
Experimenting With The Mango .find() API In PouchDB 6.2.0
Earlier this week, Garren Smith announced the release of PouchDB 6.2.0 which includes the find-plugin based on CouchDB's Mango search functionality. Mango - which is a play on MongoDB - creates a unified search interface that weaves together the creation and consumption of both the primary index and the secondary indices. This makes indices easier to use, as the details are abstracted away from you; however, to someone who is used to creating indices with a Design doc and a mapping function, the .find() plugin feels a little confusing as first. So, I thought it would be worth while to do a little exploration.
Run this demo in my JavaScript Demos project on GitHub.
In my previous PouchDB playground, I used Design docs and explicit map() functions to create indices that could then be consumed by the map-reduce query() method. According to the documentation, the new createIndex() and find() methods are actually built on top of the same map-reduce functionality; however, they appear to be completely separate concepts. Meaning, indices that you manually create with a Design doc don't show up in the getIndexes() method; and, those indices don't appear to be used by the find() method's underlying query-selection algorithm (at least from what I can see in the debugging). As such, I believe the two [secondary index] approaches for data gathering should be viewed as unrelated constructs within the PouchDB ecosystem.
NOTE: Cloudant includes a "use_index" property which tells the .find() method which index to use. This could theoretically be used one day to tell .find() to use an index that was created from an explicit Design document. But, this is not currently a supported feature.
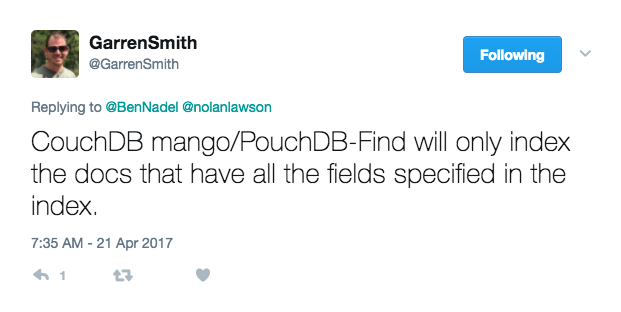
With the original map-reduce approach to creating indices, you have complete control over which documents and fields get indexed. As such, you can build an index that will only ever contain a specific subset of PouchDB documents. With the Mango createIndex() approach, what you gain in ease-of-use you lose in granularity. Now, according to Garren Smith, the createIndex() method will only index documents that contain all of the fields listed in the index:
The limitation with this approach is that, in a document store that has no inherent concept of Collections, basing an index on a list of fields is not very future-proof. Just thinking about some of my production work, many different entities have a common parent foreign-key field like "projectID" or "userID". Of course, when I use "projectID" to search, I often want to limit that search to a particular "type" of document.
With PouchDB's new createIndex() method, we can future-proof our indicies using two different approaches. First, we can add some sort of "type" field, like:
fields: [ "docType", "projectId" ]
... where the "docType" field helps break the mono-collection into meaningful segments. Of course, this puts all of the documents into a single index. And, to be honest, I don't know if this is actually a problem or not. My gut tells me that smaller indices are better; but, I don't know if my gut is right. That said, we can get around the larger indices by building the "type" into the field name. Meaning, we could create indices like:
fields: [ "type_asset", "projectId" ]
fields: [ "type_note", "projectId" ]
fields: [ "type_screen", "projectId" ]
Here, the document type is actually part of one of the field names, rather than the "value" of the field. And, since Mango will only include documents that contain all of the given fields, this latter approach will end up creating separate indices that only include a specific segment of the mono-collection.
Of course, as I was learning about PouchDB for the first time, I kept reading that you should use and abuse the primary key index - the index implicitly created on the "_id" field. So, for example, we could build the "type" of the document into the actual document _id. Something like:
_id: `friend:${ friendId }`
This gives us the ability to gather all "friend" type documents by searching for keys between "friend:null" and "friend:\uffff". But, it then means we can't create a compound index on one of the embedded fields. That said, Mango's find() mechanism will allow in-memory filtering. So, we could use the primary key index to select a "collection" segment and then use non-indexed fields to do additional in-memory filtering.
