
Paginating The Postmark Bounces API In ColdFusion
As I discussed in January, I've been sending out millions of emails in ColdFusion. I've never done anything at this scale before; and, I've been learning a lot of fun lessons along the way. With email delivery, the bounce rate is king. And, I've been doing whatever I can to keep our bounce rate low so that Postmark doesn't shut down our pipes. One valuable step in this regard was using the Postmark Bounces API to locate problematic email addresses from previous mailings so that I can remove them from the current mailing.
An outbound email can bounce for many reasons. Some of those reasons are permanent; and, for permanent / hard bounces, Postmark will automatically add the given email address to its "Suppression" list (and will skip any subsequent send to said email address). Other bounces are temporary / soft; and, in theory, sending another email to the given address may work in the future. As such, Postmark doesn't perform any automatic handling of soft bounces.
That said, soft bounces still count towards your bounce rate. Which means, soft bounces are still very much a "bad thing". And, having too many soft bounces can lead to your account getting suspended.
To err on the side of safety, I've been querying the Postmark API for these soft bounces; and, then, adding those email addresses to an internal block-list so that they get skipped-over on subsequent sends.
The Postmark Bounces API is both paginated and governed. You can only get 500 bounces in any individual API request. And, you can only read up to 10,000 bounces in a given From/To time-period. Which means, in order to gather up all the relevant bounces (at our scale), I need to implement a nested pagination workflow. That is, I need to incrementally step over both the entire window of a mass mailing and, for each segment within that window, incrementally step over the 500-result limit.
This results in a workflow that makes a lot of Postmark API calls. Any one of these API calls can break for a number of reasons; such as a network timeout or a server error. In order to create a resilient workflow, I need to persist the intermediary results such that if the workflow does break, I can pick up where I left off instead of having start over from the beginning.
Since this kind of work is a one-off effort, I'm running it from my local development environment. And, to keep things simple, I'm just writing all the data to my local file system. As I perform this nested pagination in ColdFusion, I'm writing "part files" to disk. Each part file contains a subset of the bounces. Then, once the pagination is complete, I coalesce all part files into a final result and clean-up / delete the intermediary files.
The basic algorithm is a follows:
Define the FROM / TO dates for the target time-frame.
Iterate over the FROM / TO dates, 1-hour at a time.
For each 1-hour segment, check to see if a "part file" already exists on disk. If so, continue on to the next 1-hour window (picking up where we left off in the case of a crash).
If the part file doesn't exist, iterate over the current segment, 500-bounces at a time (that maximum number of results in any given API call).
For each bounce, inspect the
.Detailsproperty to see if it's relevant to the current query.Write all relevant email addresses to the current part file.
When done iterating over the FROM / TO time-frame, combine all part files into a single results file.
Delete all part files.
The Postmark Bounces API allows you to filter on the macro type of bounce (ex, SpamNotification, SoftBounce, Blocked, etc.). Within each macro type, there may be many reasons for each individual bounce that can only be discerned by looking at a given bounce's details. As such, I have to pull back more data from the API than I want; and then use regular expressions for fine-tuned filtering.
To make my workflow repeatable for different types of bounces, I start with a small configuration object. Here's an example that looks for users with full mailboxes:
config = {
type: "SoftBounce",
pattern: "(out of storage|mailbox full|mailbox is full)",
filename: "soft-bounce-mailbox-full.txt"
};
This configuration object provides the type of bounce to pull-back from the Postmark API, the regular expression pattern to be applied to the .Details response property, and the filename to be used for the final coalesced results.
None of this is cut-and-dry. Since soft bounces are temporary, deciding to use a given bounce to block a given email address is a matter of human judgement. Using the above example, it's completely possible that a user might empty their mailbox and, therefore, be able to receive a future mailing. However, as a human myself, I can safely say that "normal users" don't allow their mailboxes to become full. As such, I feel confident in excluding these outliers from the next mailing.
In our particular case, since we're sending public service announcements (PSAs), I'm erring on the side of lowering the bounce rate. That is, I'd rather block valid users accidentally instead of risking a bounce on a subsequent mailing. We're not sending out mission critical information; so, I'm more concerned with our SMTP server's delivery reputation.
With that said, here's my workflow. I'm not going to go into too much detail since it's just procedural code; but, I've tried to blanket it with comments to explain why I'm doing what I'm doing.
<cfscript>
// Move Postmark credentials to another file for demo.
include "./credentials.cfm";
config = {
type: "SoftBounce",
pattern: "(out of storage space|mailbox full|mailbox is full)",
filename: "soft-bounce-mailbox-full.txt"
};
// ------------------------------------------------------------------------------- //
// ------------------------------------------------------------------------------- //
// Allocate enough time to make a lot of API calls.
setting
requestTimeout = ( 60 * 10 )
;
// The last mass emailing job was carried-out between the following dates.
minFromDate = createDateTime( 2024, 3, 15, 0, 0, 0 );
maxToDate = createDateTime( 2024, 3, 21, 0, 0, 0 );
// The /bounces API only allows for the first 10,000 results in a given FROM/TO range
// even if we're paginating over the results. And, due to the high-volume of bad
// emails (collected over a decade-and-a-half), we hit this limit with some queries.
