
Ask Ben: Destructuring Complex Queries Into ColdFusion Objects
On Friday, I received an "Ask Ben" question that thoroughly nerd sniped me and ended up taking up my last three mornings. I'm paraphrasing here; but, a reader asked me how they could take a JOIN-based query object and collate it within ColdFusion such that they could flatten the groupings into a developer-friendly data structure. This is something that I do all the time. But, I usually use a brute force methodology. The part that nerd sniped me was a desire to see if I could do this work declaratively in ColdFusion.
The JOIN-Based Demo Data
Most databases these days have JSON (JavaScript Object Notation) functions which allow groupings to be transformed and flattened into aggregate data structures within the SQL syntax itself. For example, MySQL has JSON_ARRAYAGG() and JSON_OBJECTAGG() functions. But, I didn't want to make this a database-oriented solution (especially since the reader is using Microsoft SQL Server, which I'm much less familiar with).
I wanted to define the solution in the ColdFusion space so that it is more generalized; and, it gives me access to much more logic. That said, I did need data to work with. So, I manually constructed a ColdFusion query object using the queryNew() function.
The sample data takes inspiration from my InVision days, where we had "projects", which contained "screens", which contained "conversations", which contained "comments", which contained "users". My sample query (records) is the simulation of an INNER JOIN across these various constructs:
<cfscript>
/*
COULD be generated from a complex INNER JOIN sturcture, such as:
--
FROM project p
JOIN screen s ON s.projectID = p.id
JOIN conversation cv ON cv.screenID = s.id
JOIN comment c ON c.conversationID = cv.id
JOIN user u ON u.id = c.userID
JOIN role r ON r.id = u.roleID
*/
records = queryNew(
" projectID, projectName, screenID, screenName, conversationID, conversationLabel, conversationX, conversationY, commentID, commentText, userID, userEmail, roleID, roleName",
" integer, varchar, integer, varchar, integer, varchar, integer, integer, integer, varchar, integer, varchar, integer, varchar",
[
[ 8037, "Auth Redesign", 1, "Login", 11, "1", 103, 249, 111, "Please make the button red.", 4, "ben@example.com", 1009, "Engineer" ],
[ 8037, "Auth Redesign", 1, "Login", 11, "1", 103, 249, 112, "Why red?", 53, "lara@example.com", 1008, "Manager" ],
[ 8037, "Auth Redesign", 1, "Login", 11, "1", 103, 249, 113, "It's my fave!", 4, "ben@example.com", 1009, "Engineer" ],
[ 8037, "Auth Redesign", 1, "Login", 11, "1", 103, 249, 114, "Ok, you got it.", 53, "lara@example.com", 1008, "Manager" ],
[ 8037, "Auth Redesign", 1, "Login", 12, "2", 200, 578, 121, "Add a forgot-password link.", 17, "ted@example.com", 1007, "Compliance" ],
[ 8037, "Auth Redesign", 2, "Sign-Up", 21, "1", 10, 10, 211, "Add logo link back to login.", 17, "ted@example.com", 1007, "Compliance" ],
[ 8037, "Auth Redesign", 2, "Sign-Up", 21, "1", 10, 10, 212, "Can I include 'back' text?", 4, "ben@example.com", 1009, "Engineer" ],
[ 8037, "Auth Redesign", 2, "Sign-Up", 21, "1", 10, 10, 213, "Yes, adding clarity is good.", 17, "ted@example.com", 1007, "Compliance" ],
[ 8037, "Auth Redesign", 3, "Forgot Password", 31, "1", 10, 10, 311, "Always add logo back to login.", 17, "ted@example.com", 1007, "Compliance" ],
[ 8037, "Auth Redesign", 3, "Forgot Password", 32, "2", 400, 252, 312, "Include link to TOS.", 17, "ted@example.com", 1007, "Compliance" ],
[ 8037, "Auth Redesign", 3, "Forgot Password", 33, "3", 450, 255, 313, "Include link to privacy policy.", 17, "ted@example.com", 1007, "Compliance" ],
[ 8037, "Auth Redesign", 3, "Forgot Password", 33, "3", 450, 255, 314, "We don't have one yet.", 99, "naomi@example.com", 1009, "Engineer" ],
[ 8037, "Auth Redesign", 3, "Forgot Password", 33, "3", 450, 255, 315, "Please talk to Eve in legal.", 17, "ted@example.com", 1007, "Compliance" ],
[ 8037, "Auth Redesign", 3, "Forgot Password", 33, "3", 450, 255, 316, "Will do!", 99, "naomi@example.com", 1009, "Engineer" ]
]
);
</cfscript>
What I'm going to do the rest of this post is explore ways to output this complex query object as a series of nested groupings:
- by Screen
- by Conversation
- by Comment
Using ColdFusion's Native CFOutput[Group] Tag
Out of the box, ColdFusion's CFOutput tag has a way to group the output of a query object. If you provide the CFOutput tag with a group attribute, it will limit the output to a single record. Then, you can defined nested CFOutput tags which will iterate over the records within that group.