Of course, we could always build some relational data right into the _id as well, really "using and abusing" the primary key index:
_id: `screen:${ projectId }:${ screenId }`
This would give us the ability to search for a screen by ID (the full _id value); and, give us the ability to search for all screens in a given project by using the _id prefix, "screen:${ projectId }".
But, which is better? Is it better to have fewer indices that contain documents you don't necessarily want? Or more indices that have clearly-defined boundaries? Is it better to create compound indices that can "cover" an entire query? Or use the primary key index with additional in-memory filtering? Is it better to use PouchDB's new Mango find()? Or, should we keep using the more granular map-reduce query() method?
To be honest, I have no idea. I could say, "it depends"; but, let's be honest - "it depends" is really just fancy way of saying, "I have no idea." The truth is, index creation in earlier versions of PouchDB felt like more of an art than a science; and now, with a completely parallel way of indexing and searching documents, the process continues to feel even more like an artform.
That said, let's take a look at how the createIndex() and find() methods can be used in PouchDB 6.2.0. First, let's create and populate the PouchDB database:
var dbName = "javascript-demos-pouchdb-find-playground";
// Enable debugging to so we can see the query-plan that .find() chooses.
// --
// PouchDB.debug.enable( "pouchdb:find" );
// Creating the PouchDB database instance is a synchronous operation. This means
// that we can immediately start to interact with the "db" object.
var db = new PouchDB( dbName );
// When I am playing around with PouchDB, I like to destroy and recreate the
// database on each test run. This way, any conflicts with existing data are
// explicitly coded into the experiment and not a byproduct of dirty data.
db.destroy().then(
function() {
// Once we destroy the database, we have to create a new one otherwise
// we'll get an error, "Error: database is destroyed".
db = new PouchDB( dbName );
}
)
// At this point, we have a pristine PouchDB instance to experiment with. Every
// PouchDB operation returns a Promise (though you could use a Callback if you
// wanted to for some reason). So, to start experimenting, we can just chain the
// "thenable" operations together.
.then(
function() {
// Let's insert some Friend data.
// --
// NOTE: I am building a "COLLECTION_FRIEND" property into each document.
// Normally, I would pick apart the type based solely on the _id format.
// However, with the new mango queries, we cannot use the _id format as
// part of the index creation (since the Mango secondary incides are
// based on embedded fields). As such, the COLLECTION_FRIEND property
// will help us create future-proof indices and indices that only include
// relevant documents.
var promise = db.bulkDocs([
{
_id: "friend:kim",
name: "Kim",
age: 42,
interests: [ "Movies", "Computers", "Cooking" ],
collection_friend: true
},
{
_id: "friend:sarah",
name: "Sarah",
age: 35,
interests: [ "Museums", "Working Out", "Movies" ],
collection_friend: true
},
{
_id: "friend:joanna",
name: "Joanna",
age: 29,
interests: [ "Working Out", "Poetry", "Dancing" ],
collection_friend: true
},
// Let's add some garbage documents as well in order to ensure that
// our subsequent queries don't try to pull back more data that we
// anticipate (ie, none of these documents should show up).
{
_id: "a",
collection_garbage: true
},
{
_id: "z",
collection_garbage: true
}
]);
return( promise );
}
)
With this collection of Friends, you can see that I am building the "type" into both the _id schema as well as creating an embedded field called, "collection_friend". This way, when I go to create secondary indices later with .createIndex(), I can use this field as the index prefix to ensure that I only include a specific subset of documents.
Of course, even before we create any secondary indices, we can use the new .find() method to query the default primary key index:
.then(
function() {
// Now that we've inserted our Friends, we can immediately access those
// friends using the "default" index (ie, the one implicitly created on
// the _id field).
// --
// CAUTION: This does NOT SEEM TO BE THE CASE with the $in operator.
