query, however, this query also searches on favoriteMovies, which is not in any of the indices. As such, we we run this, we get the following query explanation:
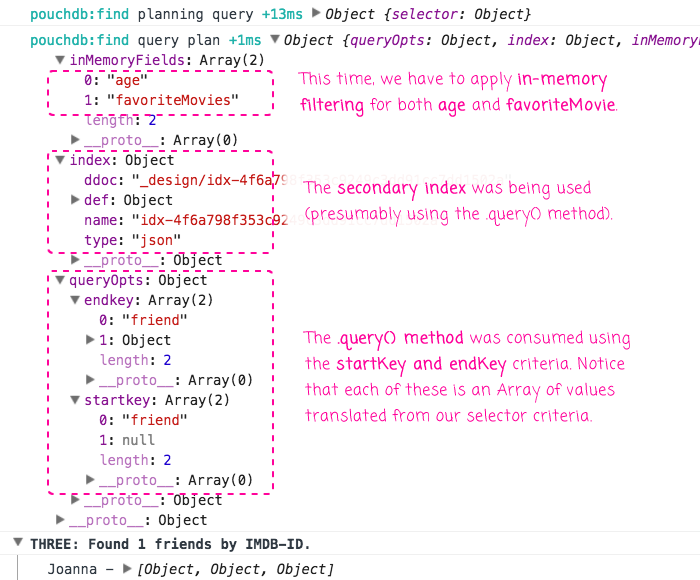
As you can see, the Mango .find() plugin was able to use an index. But, this time, it also had to apply some in-memory filtering. Essentially, we used the Type and Age (wildcard) to pull an intermediary set of documents back into memory from our secondary index. Then, the $elemMatch operator on favoriteMovies had to be applied in-memory to the intermediary results in order to produce the final set of documents.
NOTE: It says that "age" was also applied in-memory; but, I believe this just indicates that the wildcard-nature of it couldn't be used to narrow down the intermediary results at the index level.
Now, let's try creating and consuming a secondary index on one of the Array fields. This tripped me up until I understood how the Mango query planner was running on top of the existing map / reduce infrastructure:
.then(
function() {
// Now, let's create an index on the Interests field.
// --
// CAUTION: This MAY NOT DO WHAT YOU THINK IT DOES. PouchDB doesn't
// index the sub-items of the field - it indexes the entire field as
// a blackbox.
var promise = db.createIndex({
index: {
fields: [ "interests" ]
}
});
return( promise );
}
).then(
function() {
// Let's try to search for friends that have an interest in movies.
// --
// CAUTION: Only equality-based operators can be run against an index.
// In this case, we're using $in, which means that this will be forced
// to run IN-MEMORY.
var promise = db.find({
selector: {
interests: {
$in: [ "Movies" ]
}
}
});
promise.then(
function( results ) {
console.group( "FOUR: Found %s friends by interest.", results.docs.length );
results.warning && console.warn( results.warning );
results.docs.forEach(
function( doc ) {
console.log( doc.name, "-", doc.interests.toString() );
}
);
console.groupEnd();
}
);
return( promise );
}
)
As you can see, we're creating an index on the "interests" field and then we're attempting to find any document that shows an interest in "movies". And, when we run this code, we get the following query explanation:
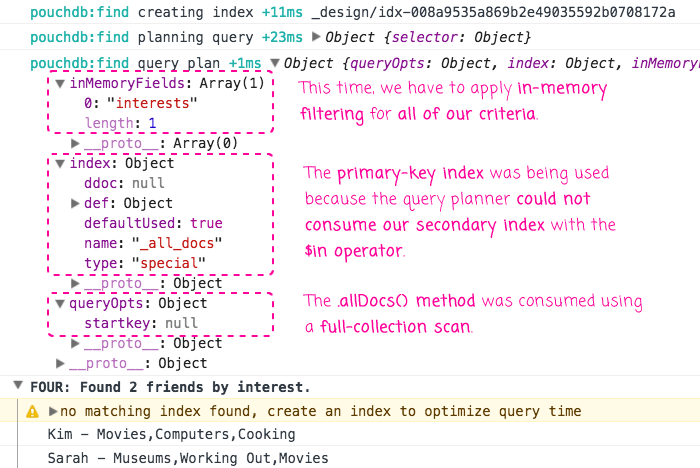
As you can see, with this query, we couldn't use the secondary index we just created on the "interests" field. This is because the secondary index can only be consumed using equality-based operators, not an operator like $in. As such, the query planner had to fallback to using the primary key index on _id. However, since we didn't provide an _id criterion, the query planner translated our selector into a startKey of "null". Which, essentially means bring back every document whose _id is greater than "null". Which results in a full scan of the database. The database documents are then filtered down using the $in operator in memory.
This is why this query planner rightfully warns us that we should create an index for this query in order to get better performance. No full database scans, please!