Aside: I almost never use this particular mechanic because Adobe ColdFusion (even as of 2025) doesn't allow this to be done within the context of a non-grouped
CFOutput. Meaning, if the entire page is wrapped in a<cfoutput>tag, which is generally my approach to CFML templates, Adobe ColdFusion will throw an error about illegal nesting when I try to use the<cfoutput[group]>syntax farther down in template.For what it's worth, Lucee CFML does not have this constraint.
In the following CFML code, I will include the aforementioned sample data and then define a series of nested CFOutput tags:
<cfoutput query="records" group="screenID"><cfoutput group="conversationID"><cfoutput group="commentID">
Notice that the query attribute is only defined on the first tag - the rest of the tags will implicitly use the groupings defined by the root cfoutput:
<!--- Defines our query object as the "records" variable. --->
<cfinclude template="./sample-data.cfm" />
<h1>
Nested Output With CFOutput[ Group ]
</h1>
<dl>
<!--- FIRST, group by screen. --->
<cfoutput query="records" group="screenID" encodeFor="html">
<div>
<dt>
<strong>Screen #records.screenID#</strong> -
#records.screenName#
<em>(#records.projectName#)</em>
</dt>
<dd>
<dl>
<!--- SECOND, group by conversation. --->
<cfoutput group="conversationID">
<div>
<dt>
<strong>Conversation #records.conversationID#</strong> -
{
label: #records.conversationLabel#,
x: #records.conversationX#,
y: #records.conversationY#
}
</dt>
<dd>
<dl>
<!--- THIRD, group by comment. --->
<cfoutput group="commentID">
<div>
<dt>
<strong>Comment: #records.commentID#</strong> -
#records.userEmail#
(#records.roleName#)
</dt>
<dd>
<em>#records.commentText#</em>
</dd>
</div>
</cfoutput>
</dl>
</dd>
</div>
</cfoutput>
</dl>
</dd>
</div>
</cfoutput>
</dl>
If I run this ColdFusion code, I get the following page output:

As you can see, by using the CFOutput[group] mechanics, we were able to take the "deeply nested" JOIN-data query and output it using a hierarchical control flow.
Using Brute-Force Destructuring ColdFusion Logic
I mentioned above that I normally wrap my entire CFML template in <cfoutput>, which implicitly precludes me from using the above mechanics. As such, when I have to output this kind of complex data—or prepare a complex API response—I traditionally use a more brute-force approach.
In the following CFML code, I'm doing what the ColdFusion CFOutput tag was doing for me implicitly; only, I'm doing it explicitly before rendering any output. Basically, I'm brute-force generating my own nested data structures by looping over the query recordset and building up my own groupings by keeping track of unique ID values during the iteration. Then, I output my intermediary data structure using a series of nested CFLoop tags:
<cfscript>
// Defines our query object as the "records" variable.
include "./sample-data.cfm";
// As we iterate over the records (which we know were SORTED in logical groupings),
// we're going to normalize the columns into a complex data structure. As we examine
// each row, we're going to see if a column VALUE indicates that we've entered a new
// object within this complex data structure.
screens = [];
// I'm starting with (-1) as the "current value" since we know that our UNSIGNED INT
// in the database will never accidentally collide with this value (though, we could
// have also just used an empty-string).
screen = { id: -1 };
conversation = { id: -1 };
for ( record in records ) {
// Did we enter a new block of SCREEN records?
if ( screen.id != record.screenID ) {
screen = [
id: record.screenID,
name: record.screenName,
conversations: [],
project: [
id: record.projectID,
name: record.projectName
]
];
screens.append( screen );
}
// Did we enter a new block of CONVERSATION records?