// While you might expect this to map directly to the allDocs() "keys"
// filter, .find() will warn us that NO INDEX could be found.
var promise = db.find({
selector: {
_id: {
$in: [ "friend:kim", "friend:sarah" ]
}
// NOTE: Trying to use the $or operator also gives us a warning:
// --
// $or: [
// { _id: "friend:kim" },
// { _id: "friend:sarah" }
// ]
}
});
promise.then(
function( results ) {
console.group( "ONE: Found %s friends by _id.", results.docs.length );
console.info( "{ _id: { $in: [ 'friend:kim', 'friend:sarah' ] }" );
results.warning && console.warn( results.warning );
results.docs.forEach(
function( doc ) {
console.log( doc.name, "-", doc._id );
}
);
console.groupEnd();
}
);
return( promise );
}
)
Here, I am assuming that we can search for multiple _id's using the $in operator. I had assumed that this would map onto the allDocs() "keys" selector. However, when we run this code, we get a warning in our output:

As you can see, the .find() plugin is warning us that it could not match an index for our query. As such, it ended up doing a full collection scan followed-by an in-memory filter. I *********** suspect that this is a bug; and, that multiple _id values can be properly translated into an index-based query.
There's an even more compelling reason to believe that this is a bug which is that range-based queries do seem to work on the primary key index:
.then(
function() {
// In addition to being able to search for a set of _id values (or rather
// not being able to - SEE CAUTION ABOVE), we can also search for a range
// of _id values.
// --
// NOTE: This runs without a warning and I assume this maps to the
// .allDocs() "startKey" and "endKey", which is why it's so strange that
// the $in operator doesn't work.
var promise = db.find({
selector: {
_id: {
$gt: "friend:",
$lt: "friend:\uffff"
}
}
});
promise.then(
function( results ) {
console.group( "TWO: Found %s friends by _id.", results.docs.length );
console.info( "{ _id: { $gt: 'friend:', $lt: 'friend:\uffff' } }" );
results.warning && console.warn( results.warning );
results.docs.forEach(
function( doc ) {
console.log( doc.name, "-", doc._id );
}
);
console.groupEnd();
}
);
return( promise );
}
)
This looks for all document _id's with a "friend:" prefix. And, when we run this, we get the following output:

As you can see, this query was able to locate all three friend documents using the primary key index (no warnings were emitted).
The .find() selector doesn't have to be completely covered by the primary key index. Mango can select an initial set of documents using the primary key index and then do additional in-memory filtering. For example, in the following code, we're going to collect documents based on the "friend:" prefix; then, we'll do additional in-memory filtering based on age:
.then(
function() {
// Using .find(), we can also mix the way data is filtered. For example,
// we can mix the primary key index (or any index for that matter), with
// in-memory filtering. In this case, we're going to use the primary key
// index to select a subset of documents; then, we're going to use
// implicit in-memory filtering to further narrow down documents by age.
var promise = db.find({
selector: {
_id: {
$gt: "friend:",
$lt: "friend:\uffff"
},
// There is NO INDEX on age - the .find() method will be doing
// in-memory filtering once it retrieves the documents based on
// the default index.
age: {
$gt: 40
}
}
});
promise.then(
function( results ) {
console.group( "THREE: Found %s friends by _id AND age.", results.docs.length );
console.info( "{ _id: { $gt: 'friend:', $lt: 'friend:\uffff' }, age: { $gt: 40 } }" );
results.warning && console.warn( results.warning );
results.docs.forEach(
function( doc ) {
console.log( doc.name, "-", doc.age );
}
);
console.groupEnd();
}
);
return( promise );
}
)
When we run this code, we successfully locate the one friend document with age over 40:

As you can see, the primary / default index is powerful and can get us pretty far. But, once we want to start performing more field-oriented queries, we have to start creating secondary indices on those fields. In the following example, we're going to create an index on "interests" so that we can start looking up friends by interest:
UPDATE APRIL 26, 2017: In the following code, I am indicating that the "interests" field is being index. And, I thought it was. But, from what I have read recently, arrays do not get indexed in PouchDB (currently). As such, the following demo is only really using the key prefix for "collection_friend". The second field, "interests", is not adding any value to the index and causes the $in operator to be an in-memory filter.
