
Experimenting With Low-Level SQLite Access In Lucee CFML
In my first look at accessing SQLite databases in ColdFusion, I was using a Lucee CFML specific feature that allows for creating on-the-fly datasources in the CFQuery tag. As a follow-up experiment, I wanted to see if I could use lower-level Java methods—in the java.sql package—in order to access SQLite without having to rely on Lucee-only features.
View this code in my ColdFusion-SQLite project on GitHub.
Caution: I really have no idea what I'm doing here. This exploration is only for my own curiosity. I've never even seen the
java.sqlpackage before until I came across the article, Getting Started withjava.sqlby Ethan McCue. That article, plus some help from ChatGPT, is how I came up with the code in this exploration.If nothing else, this exploration has given me a lot of insight into just how much functionality is being provided by the ColdFusion runtime; and, the way in which it manages database connections. So many details to consider! So many data-types to convert.
When it comes to querying a database, there's literally nothing better than the CFQuery and CFQueryParam tags. The ergonomics are unmatched; and the security against SQL injection attacks is also the path of least resistance. And, in fact, I was using these tags in my earlier exploration of SQLite.
In this exploration, I'm bypassing these fundamental ColdFusion tags and I'm using lower-level Java methods. But, that doesn't mean that we have to completely forsake the advantages of a tag-based interface. We can still provide a similar developer experience (DX) by creating ColdFusion custom tags that look and feel like the built-in tags.
To that end, I'm going to create two ColdFusion custom tags, query.cfm and queryparam.cfm, that work together to collect parameterized values and then execute a prepared statements against a given SQLite database file.
Using custom tags in this context is actually quite helpful because prepared SQL statements use positional parameters. Which means, the physical layout of our custom tags directly matches the order of the parameters as they need to be applied to the underlying prepared statement.
Consider this snippet of ColdFusion code which uses my custom tags (imported with the tag prefix, lite:):
<lite:query name="results" database="my.db">
INSERT INTO tokens
(
id,
value
) VALUES (
<lite:queryparam value="1234" sqltype="integer" />,
<lite:queryparam value="wooty" sqltype="varchar" />
);
</lite:query>
When the SQL statement in the above snippet is prepared for execution, it needs to be converted to this parameterized format:
INSERT INTO tokens
(
id,
value
) VALUES (
?,
?
);
Notice that the two queryparam.cfm tags in the SQL code have been converted to (?) placeholders. These (?) markers represent the parameterized values that we have to provide to the SQL statement before we execute it. And, when we provide these values, we do so using a 1-based indexing scheme and type-specific setters:
statement.setInt( 1, 1234 )statement.setString( 2, "wooty" )
In order to wire this up, our queryparam.cfm tag has to do next-to-nothing. Since the ColdFusion custom tags are executed in a top-down manner, all that our custom tag has to do is:
Replace its own output with a parameter placeholder,
?.Append its own
valueattribute to a top-levelqueryParametersarray which will be provided by the parent custom tag,query.cfm.
If we do this, then the top-level queryParameters array will match the order of the (?) markers in the prepared statement.
Here's my code for the queryparam.cfm ColdFusion custom tag. Note that this tag supports very few of the native CFQueryParam attributes—just enough to get this demo working.
<cfscript>
param name="attributes.value" type="any";
param name="attributes.sqltype" type="string";
getBaseTagData( "cf_query" )
.queryParams
.append({
value: attributes.value,
type: attributes.sqltype.lcase().reReplace( "^cf_sql_", "" )
})
;
// Insert positional parameter notation into SQL.
echo( "?" );
// There is no body or end mode functionality. Exit tag entirely.
exit;
</cfscript>
As you can see, this ColdFusion tag does nothing other than pass the value and type up to the parent custom tag and write (?) to the output. There's no validation here, no Java type conversions—all of the heavy lifting of the SQL statement creation, preparation, and execution is deferred to the query.cfm tag.
As a reminder, I really don't know what the heck I'm doing here. This is the first time that I've ever played around with these Java libraries. And, it seems that there is much complexity in the details. Not only do we have to contend with type-casting between the Java layer and the ColdFusion / CFML layer (moving data in either direction), we also have to worry about opening and closing connections.
And, I'm not even worrying about connection pooling and where one might cache persistent objects. As such, every time this query.cfm custom tag operates, I'm obtaining a new connection to the given SQLite database file. This is inefficient; and, it means that I can't use in-memory SQLite databases.