// As such, we're going to iterate over the FROM/TO range one HOUR at a time. This
// will be implemented by adding N-hours to the MIN FROM date.
offsetInHours = 0;
// With all DO-WHILE loops, I like to build in some sort of reasonable upper-boundary
// that will short-circuit the loop if something goes wrong in my logic.
attemptsRemaining = 150;
// Gathering up all of these bounces from the Postmark API is going to require many
// API calls. And, any one of these calls might break or timeout or my server might
// crash. As such, we want to store "mile markers" of progress such that if we do need
// to restart the process, we don't have to start from scratch. To keep things simple,
// each HOUR of bounces will be considered a "unit of work". I'm going to collect
// these emails in "part files" and store them individually.
partFiles = [];
// ------------------------------------------------------------------------------- //
// ------------------------------------------------------------------------------- //
do {
// Iterate over FROM/TO range 1-HOUR at a time.
fromDate = minFromDate.add( "h", offsetInHours );
toDate = fromDate.add( "h", 1 );
// Define the "mile marker" part file.
partFile = "./parts/#config.filename#.#offsetInHours#";
partFiles.append( partFile );
// The part file is only written to disk once all the results within the current
// HOUR have been collected. As such, we know that we only need to process this
// hour when the part file hasn't been created yet.
if ( ! fileExists( partFile ) ) {
// Each page of results can only contain a maximum of 500 bounces. We'll need
// collect the emails for this "part" across (potentially) many API calls.
partEmails = [];
// The total (limit + offset) can never go higher than 10,000. If we hit this
// limit, we're just going to eat the fact that we drop some emails.
for ( apiOffset = 0 ; apiOffset <= 9500 ; apiOffset += 500 ) {
bounces = getBouncesFromPostmark(
bounceType = config.type,
fromDate = fromDate,
toDate = toDate,
offset = apiOffset
);
if ( ! bounces.len() ) {
break; // Break out of pagination loop.
}
// Since many different bounce variations are categorized under the same
// bounce type, we need to inspect the details to see if this bounce
// result is relevant to our current query.
for ( bounce in bounces ) {
if ( lcase( bounce.Details ).reFind( config.pattern ) ) {
partEmails.append( lcase( bounce.Email ) );
}
}
} // END: Pagination loop.
// Save "mile marker" part file.
fileWrite( partFile, serializeJson( partEmails ), "utf-8" );
} // END: If part file exists.
offsetInHours++;
} while ( ( toDate < maxToDate ) && ( --attemptsRemaining >= 0 ) );
// ------------------------------------------------------------------------------- //
// ------------------------------------------------------------------------------- //
// At this point, we've iterated over our FROM/TO date range one HOUR at a time, and
// stored each hour's worth of emails into a PART file. Now, it's time to coalesce all
// of the part files into a single results file. However, since the FROM/TO filters
// are INCLUSIVE on both ends, we end up with some overlapping emails within our part
// files. As such, I'm going to use a STRUCT to coalesce the values such that
// duplicate emails are automatically de-duplicated.
emailsIndex = {};
for ( partFile in partFiles ) {
for ( email in deserializeJson( fileRead( partFile, "utf-8" ) ) ) {
emailsIndex[ email ] = true;
}
}
// Get the list of emails from the STRUCT that we used for de-duplication.
emails = emailsIndex.keyArray();
emails.sort( "text" );
writeResultsFile( "./data/#config.filename#", emails );
// Now that we've coalesced all the parts into a final results file, we can clean-up
// the part files - we no longer need them.
for ( partFile in partFiles ) {
fileDelete( partFile );
}
echo( "Emails have been compiled. Rock on with your bad self!" );
// ------------------------------------------------------------------------------- //
// -- Utility Functions ---------------------------------------------------------- //
// ------------------------------------------------------------------------------- //
/**
* I get a limited set of bounce results from the Postmark API.