.then(
function() {
// Once we want to go past the default _id based index, we have to create
// explicit indices. In this case, let's create an index that allows us
// to search friends by Interest. When creating an index, mango will only
// index documents that contain ALL OF THE KEYS. As such, we can use the
// COLLECTION_FRIEND categorization key to ensure that only Friend
// documents are included in this index. This also serves to future-proof
// the index in case other document types get added later that include a
// key called "interests".
var promise = db.createIndex({
index: {
fields: [ "collection_friend", "interests" ]
}
});
return( promise );
}
).then(
function() {
// Now that we have our index in place, we can find all of the friends
// that like "Movies". Again, we are using the arbitrary "type" field,
// "collection_friend" to filter the mono-collection into a meaningful
// subset of documents.
var promise = db.find({
selector: {
collection_friend: true,
interests: {
$in: [ "Movies" ]
}
}
});
promise = promise.then(
function( results ) {
console.group( "FOUR: Found %s friends that like Movies.", results.docs.length );
console.info( "{ collection_friend: true, interests: { $in: [ 'Movies' ] } }" );
results.warning && console.warn( results.warning );
results.docs.forEach(
function( doc ) {
console.log( doc.name, "-", doc.interests.toString() );
}
);
console.groupEnd();
}
);
return( promise );
}
)
As I discussed above, the most limiting factor of the Mango secondary index configuration is that you can't inspect the _id value when segmenting documents. As such, I'm including the "collection_friend" field as the index prefix. This way, the index will never contain documents outside of the friend pseudo-collection (ie, segment of the mono-collection) since no other types of document will ever contain this field. Then, when we query for documents on this index, we just need to include the "collection_friend" field to target the right index:

As you can see, we were able to use the secondary index to find friends who like movies.
The new Mango .createIndex() and .find() methods are definitely compelling. I love the simplified .find() interface. And, I really like that it can search both the primary index and the secondary indices; but, I definitely feel a bit fuzzy on how to draw the lines around the various ways to create and consume indices. Hopefully, this kind of wisdom will come with more PouchDB experience.
For completeness, here's the entire code sample from above:
<!doctype html>
<html>
<head>
<meta charset="utf-8" />
<title>
Experimenting With PouchDB 6.2.0 And The New Mango .find() Plugin
</title>
</head>
<body>
<h1>
Experimenting With PouchDB 6.2.0 And The New Mango .find() Plugin
</h1>
<p>
<em>Look at console — things being logged, yo!</em>
</p>
<script type="text/javascript" src="../../vendor/pouchdb/6.2.0/pouchdb-6.2.0.min.js"></script>
<!--
NOTE: When running this in the browser, the Find() plugin will AUTOMATICALLY
inject itself into the PouchDB global object. We don't have to wire this up
explicitly (except when running in node).
-->
<script type="text/javascript" src="../../vendor/pouchdb/6.2.0/pouchdb.find.js"></script>
<script type="text/javascript">
var dbName = "javascript-demos-pouchdb-find-playground";
// Enable debugging to so we can see the query-plan that .find() chooses.
// --
// PouchDB.debug.enable( "pouchdb:find" );
// Creating the PouchDB database instance is a synchronous operation. This means
// that we can immediately start to interact with the "db" object.
var db = new PouchDB( dbName );
// When I am playing around with PouchDB, I like to destroy and recreate the
// database on each test run. This way, any conflicts with existing data are
// explicitly coded into the experiment and not a byproduct of dirty data.
db.destroy().then(
function() {
// Once we destroy the database, we have to create a new one otherwise
// we'll get an error, "Error: database is destroyed".
db = new PouchDB( dbName );
}
)
// At this point, we have a pristine PouchDB instance to experiment with. Every
// PouchDB operation returns a Promise (though you could use a Callback if you
// wanted to for some reason). So, to start experimenting, we can just chain the
// "thenable" operations together.
.then(
function() {
// Let's insert some Friend data.
// --
// NOTE: I am building a "COLLECTION_FRIEND" property into each document.
// Normally, I would pick apart the type based solely on the _id format.