But, this is just a fun exploration! And, to that end, I'm not going to try and explain too much here since I don't know that much about it. I've tried to put a lot of comments in the code—but, I'm really just hacking this stuff together. Most of the pathways through this code haven't even been tested by code execution.
<cfscript>
if ( thistag.executionMode == "start" ) {
param name="attributes.name" type="string" default="";
param name="attributes.database" type="string";
param name="attributes.returnType" type="string" default="query";
queryParams = [];
// Exit tag and allow the body of the tag to execute (and the queryParam child
// tags to accumulate).
exit
method = "exitTemplate"
;
}
// ASSERT: At this point, we've collected all of the query parameters and the SQL
// statement (into the generatedContent) and we're ready to execute the SQL statement
// against the datasource.
// The body of the ColdFusion custom tag contains the SQL. Get a reference to it and
// then reset the output so that we don't bleed the SQL into the page rendering.
sql = thistag.generatedContent;
thistag.generatedContent = "";
// ------------------------------------------------------------------------------- //
// ------------------------------------------------------------------------------- //
sqlTypes = createObject( "java", "java.sql.Types" );
// Define a Java datasource that points to the given SQLite file.
datasource = createObject( "java", "org.sqlite.SQLiteDataSource" ).init();
// NOTE: In order to use the in-memory database (`:memory:`) or any variation therein,
// we'd have to create a connection pool that maintains a connection. Otherwise, the
// in-memory database is dropped after ever SQL connection is closed.
datasource.setUrl( "jdbc:sqlite:#attributes.database#" );
try {
// EXPERIMENTAL CONTEXT: In this version, we're creating a NEW CONNECTION to the
// database every time the query is executed. This is sub-optimal. In a production
// scenario, we'd want to create a CONNECTION POOL. But, that's more advanced than
// I can do at this time.
connection = datasource.getConnection();
// Prepare the SQL statement with positional parameters. This allows us to use
// dynamic, user-provided values while still preventing SQL injection attacks.
statement = connection.prepareStatement( sql );
applyQueryParams( statement, queryParams );
// Execute the SQL statement against the database.
// --
// NOTE: Not all SQL queries return a ResultSet (ex. UPDATE and CREATE TABLE). As
// such, we're using the .execute() method here followed, conditionally, by the
// .getResultSet() method below.
statement.execute();
// If the NAME has been provided, we're going to assume the user knows what
// they're doing, and that a ResultSet is expected (this is a poor assumption, but
// is fine for the demo - the .getResultSet() can return NULL and we should check
// for that in a more robust scenario).
if ( attributes.name.len() ) {
results = ( attributes.returnType == "query" )
? convertResultSetToQuery( statement.getResultSet() )
: convertResultSetToArray( statement.getResultSet() )
;
setVariable( "caller.#attributes.name#", results );
}
} finally {
results?.close();
statement?.close();
connection?.close();
}
// ------------------------------------------------------------------------------- //
// ------------------------------------------------------------------------------- //
/**
* I apply the query params as positional parameters to the given prepared statement.
*/
private void function applyQueryParams(
required any statement,
required array queryParams
) {
// I'm not exactly sure how every data-type maps to the proper method call. This
// is below the surface that I usually operate on. ChatGPT helped me figure some
// of this stuff out.
// --
// See: https://docs.oracle.com/en/java/javase/11/docs/api/java.sql/java/sql/PreparedStatement.html
loop array="#queryParams#" index="local.i" value="local.queryParam" {
switch ( queryParam.type ) {
case "bit":
case "boolean":
statement.setBoolean( i, javaCast( "boolean", queryParam.value ) );
break;
case "integer":
statement.setInt( i, javaCast( "int", queryParam.value ) );
break;
case "bigint":
statement.setLong( i, javaCast( "long", queryParam.value ) );
break;
case "decimal":
case "numeric":
statement.setLong( i, javaCast( "bigdecimal", queryParam.value ) );
break;
case "double":
statement.setDouble( i, javaCast( "double", queryParam.value ) );
break;
case "float":
case "real":
statement.setFloat( i, javaCast( "float", queryParam.value ) );
break;
case "smallint":
statement.setShort( i, javaCast( "short", queryParam.value ) );
break;
case "tinyint":
statement.setByte( i, javaCast( "byte", queryParam.value ) );
break;
case "date":
case "timestamp":
statement.setDate( i, dateAdd( "d", 0, queryParam.value ) );
break;
// case "time":
// break;
case "char":
case "varchar":
case "longvarchar":
statement.setString( i, javaCast( "string", queryParam.value ) );
break;
// case "clob":
// break;
case "binary":
case "varbinary":
case "longvarbinary":
statement.setBytes( i, queryParam.value );
break;
case "blob":
statement.setBlob( i, queryParam.value );
break;
default:
statement.setObject( i, queryParam.value );
break;
}
}
}
/**
* I convert the given SQL ResultSet into a ColdFusion array (of structs).