if ( conversation.id != record.conversationID ) {
conversation = [
id: record.conversationID,
label: record.conversationLabel,
x: record.conversationX,
y: record.conversationY,
comments: []
];
screen.conversations.append( conversation );
}
// We know that the "comment" is the most granular level. As such, we dont' have
// to check to ese if we've reached a new comment - every records is a comment.
conversation.comments.append([
id: record.commentID,
text: record.commentText,
user: [
id: record.userID,
email: record.userEmail,
role: [
id: record.roleID,
name: record.roleName
]
]
]);
}
</cfscript>
<cfoutput encodeFor="html">
<h1>
Nested Output With Brute Force Normalization
</h1>
<dl>
<!--- FIRST, group by screen. --->
<cfloop array="#screens#" item="screen">
<div>
<dt>
<strong>Screen #screen.id#</strong> -
#screen.name#
<em>(#screen.project.name#)</em>
</dt>
<dd>
<dl>
<!--- SECOND, group by conversation. --->
<cfloop array="#screen.conversations#" item="conversation">
<div>
<dt>
<strong>Conversation #conversation.id#</strong> -
{
label: #conversation.label#,
x: #conversation.x#,
y: #conversation.y#
}
</dt>
<dd>
<dl>
<!--- THIRD, group by comment. --->
<cfloop array="#conversation.comments#" item="comment">
<div>
<dt>
<strong>Comment: #comment.id#</strong> -
#comment.user.email#
(#comment.user.role.name#)
</dt>
<dd>
<em>#comment.text#</em>
</dd>
</div>
</cfloop>
</dl>
</dd>
</div>
</cfloop>
</dl>
</dd>
</div>
</cfloop>
</dl>
</cfoutput>
Notice that all of my CFOutput tags (less the one wrapping the entirety of the output) have been replaced by CFLoop tags. If I run this ColdFusion code, I get the same exact page output as above:

This brute-force technique is the one that I use most of the time.
Using a Declarative Grouping Syntax In ColdFusion
While the brute-force approach works well for me, the part of this question that nerd sniped me was the desire to see if I could abstract this logic behind some sort of declarative syntax. I always liked the way that TypeScript defined object interfaces; so, I took inspiration from TypeScript and used a similar type of syntax for my query definition.
This isn't perfect, but I finally settled on a syntax that looks like this:
{
"screens[screen:id]": {
"id": "",
"name": "",
"conversations[conversation:id]": {
"id": "",
"label": "",
"x": "",
"y": "",
"comments[comment:id]": {
"id": "",
"text": "",
"user": {
"id": "",
"email": "",
"role": {
"id": "",
"name": ""
}
}
}
},
"project": {
"id": "",
"name": ""
}
}
}
For the most part, I think this reads well; but there are some details that need explaining. This key:
"screens[screen:id]"
... translates to:
Create an array named
screens.All of the properties within each object (within this array) will be pulled from columns that are all prefixed with
screen.The unique identifier of each object (within this array) will be determined by the
idproperty of the extracted object.
Every other simple key-value defines the properties within an object. Most values are blank (""), which simply signifies that the value will be pulled from:
{prefix}{property}
If you need to override that logic, you can explicitly define the query column in the value field. Example:
"name": "my_query_column_for_name"
Here's the ColdFusion updated to use this declarative destructuring approach. The logic for the destrucuturing is encapsulated in the QueryNormalizer.cfc ColdFusion component, which I'll include later in the post.
In the following CFML code, the output / looping logic is exactly the same as it was above; the only difference is that I'm using the declarative syntax to break apart the query object:
<cfscript>
// Defines our query object as the "records" variable.