// However, with the new mango queries, we cannot use the _id format as
// part of the index creation (since the Mango secondary incides are
// based on embedded fields). As such, the COLLECTION_FRIEND property
// will help us create future-proof indices and indices that only include
// relevant documents.
var promise = db.bulkDocs([
{
_id: "friend:kim",
name: "Kim",
age: 42,
interests: [ "Movies", "Computers", "Cooking" ],
collection_friend: true
},
{
_id: "friend:sarah",
name: "Sarah",
age: 35,
interests: [ "Museums", "Working Out", "Movies" ],
collection_friend: true
},
{
_id: "friend:joanna",
name: "Joanna",
age: 29,
interests: [ "Working Out", "Poetry", "Dancing" ],
collection_friend: true
},
// Let's add some garbage documents as well in order to ensure that
// our subsequent queries don't try to pull back more data that we
// anticipate (ie, none of these documents should show up).
{
_id: "a",
collection_garbage: true
},
{
_id: "z",
collection_garbage: true
}
]);
return( promise );
}
).then(
function() {
// Now that we've inserted our Friends, we can immediately access those
// friends using the "default" index (ie, the one implicitly created on
// the _id field).
// --
// CAUTION: This does NOT SEEM TO BE THE CASE with the $in operator.
// While you might expect this to map directly to the allDocs() "keys"
// filter, .find() will warn us that NO INDEX could be found.
var promise = db.find({
selector: {
_id: {
$in: [ "friend:kim", "friend:sarah" ]
}
// NOTE: Trying to use the $or operator also gives us a warning:
// --
// $or: [
// { _id: "friend:kim" },
// { _id: "friend:sarah" }
// ]
}
});
promise.then(
function( results ) {
console.group( "ONE: Found %s friends by _id.", results.docs.length );
console.info( "{ _id: { $in: [ 'friend:kim', 'friend:sarah' ] }" );
results.warning && console.warn( results.warning );
results.docs.forEach(
function( doc ) {
console.log( doc.name, "-", doc._id );
}
);
console.groupEnd();
}
);
return( promise );
}
).then(
function() {
// In addition to being able to search for a set of _id values (or rather
// not being able to - SEE CAUTION ABOVE), we can also search for a range
// of _id values.
// --
// NOTE: This runs without a warning and I assume this maps to the
// .allDocs() "startKey" and "endKey", which is why it's so strange that
// the $in operator doesn't work.
var promise = db.find({
selector: {
_id: {
$gt: "friend:",
$lt: "friend:\uffff"
}
}
});
promise.then(
function( results ) {
console.group( "TWO: Found %s friends by _id.", results.docs.length );
console.info( "{ _id: { $gt: 'friend:', $lt: 'friend:\uffff' } }" );
results.warning && console.warn( results.warning );
results.docs.forEach(
function( doc ) {
console.log( doc.name, "-", doc._id );
}
);
console.groupEnd();
}
);
return( promise );
}
).then(
function() {
// Using .find(), we can also mix the way data is filtered. For example,
// we can mix the primary key index (or any index for that matter), with
// in-memory filtering. In this case, we're going to use the primary key
// index to select a subset of documents; then, we're going to use
// implicit in-memory filtering to further narrow down documents by age.
var promise = db.find({
selector: {
_id: {
$gt: "friend:",
$lt: "friend:\uffff"
},
// There is NO INDEX on age - the .find() method will be doing
// in-memory filtering once it retrieves the documents based on
// the default index.
age: {
$gt: 40
}
}
});
promise.then(
function( results ) {
console.group( "THREE: Found %s friends by _id AND age.", results.docs.length );
console.info( "{ _id: { $gt: 'friend:', $lt: 'friend:\uffff' }, age: { $gt: 40 } }" );
results.warning && console.warn( results.warning );
results.docs.forEach(
function( doc ) {
console.log( doc.name, "-", doc.age );
}
);
console.groupEnd();
}
);
return( promise );
}
).then(
function() {
// Once we want to go past the default _id based index, we have to create
// explicit indices. In this case, let's create an index that allows us
// to search friends by Interest. When creating an index, mango will only
// index documents that contain ALL OF THE KEYS. As such, we can use the
// COLLECTION_FRIEND categorization key to ensure that only Friend
// documents are included in this index. This also serves to future-proof
// the index in case other document types get added later that include a
// key called "interests".