*/
private array function convertResultSetToArray( required any resultSet ) {
var metadata = resultSet.getMetadata();
var columnCount = metadata.getColumnCount();
var rows = [];
while ( resultSet.next() ) {
var row = [:];
for ( var i = 1 ; i <= columnCount ; i++ ) {
// TODO: Is calling .getObject() sufficient for data-typing? When I dump-
// out the results, they look properly cast. But, I'm not sure if that's
// just something Lucee CFML is doing in the CFDump tag rendering. Also,
// SQLite will store any data in any column; so, I am not sure if it's
// even safe to assume that I can cast a column value consistently.
row[ metadata.getColumnName( i ) ] = resultSet.getObject( i );
}
rows.append( row );
}
return rows;
}
/**
* I convert the given SQL ResultSet into a ColdFusion query.
*/
private query function convertResultSetToQuery( required any resultSet ) {
var metadata = resultSet.getMetadata();
var columnCount = metadata.getColumnCount();
var columnNames = [];
var columnTypes = [];
// Prepare the metadata for the ColdFusion query generation.
for ( var i = 1 ; i <= columnCount ; i++ ) {
columnNames.append( metadata.getColumnName( i ) );
columnTypes.append( getQueryColumnType( metadata.getColumnType( i ) ) );
}
return queryNew(
columnNames.toList(),
columnTypes.toList(),
convertResultSetToArray( resultSet )
);
}
/**
* I get the ColdFusion query column type from the given SQL type. This is used to
* manually create ColdFusion queries with better column metadata.
*/
private string function getQueryColumnType( required numeric typeID ) {
switch ( typeID ) {
// Integer - 32-bit integer.
case sqlTypes.INTEGER:
case sqlTypes.SMALLINT:
case sqlTypes.TINYINT:
return "integer";
break;
// BigInt - 64-bit integer.
case sqlTypes.BIGINT:
return "bigint";
break;
// Double - 64-bit decimal number.
case sqlTypes.DECIMAL:
case sqlTypes.DOUBLE:
case sqlTypes.FLOAT:
case sqlTypes.NUMERIC:
case sqlTypes.REAL:
return "double";
break;
// Decimal - Variable length decimal, as specified by java.math.BigDecimal.
// VarChar - String.
case sqlTypes.CHAR:
case sqlTypes.CLOB:
case sqlTypes.LONGNVARCHAR:
case sqlTypes.LONGVARCHAR:
case sqlTypes.NCHAR:
case sqlTypes.NCLOB:
case sqlTypes.NVARCHAR:
case sqlTypes.VARCHAR:
return "varchar";
break;
// Binary - Byte array.
// Bit - Boolean (1=True, 0=False).
case sqlTypes.BIT:
case sqlTypes.BOOLEAN:
return "bit";
break;
// Time - Time.
case sqlTypes.TIME:
case sqlTypes.TIME_WITH_TIMEZONE:
return "time";
break;
// Date - Date.
case sqlTypes.DATE:
return "date";
break;
// Timestamp - Time and date information.
case sqlTypes.TIMESTAMP:
case sqlTypes.TIMESTAMP_WITH_TIMEZONE:
return "timestamp";
break;
case sqlTypes.ARRAY:
case sqlTypes.BINARY:
case sqlTypes.BLOB:
case sqlTypes.DATALINK:
case sqlTypes.DISTINCT:
case sqlTypes.JAVA_OBJECT:
case sqlTypes.LONGVARBINARY:
case sqlTypes.NULL:
case sqlTypes.OTHER:
case sqlTypes.REF:
case sqlTypes.REF_CURSOR:
case sqlTypes.ROWID:
case sqlTypes.SQLXML:
case sqlTypes.STRUCT:
case sqlTypes.VARBINARY:
// Object - Java Object. This is the default column type.
default:
return "object";
break;
}
}
</cfscript>
The bulk of this query.cfm custom tag deals with data-type conversions. And, making sure that the proper Java method is called for the given parameter type; or, that the property ColdFusion query column type is provided to the queryNew() function. Very little of the code is actually involved with instantiating Java objects and executing the SQL.
And now that we have these ColdFusion custom tags, we can start to run some SQL queries against a SQLite database file, test.db. In the following code, I'm going to create a tokens table, insert some tokens, and then query for those tokens twice: once using a Query object as the return value and once using an Array object as the return value.