include "./sample-data.cfm";
screens = new QueryNormalizer().normalizeQuery(
records,
{
// Configuration format:
// { identifier }[ { prefix } : { unique identifier } ]
"screens[screen:id]": {
"id": "",
"name": "",
"conversations[conversation:id]": {
"id": "",
"label": "",
"x": "",
"y": "",
"comments[comment:id]": {
"id": "",
"text": "",
"user": {
"id": "",
"email": "",
"role": {
"id": "",
"name": ""
}
}
}
},
"project": {
"id": "",
"name": ""
}
}
}
);
</cfscript>
<cfoutput encodeFor="html">
<h1>
Nested Output With Recursive Destructuring
</h1>
<dl>
<!--- FIRST, group by screen. --->
<cfloop array="#screens#" item="screen">
<div>
<dt>
<strong>Screen #screen.id#</strong> -
#screen.name#
<em>(#screen.project.name#)</em>
</dt>
<dd>
<dl>
<!--- SECOND, group by conversation. --->
<cfloop array="#screen.conversations#" item="conversation">
<div>
<dt>
<strong>Conversation #conversation.id#</strong> -
{
label: #conversation.label#,
x: #conversation.x#,
y: #conversation.y#
}
</dt>
<dd>
<dl>
<!--- THIRD, group by comment. --->
<cfloop array="#conversation.comments#" item="comment">
<div>
<dt>
<strong>Comment: #comment.id#</strong> -
#comment.user.email#
(#comment.user.role.name#)
</dt>
<dd>
<em>#comment.text#</em>
</dd>
</div>
</cfloop>
</dl>
</dd>
</div>
</cfloop>
</dl>
</dd>
</div>
</cfloop>
</dl>
</cfoutput>
As you can see, the .normalizeQuery() method call takes the demo query object and the declarative syntax and returns the root-level groupings of screens. And, if I run this ColdFusion code, I get the same exact page output as above:

Kind of cool, right?
And, you don't have to group the output for this declarative syntax to work. If I wanted to, I could simply break each record apart into a set of objects:
<cfscript>
// Defines our query object as the "records" variable.
include "./sample-data.cfm";
data = new QueryNormalizer().normalizeQuery( records,
{
"project": {
"id": "",
"name": ""
},
"screen": {
"id": "",
"name": ""
},