var promise = db.createIndex({
index: {
fields: [ "collection_friend", "interests" ]
}
});
return( promise );
}
).then(
function() {
// Now that we have our index in place, we can find all of the friends
// that like "Movies". Again, we are using the arbitrary "type" field,
// "collection_friend" to filter the mono-collection into a meaningful
// subset of documents.
var promise = db.find({
selector: {
collection_friend: true,
interests: {
$in: [ "Movies" ]
}
}
});
promise = promise.then(
function( results ) {
console.group( "FOUR: Found %s friends that like Movies.", results.docs.length );
console.info( "{ collection_friend: true, interests: { $in: [ 'Movies' ] } }" );
results.warning && console.warn( results.warning );
results.docs.forEach(
function( doc ) {
console.log( doc.name, "-", doc.interests.toString() );
}
);
console.groupEnd();
}
);
return( promise );
}
).catch(
function( error ) {
console.warn( "An error occurred:" );
console.error( error );
}
);
</script>
</body>
</html>
Want to use code from this post? Check out the license.

Reader Comments
@All,
This morning, I took a look at monkey-patching the .find() plugin to route the $in-based selector to use the .allDocs() method so that we can actually use the primary key index:
www.bennadel.com/blog/3256-monkey-patching-the-mango-find-plugin-to-use-alldocs-in-pouchdb-6-2-0.htm
Of course, this only works if the selector criteria is sufficiently simple.
Hi Ben,
This is a really great article. I agree with you, I think the warning when using $in with the _id index is a bug. I've created a ticket here https://github.com/pouchdb/pouchdb/issues/6447 to investigate this further.
@Garren,
Very cool, thanks for doing that. For funzies, I did see if I could create another `.find()` plugin that essentially monkey-patches your `.find()` and just uses `.allDocs()` for that specific type of query. But, it sounds like the warning was the error, not the code-path.
I read that post. It was really cool, I have another idea for you for that post. It is possible to use allDocs() and then just use the find matchers which would make it a lot more generic and you wouldn't need to monkey patch it. I will try and do an example for you in a day or two.
I'm not 100% what the issue is here. I need to dig in a bit deeper. I'll reply back here once I know more.
@Garren,
Sounds like a plan -- I appreciate the feedback!
@All,
I believe that my code demo is misleading when it comes to indexing arrays. From what I have just read (and experimented with), Arrays do not get indexed. So, when I tried to create an index that included "Interests:"
fields: [ "collection_friend", "interests" ]
... the latter half of that index wasn't actually acting like I thought it was. Or, more specifically, when I went to query for documents after creating that index:
selector: {
collection_friend: true,
interests: { $in: [ "Movies" ] }
}
... that ONLY USING the KEY PREFIX of "collection_friend". Then, it's doing an in-memory filter for the $in operator on the interests. As such, there's no need to even include the "interests" in the index as it will not add any performance gain and, will at best, be misleading (as I have clearly mislead myself).
... here's some more information on the limitations to index arrays:
https://issues.apache.org/jira/browse/COUCHDB-2867
@All,
After reading Garren's blog post from 2015:
http://www.redcometlabs.com/blog/2015/12/1/a-look-under-the-covers-of-pouchdb-find
... I'd like to more clearly articulate the problem with the "Interests" index. If you include the "interests" field in the index creation, the underlying emit will look like this:
emit( doc.collection_friend, doc.interests )
... which can be used in a query; but, only as an equality operator, not the $in operator. The reason for this is that the "interests" field gets indexes as a single object - not a collection of values - and can only be compared to a single object during a query.
@All,
When I first looked at .find(), the debugging output of the query analyzer was confusing and noisy, so I just turned it off. But, now that I have a better sense of where the .find() plugin sits in the PouchDB architecture, the query analyzer output makes a lot more sense:
www.bennadel.com/blog/3258-understanding-the-query-plan-explained-by-the-find-plugin-in-pouchdb-6-2-0.htm
I wanted to put together a quick walk-through in case anyone else was confused by the output and didn't know how to leverage it.