For completeness, here's the code for the entire demo. Note that I did not explicitly cover the last example in which I look for an exact match of the "interests" field:
<!doctype html>
<html>
<head>
<meta charset="utf-8" />
<title>
Understanding The Query Plan "Explained" By the Find Plugin In PouchDB 6.2.0
</title>
</head>
<body>
<h1>
Understanding The Query Plan "Explained" By the Find Plugin In PouchDB 6.2.0
</h1>
<p>
<em>Look at console — things being logged, yo!</em>
</p>
<script type="text/javascript" src="../../vendor/pouchdb/6.2.0/pouchdb-6.2.0.min.js"></script>
<!--
NOTE: When running this in the browser, the Find() plugin will AUTOMATICALLY
inject itself into the PouchDB global object. We don't have to wire this up
explicitly (except when running in node).
-->
<script type="text/javascript" src="../../vendor/pouchdb/6.2.0/pouchdb.find.js"></script>
<script type="text/javascript">
var dbName = "javascript-demos-pouchdb-find-playground";
// Enable debugging for the .find() plugin. This will output the Selector that
// each query uses as well as the Query Plan that has been chosen to run on top
// of the map / reduce infrastructure.
PouchDB.debug.enable( "pouchdb:find" );
// Creating the PouchDB database instance is a synchronous operation. This means
// that we can immediately start to interact with the "db" object.
var db = new PouchDB( dbName );
// When I am playing around with PouchDB, I like to destroy and recreate the
// database on each test run. This way, any conflicts with existing data are
// explicitly coded into the experiment and not a byproduct of dirty data.
db.destroy().then(
function() {
// Once we destroy the database, we have to create a new one otherwise
// we'll get an error, "Error: database is destroyed".
db = new PouchDB( dbName );
}
)
// At this point, we have a pristine PouchDB instance to experiment with. Every
// PouchDB operation returns a Promise (though you could use a Callback if you
// wanted to for some reason). So, to start experimenting, we can just chain the
// "thenable" operations together.
.then(
function() {
// Let's insert some Friend data.
var promise = db.bulkDocs([
{
_id: "friend:kim",
type: "friend",
name: "Kim",
age: 42,
interests: [ "Movies", "Computers", "Cooking" ],
favoriteMovies: [
{ imdbId: "tt0103064", title: "Terminator 2: Judgment Day" },
{ imdbId: "tt0093773", title: "Predator" },
{ imdbId: "tt0093894", title: "The Running Man" }
]
},
{
_id: "friend:sarah",
type: "friend",
name: "Sarah",
age: 35,
interests: [ "Museums", "Working Out", "Movies" ],
favoriteMovies: [
{ imdbId: "tt0112508", title: "Billy Madison" },
{ imdbId: "tt0116483", title: "Happy Gilmore" },
{ imdbId: "tt0103064", title: "Terminator 2: Judgment Day" }
]
},
{
_id: "friend:joanna",
type: "friend",
name: "Joanna",
age: 29,
interests: [ "Working Out", "Poetry", "Dancing" ],
favoriteMovies: [
{ imdbId: "tt0210075", title: "Girlfight" },
{ imdbId: "tt0179116", title: "But I'm a Cheerleader" },
{ imdbId: "tt0112697", title: "Clueless" }
]
}
]);
return( promise );
}
).then(
function() {
// The .find() plugin allow us to search both the primary key index as
// well as the indices we create using .createIndex(). Let's select a
// subset of friends using a range on the primary key.
var promise = db.find({
selector: {
_id: {
$gte: "friend:",
$lte: "friend:kim"
}
}
});
promise.then(
function( results ) {
console.group( "ONE: Found %s friends by _ID range.", results.docs.length );
results.warning && console.warn( results.warning );
results.docs.forEach(
function( doc ) {
console.log( doc.name, "-", doc._id );
}
);
console.groupEnd();
}
);
return( promise );
}
).then(
function() {
// The .find() plugin will also search secondary indices; but, only the
// indices created using the .find() plugin (presumably because those
// are the only indices that offer insight into which fields were emitted
// during the index population).
var promise = db.createIndex({
index: {
fields: [ "type", "age" ]
}
});
return( promise );
}
).then(
function() {
// Now that we have our [ type, age ] secondary index, we can search
// the documents using both Type and Age.
var promise = db.find({
selector: {
type: "friend",
age: {
$gte: 30,
$lt: 50
}
}
});
promise.then(
function( results ) {
console.group( "TWO: Found %s friends by AGE.", results.docs.length );
results.warning && console.warn( results.warning );
results.docs.forEach(
function( doc ) {
console.log( doc.name, "-", doc.age );
}
);
console.groupEnd();
}
);
return( promise );
}
).then(
function() {
// In the previous example, we used all of the fields [ Type, Age ] in
// the query's selector; but, we can also use an index PREFIX to locate
// documents efficiently. In this case, we'll use the [ Type, Age ] to
// search for friends REGARDLESS OF AGE; then, we'll perform some
// additional IN-MEMORY filtering based on favorite movies.
var promise = db.find({
selector: {
type: "friend",
// In order to leverage the index we created above (for Type and
// Age), we have to include all the fields that were part of the
// index definition. However, since we don't actually care about
// the Age for this query, we can use a "wildcard" (so to speak).