"comment": {
"id": "",
"text": ""
},
"user": {
"id": "",
"email": ""
}
}
);
writeDump( data );
</cfscript>
As you can see here, there's no array syntax - each object is just destructured into a set of structs. The struct syntax can also define a column prefix. For example:
"project":
... is the same as:
"project{project}":
... which explicitly defines the prefix as project. This is helpful if the column names use _ to separate tokens. For example, we could define the project-based column prefix as project_:
"project{project_}":
If I run this ColdFusion code, I get the following truncated writeDump():
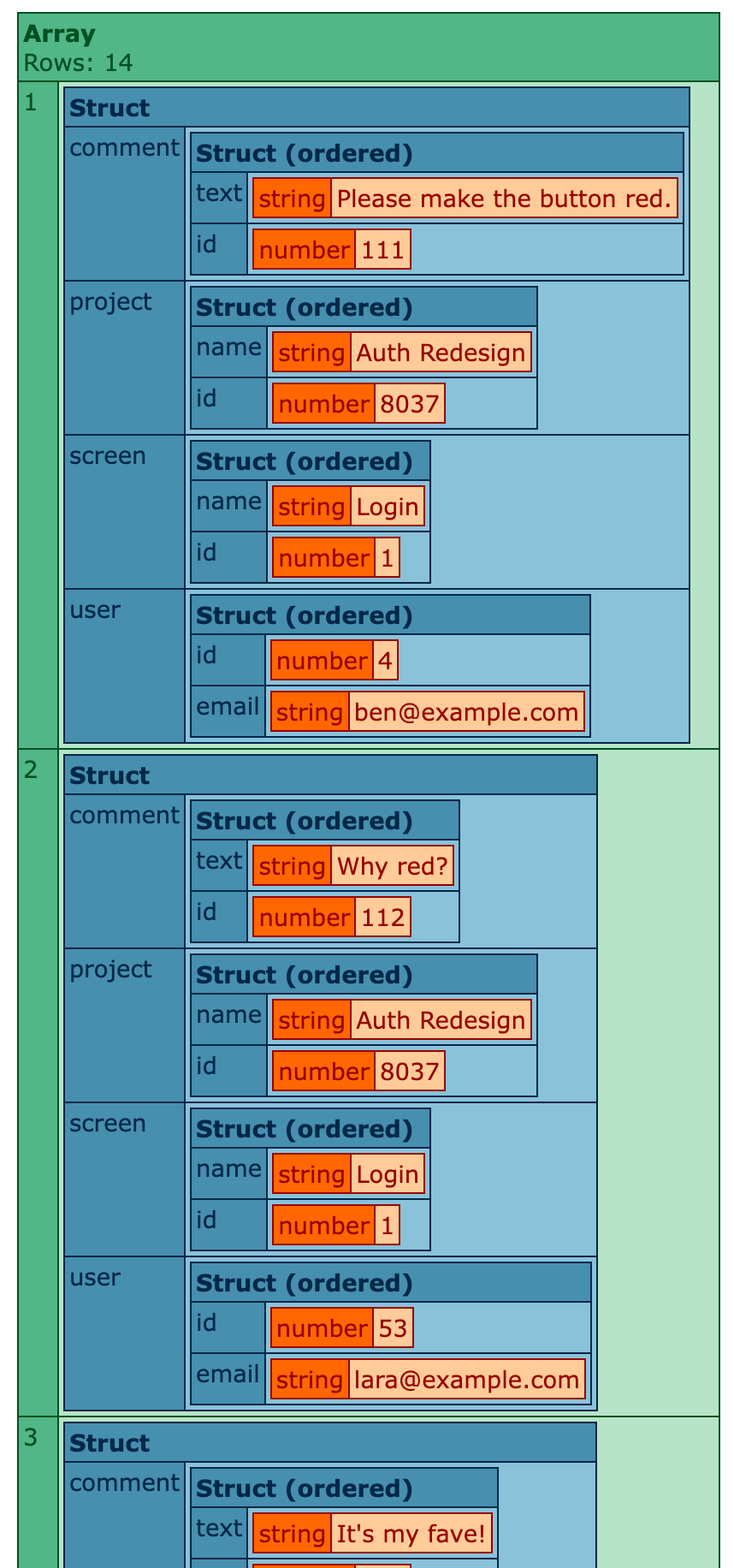
You can even reduce an aggregate down to a set of simple values. If your array[] syntax points to a simple value instead of a struct, it will pluck that column from the underlying object.
<cfscript>
// Defines our query object as the "records" variable.
include "./sample-data.cfm";
data = new QueryNormalizer().normalizeQuery( records,
{
"project[]": {
"id": "",
"name": "",
// Unique set of Screen IDs in this project.
"screenIDs[screen]": "id",
// Unique set of User Emails that have commented on this project.
"userEmails[user]": "email"
}
}
);
writeDump( data );
</cfscript>
Here, we're grouping by project (there's only one in the demo data). Then, for each project, we're plucking the unique set of screen IDs and user emails. Now, if we run this ColdFusion code, we get the following output:
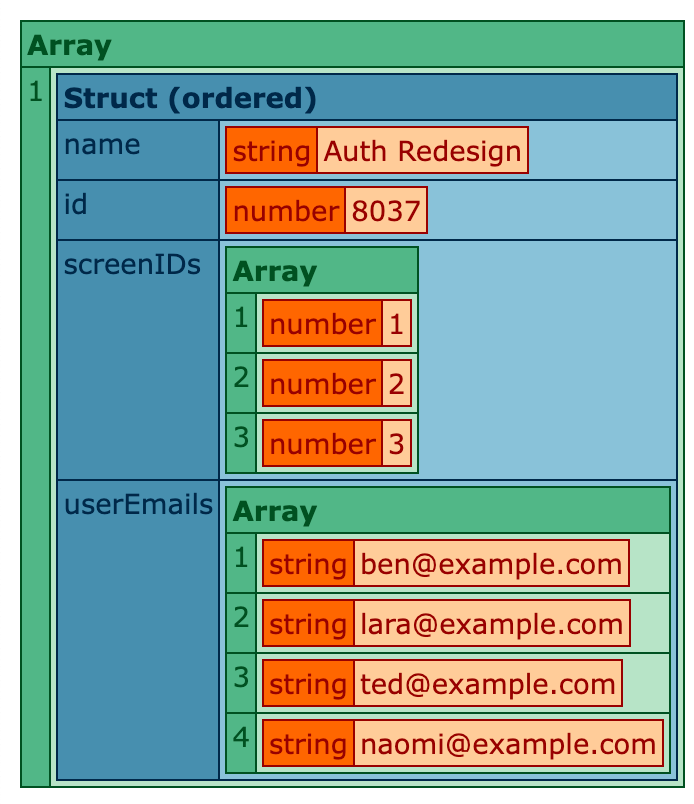
I think this is pretty cool!
I'm running late for work, so I'll just end by sharing the code for the QueryNormalizer.cfc:
component {
/**
* I initialize the service.
*/
public void function init( string fallbackFacet = "id" ) {
// If no explicit facet is provided in the configuration for grouping, this is the
// property to be used. This pertains the to he "widgets[widget:FACET]" syntax.
variables.fallbackFacet = arguments.fallbackFacet;
}
// ---
// PUBLIC METHODS.