Note that each <lite:query> instance provides the fully qualified file path as the database attribute:
<cfimport prefix="lite" taglib="./tags/" />
<cfset database = expandPath( "./test.db" ) />
<lite:query database="#database#">
CREATE TABLE IF NOT EXISTS `tokens` (
`id` INTEGER NOT NULL,
`value` TEXT NOT NULL
);
</lite:query>
<lite:query database="#database#">
DELETE FROM
tokens
;
</lite:query>
<lite:query database="#database#">
INSERT INTO tokens
(
id,
value
) VALUES (
<lite:queryparam value="1" sqltype="integer" />,
<lite:queryparam value="token-#createUniqueId()#" sqltype="varchar" />
),(
<lite:queryparam value="2" sqltype="integer" />,
<lite:queryparam value="bleep" sqltype="varchar" />
),(
<lite:queryparam value="3" sqltype="integer" />,
<lite:queryparam value="moop" sqltype="varchar" />
),(
<lite:queryparam value="4" sqltype="integer" />,
<lite:queryparam value="kablamo" sqltype="varchar" />
);
</lite:query>
<lite:query database="#database#">
DELETE FROM
tokens
WHERE
id = <lite:queryparam value="2" sqltype="integer" />
;
</lite:query>
<!--- Get all tokens as a QUERY (default behavior). --->
<lite:query name="queryResults" database="#database#">
SELECT
*
FROM
tokens
;
</lite:query>
<!--- Get all tokens as an ARRAY. --->
<lite:query name="arrayResults" returnType="array" database="#database#">
SELECT
*
FROM
tokens
;
</lite:query>
<div style="display: flex ; gap: 20px ;">
<cfdump
label="ResultSet as Query"
var="#queryResults#"
/>
<cfdump
label="ResultSet as Array"
var="#arrayResults#"
/>
</div>
When we run this Lucee CFML code, we get the following output with the Query results and the Array results side-by-side:
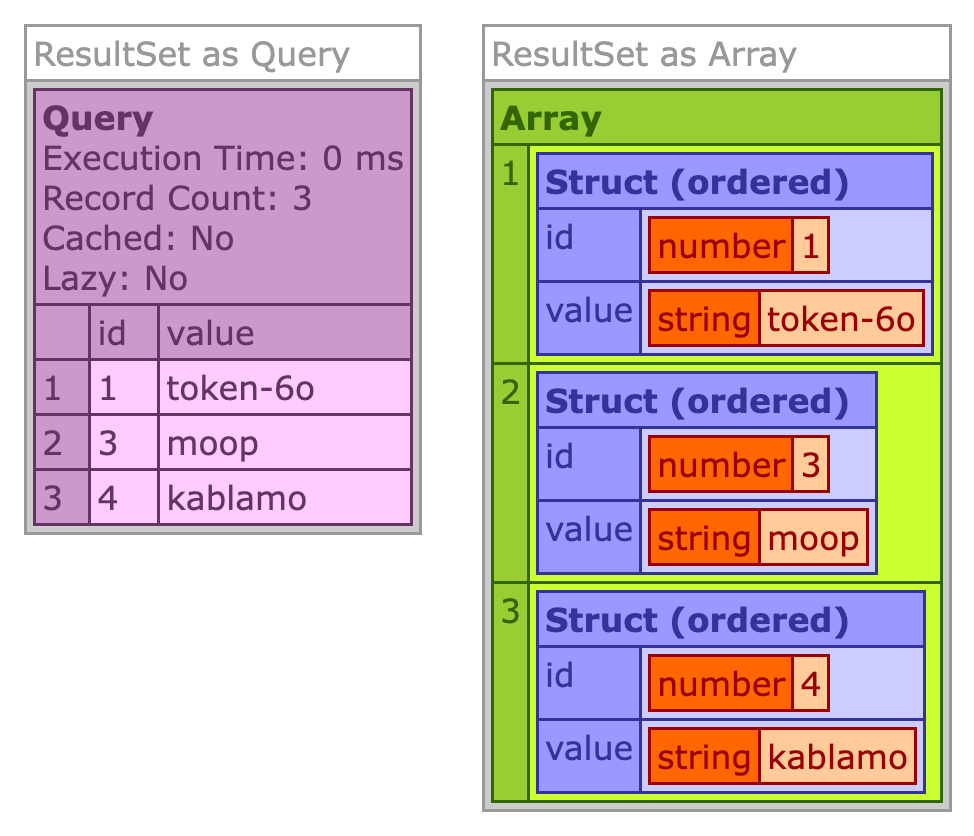
Woot! It worked. Despite the inefficiencies of creating a new database connection on every single execution, we were able to successfully execute queries against the underlying SQLite database.