// --
// NOTE: Using the {} as the field equality (complex key range)
// is the same as explicitly defining the range:
// --
// age: {
// $gte: null,
// $lte: {}
// }
age: {},
// CAUTION: The $elemMatch operator is an IN-MEMORY OPERATOR,
// which means that it cannot be run against an index. As such,
// we have to rely on the preceding "key prefix" index to return
// the bulk of the payload.
favoriteMovies: {
$elemMatch: {
imdbId: {
$eq: "tt0112697" // Clueless.
}
// NOTE: In the preceding condition, you CANNOT used the
// implied equality operator (imdbId: "abc"). Doing so
// throws the rather confusing error:
// --
// Error: unknown operator "0" - should be one of $eq,
// $lte, $lt, $gt, $gte, $exists, $ne, $in, $nin, $size,
// $mod, $regex, $elemMatch, $type or $all
}
}
}
});
promise.then(
function( results ) {
console.group( "THREE: Found %s friends by IMDB-ID.", results.docs.length );
results.warning && console.warn( results.warning );
results.docs.forEach(
function( doc ) {
console.log( doc.name, "-", doc.favoriteMovies );
}
);
console.groupEnd();
}
);
return( promise );
}
).then(
function() {
// Now, let's create an index on the Interests field.
// --
// CAUTION: This MAY NOT DO WHAT YOU THINK IT DOES. PouchDB doesn't
// index the sub-items of the field - it indexes the entire field as
// a blackbox.
var promise = db.createIndex({
index: {
fields: [ "interests" ]
}
});
return( promise );
}
).then(
function() {
// Let's try to search for friends that have an interest in movies.
// --
// CAUTION: Only equality-based operators can be run against an index.
// In this case, we're using $in, which means that this will be forced
// to run IN-MEMORY.
var promise = db.find({
selector: {
interests: {
$in: [ "Movies" ]
}
}
});
promise.then(
function( results ) {
console.group( "FOUR: Found %s friends by interest.", results.docs.length );
results.warning && console.warn( results.warning );
results.docs.forEach(
function( doc ) {
console.log( doc.name, "-", doc.interests.toString() );
}
);
console.groupEnd();
}
);
return( promise );
}
).then(
function() {
// Since equality-based operators can be used to search an index, we can
// try to search for friends that have the EXACT COLLECTION OF INTERESTS.
// --
// NOTE: The order of the sub-items here must be exactly correct.
var promise = db.find({
selector: {
interests: {
$eq: [ "Working Out", "Poetry", "Dancing" ]
}
}
});
promise.then(
function( results ) {
console.group( "FIVE: Found %s friends by interests ARRAY.", results.docs.length );
results.warning && console.warn( results.warning );
results.docs.forEach(
function( doc ) {
console.log( doc.name, "-", doc.interests.toString() );
}
);
console.groupEnd();
}
);
return( promise );
}
).catch(
function( error ) {
console.warn( "An error occurred:" );
console.error( error );
}
);
</script>
</body>
</html>
Hopefully, this walkthrough of the PouchDB query plan debugging makes it a bit more clear on how this information can help you understand your query performance. I find this output to be particularly helpful for queries that do some index-based filtering and some in-memory filtering, especially when I had assumed that all filtering was being done at the index level. If nothing else, perhaps this sheds a bit more light on how the .find() plugin proxies the underlying .allDocs() and .query() methods.
Want to use code from this post? Check out the license.

Reader Comments
Hi, Ben!
Thanks for post, very useful.
PouchDB is a very cool tool. But it can't work faster with a complex queries. Especial if your db is too big and you use it on mobile devices like me.
I faced with this problem in my Cordova mobile apps. For instance I use a several SQLite databases (a database per document type) and every db has about 10K - 40K documents. Also I use queries with variable parameters in various ordering.
As I understand PouchDB execute too many SQL queries (a query per document, at least it's actual for the PouchDB.query method).
In the end I call the PouchDB.query method with include_docs = false parameter and then I use kind of hack single SQL with IN operator.
Now, I've implemented "relation index" plugin. It's table with predefined columns. So, as result one request - one SQL query, also I can use LIKE and IN operators.
Thanks.
P.S. Sorry for my bad English ))
@Thor,
Very interesting feedback. I haven't really used PouchDB with anything "big" yet - mostly just research and development; as such, I can't really speak to performance at such a large database size.
That said, I wonder if you are missing a secondary index on the data you trying to read. Or perhaps you are doing too much filtering in-memory on that 10-40K collection of documents? These are all just guesses, though, since I haven't done anything at that size yet.
Under the hood, PouchDB is using some sort of database, whether its IndexedDB or SQLite? So, I think it should be able to properly leverage indexes. I wonder what is going on.
Hey Ben,
This is a fantastic article. I'm busy working on `use_index` which would allow you to set which index you want to use for a query. As well as the `.explain` endpoint. This would then return a json object explaining how the query would be run. The work is here https://github.com/pouchdb/pouchdb/pull/6497
The PouchDB docs could really do with some of these details to help people with PouchDB-find. If you get a chance, and are comfortable doing it, could you add something like this to the PouchDB docs?
@Garren,
I'd be happy to help :) You guys are putting so much goodness out there.
@Ben,
That would be fantastic. Let me know how I can help you with it