// ---
/**
* I pluck the given key from the objects in the collection.
*/
public array function arrayPluck(
required array collection,
required string key,
string valueFallback = ""
) {
return collection.map(
( element ) => {
return ( element[ key ] ?: valueFallback );
}
);
}
/**
* I normalize / destructure the given query data (assuming returnType="array").
*/
public array function normalizeArray(
required array records,
required struct config
) {
var internalConfig = parseConfigRecursively( newNode( "root" ), config );
// If the root contains a hasGroup configuration, then it will be the only root
// configuration that we translate. You can't mix one/many relationships at the
// root since it's unclear what the resultant data-structure SHOULD look like.
if ( internalConfig.hasGroup.len() ) {
if ( internalConfig.hasGroup.len() > 1 ) {
throw(
type = "BadConfig",
message = "The root configuration may only contain a single grouping.",
detail = "Move secondary groups into a property of the first group."
);
}
if ( internalConfig.hasObject.len() ) {
throw(
type = "BadConfig",
message = "The root configuration may not mix groups and objects together.",
detail = "Move objects into a property of the root group."
);
}
return collectGroups( internalConfig.hasGroup.first(), records );
}
// If the root only contains hasObject configurations, they can all be applied to
// the same record. This allows a single row to be destructured into several
// objects.
return records.map(
( record ) => {
var row = {};
for ( var childConfig in internalConfig.hasObject ) {
row[ childConfig.identifier ] = collectObject( childConfig, record );
}
return row;
}
);
}
/**
* I normalize / destructure the given query (assuming returnType="query").
*/
public array function normalizeQuery(
required query records,
required struct config
) {
return normalizeArray( queryToArray( records ), config );
}
/**
* I return the query as an array of structs.
*/
public array function queryToArray( required query records ) {
var elements = [];
for ( var element in records ) {
elements.append( element );
}
return elements;
}
// ---
// PRIVATE METHODS.
// ---
/**
* I collect the unique grouping of (non-contiguous) elements within the given records,
* grouped by unique facet.
*/
private array function collectGroups(
required struct config,
required array records
) {
var groups = [];
var groupsIndex = {};
var group = [ "#config.facet#": createUuid() ];
var temp = [:];
for ( var record in records ) {
for ( var entry in config.properties ) {
temp[ entry.identifier ] = record[ entry.columnName ];
}
var facetValue = temp[ config.facet ];
// Did we enter a new grouping of rows (unique facet value).
// --
// Note: since the grouping of rows is calculated before we enter into any
// recursion, it allows us to group non-contiguous rows into the same group as
// long a they have the same facet. This was a judgement call (to allow non-
// contiguous groupings); and I believe will better align with the needs of
// the developer.
if ( ! groupsIndex.keyExists( facetValue ) ) {
group = groupsIndex[ facetValue ] = duplicate( temp );
group.__records = [];
groups.append( group );
}
// Track the records associated with each grouping so that we can evaluate
// the sub-records recursively below.
groupsIndex[ facetValue ].__records.append( record );
}
// Now that we've collected our unique groups, we can recursively collect the data
// for each group.
for ( var group in groups ) {
for ( var childConfig in config.hasGroup ) {
group[ childConfig.identifier ] = collectGroups( childConfig, group.__records );
// If a plucking property is defined, flatten the group.
if ( childConfig.pluck.len() ) {
group[ childConfig.identifier ] = arrayPluck(
group[ childConfig.identifier ],
childConfig.pluck
);
}
}
// Single objects will only be extracted from the first record within each
// grouping of records.
for ( var childConfig in config.hasObject ) {
group[ childConfig.identifier ] = collectObject( childConfig, group.__records[ 1 ] );
}
group.delete( "__records" );
}
return groups;
}
/**
* I collect the single object within the given record.
*/
private struct function collectObject(
required struct config,
required struct record
) {
var element = [:];
for ( var entry in config.properties ) {
element[ entry.identifier ] = record[ entry.columnName ];
}
// Note: objects can contain other objects from the same record; but, they cannot
// contain groups, since the grouping would only have access to the single record.
for ( var childConfig in config.hasObject ) {
element[ childConfig.identifier ] = collectObject( childConfig, record );
}
return element;
}
/**
* I create a new node for the internal configuration definition.