Again, this was just a fun exploration—this is decidedly not production ready code.
Want to use code from this post? Check out the license.

Reader Comments
Would definitely be interested in future sqlite related posts. Just started looking at it yesterday (though I saw this post a few days ago), because I was looking for an old email list. Turns out the file it was stored in was a sqlite db by the software vendor.
Of course I have MSSQL and MySQL available, but I do a lot of "scratch" projects where all I can think is "ugh... creating a database...". I've gone so far as to avoid the db by just reading and writing json to a file, definitely situations where there will be a low user count.
@Will,
Yeah, it's some cool stuff. I was actually just watching an interview with DHH on SQLite:
https://www.youtube.com/watch?v=0rlATWBNvMw
Apparently their stand-alone chat app (CampFire) runs on SQLite as well. And, he talks about it from the same perspective - "ugh, creating a database!" - keeping it simple, and fast, especially in these single-tenant / experimental kinds of contexts.
@Ben Nadel,
Will definitely watch that. Interestingly, though, I wasn't able to get it working at all with Commandbox / Lucee. Maybe if I had copied the jar into the [site]/lucee/lib manually, but .... just didn't want to do that, esp. for my "scratch" site as I often flip ACF/Lucee back and forth. (MY stuff is all Lucee, but work stuff is ACF, so... testing things often means being on ACF.)
I was thinking about the use case for SqlLite in my cfml apps currently in the future. I've watched the DHH SqlLite interview and like all his content, it's wonderful and informative, and most importantly practical!
I do wish sqlLite was a default engine inside Lucce because as DHh indicates it can scale up from the smallest project to the most common use cases we make business apps for.
My most common use case that I need data storage for is in proof of concept apps, and small apps that will never grow that just do utility functions. That's where this comment comes in:
@ben and others, let's not forget about query of queries QoQ, which we already have in cfml.
My general thought would be just create a bunch of in memory, queries, or other acceptable, data format, and persistent disk. Then use queries of queries to do light data aggregation or joining that's required for the business case.
I don't do it this way currently but it's a way to get started and prove out the concept of the app and most importantly ship it off my machine onto the server. (currently using DigitalOcean app platform, and some docker BTW for Gagging off my machine and into the real world)
@Peter, you make a good point, in fact, a lot of the Coldbox materials do "mocking" (via the Mockbox system and the querySim() function) that is just what you need for PoC things. Pretty sure, too, you're supposed to be able to use Mockbox even if you don't have a Coldbox app.
Note: Line breaks matter.
I'm also a huge fan of using either JSON files or ND-JSON files for storing data. ND-JSON is for "newline delimited" JSON where a separate JSON payload is stored on each line (as opposed to one massive JSON file, it's lots of little files concatenated). It works great when you want to read one-line at a time and process it.
Of course, once you have arrays-of-structs, you're in the realm of
.filter()and.map()instead forWHEREandSELECT.From the DHH interview, one thing that gave me pause was when they were eluding to the idea that SQLite had some funky defaults when it comes to multi-user access. But, they didn't say what that actually meant? And, nothing obviously pops to mind; because, as long as the user can't directly access the
.dbfile, all access is driven by the app; so, what could possibly go wrong from a DB-permissions standpoint? I was left scratching my head.Hey @BenNadel did you have any problems with NullPointerException's during your testing?
Doing a new (tiny) project, though "Hey, sqlite would be perfect!" Got all my data loaded via [some sql ui]. Started up my site in Commandbox, but I'll be $%$( if I can get the thing to work.
Gonna reach out to Ortus, too, because I'm not seeing the .jar getting copied over, but.... pretty sure it's available. I can createObject("java", "org.sqlite.JDBC") and dump it. (I was getting "can't load class name" or whatever, but that's gone away.)
@Will,
I don't remember getting any NPE errors when playing around with this stuff. Re: not seeing the JAR getting copied, but being able to dump-out an instance, I've heard on podcasts the SQL lite engine ships by default with a lot of operating systems. So, I'm wondering if you are accidentally using something that happens to be available; but, you're not using the JAR file you intend to use.... but, I'm not sure that's how containers actually work 🤔 Yeah, seems fishy. Maybe trying running deleting the docker image and re-building it?
Post A Comment — ❤️ I'd Love To Hear From You! ❤️
Post a Comment →