*/
private struct function newNode(
required string identifier,
string prefix = "" ,
string facet = "",
string pluck = ""
) {
return [
identifier: identifier,
prefix: prefix,
facet: facet,
pluck: pluck,
properties: [],
hasObject: [],
hasGroup: []
];
}
/**
* I parse the config key into a common structure (which is also be used to init the
* internal configuration nodes).
*/
private struct function parseConfigKey( required string key ) {
if ( key.find( "[" ) ) {
// Ensure that an identifier is in the key or listToArray() will fail.
if ( key.left( 1 ) == "[" ) {
key = "_#key#";
}
var parts = key.listToArray( " [:]" );
return {
type: "array",
identifier: parts[ 1 ],
prefix: ( parts[ 2 ] ?: parts[ 1 ] ),
facet: ( parts[ 3 ] ?: fallbackFacet ),
pluck: ""
};
} else if ( key.find( "{" ) ) {
// Ensure that an identifier is in the key or listToArray() will fail.
if ( key.left( 1 ) == "{" ) {
key = "_#key#";
}
var parts = key.listToArray( " {:}" );
return {
type: "struct",
identifier: parts[ 1 ],
prefix: ( parts[ 2 ] ?: parts[ 1 ] ),
facet: ( parts[ 3 ] ?: fallbackFacet ),
pluck: ""
};
}
return {
type: "",
identifier: key,
prefix: key,
facet: fallbackFacet,
pluck: ""
};
}
/**
* I walk the configuration object, translating the dev-friendly version into a version
* that will be used internally for the record collation.
*/
private struct function parseConfigRecursively(
required struct node,
required struct nodeConfig,
string nodePrefix = ""
) {
for ( var key in nodeConfig ) {
var metadata = parseConfigKey( key );
var value = nodeConfig[ key ];
if ( metadata.type == "array" ) {
var childNode = newNode( argumentCollection = metadata );
// If the value is simple, we're going to be plucking a single property
// into the array (rather than an array of objects).
if ( isSimpleValue( value ) ) {
childNode.pluck = value;
value = { "#value#": "" };
// We need to ensure that the facet is in the child config, otherwise,
// the group collection may fail if a key other than the facet is the
// one being collected.
value[ "#metadata.facet#" ] = "";
}
node.hasGroup.append( parseConfigRecursively( childNode, value, metadata.prefix ) );
} else if (
( metadata.type == "struct" ) ||
isStruct( value )
) {
var childNode = newNode( argumentCollection = metadata );
node.hasObject.append( parseConfigRecursively( childNode, value, metadata.prefix ) );
} else if ( len( value ) ) {
node.properties.append({
identifier: metadata.identifier,
columnName: value
});
} else {
node.properties.append({
identifier: metadata.identifier,
columnName: "#nodePrefix##metadata.identifier#"
});
}
}
return node;
}
}
This is just a proof of concept (POC); but, I might try to flesh this out into something more robust.
Want to use code from this post? Check out the license.

Reader Comments
Thank you for your fast response tackling my request. As usual, you knocked it out of the park. I appreciate it!
@Robin,
Always a pleasure - I appreciate letting me go down a rabbit hole on this one 😆 And, for the readers' benefit, I just wanted to mention that you had come up with a MSSQL Server
STRING_AGG()solution on your end. Which, I think is the equivalent ofGROUP_CONCAT()in the MySQL world.I love how Ben gets more done getting ready for work than most of us get done in a full day.
@Peter,
Ha ha, it's all connected. The whole
.normalizeQuery()concept (the bulk of this post) was directly inspired by the fact that CFWheels ORM can bring back nested objects from the database. I still haven't really dove into the SQL-generation level under the hood - but, I have to image Wheels is doing something akin to this to map SQL column aliases back onto nested object properties.So, it's all a mutually beneficial cycle. 🙌
For the first sollution why not use a query
<cfloop>with the same grouping applied? I took your first example and replaced the cfoutput in the grouping outputs with cfloops. I just had to drop the encodFor attribute and it worked while within outer cfoutput tags. (I'm using CF2023).@Brendan,
Ummmm, because I completely forgot that the
groupattribute works on thecflooptag 🤪 Just did a little Google search and apparently I wrote about it back in 2012:www.bennadel.com/blog/2359-coldfusion-10-using-the-group-attribute-with-cfloop-to-group-query-rows.htm
Ha! So, somewhere over the last 13 years, I totally forgot that this was even an option!
Post A Comment — ❤️ I'd Love To Hear From You! ❤️
Post a Comment →