*/
public struct function getBouncesFromPostmark(
required string bounceType,
required date fromDate,
required date toDate,
required numeric offset,
numeric limit = 500,
numeric timeout = 10
) {
// Since our FROM/TO range will be hourly, we need to format the EST dates (which
// is what the Postmark API uses for filtering) to include the TIME portion.
var filterMask = "yyyy-mm-dd'T'HH:nn:ss";
var fromDateFilter = fromDate.dateTimeFormat( filterMask );
var toDateFilter = toDate.dateTimeFormat( filterMask );
// For my own debugging.
systemOutput( "Bounces API: #bounceType# : #fromDateFilter# : #offset#", true );
http
result = "local.httpResponse"
method = "GET"
url = "https://api.postmarkapp.com/bounces"
timeout = timeout
{
httpparam
type = "header"
name = "Accept"
value = "application/json"
;
httpparam
type = "header"
name = "X-Postmark-Server-Token"
value = credentials.serverToken
;
httpparam
type = "url"
name = "fromdate"
value = fromDateFilter
;
httpparam
type = "url"
name = "todate"
value = toDateFilter
;
httpparam
type = "url"
name = "messagestream"
value = credentials.messageStream
;
httpparam
type = "url"
name = "type"
value = bounceType
;
httpparam
type = "url"
name = "inactive"
value = "false"
;
httpparam
type = "url"
name = "count"
value = limit
;
httpparam
type = "url"
name = "offset"
value = offset
;
}
var apiResponse = deserializeJson( httpResponse.fileContent );
return ( apiResponse.Bounces ?: [] );
}
/**
* I write the emails to a formatted results file (for internal usage).
*/
public void function writeResultsFile(
required string resultsFile,
required array emails
) {
var suppressions = [ "Result,Email" ];
for ( var email in emails ) {
suppressions.append( "suppressed,#email#" );
}
fileWrite(
resultsFile,
suppressions.toList( chr( 10 ) ),
"utf-8"
);
}
</cfscript>
To get at taste of how this works, here's a GIF of the file-system and logging for a 24-hour period. Remember, in 24-hours, this workflow is iterating 1-hour at a time; and, for each hour, it's paginating the /bounces results 500-entries a time and then generating a "part file".
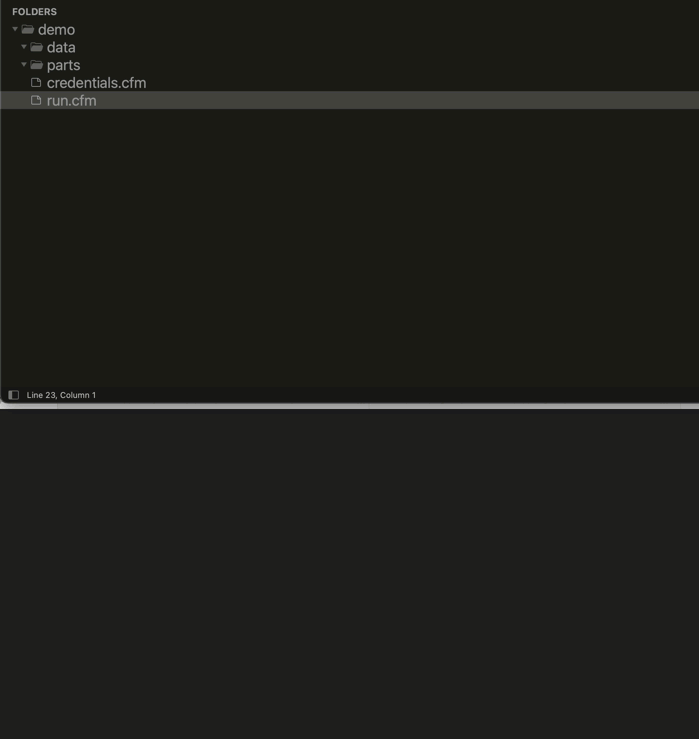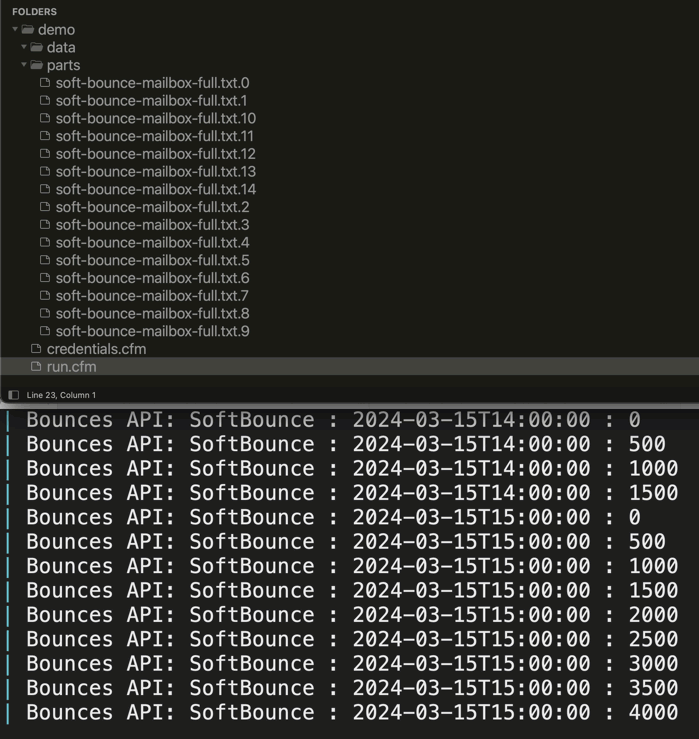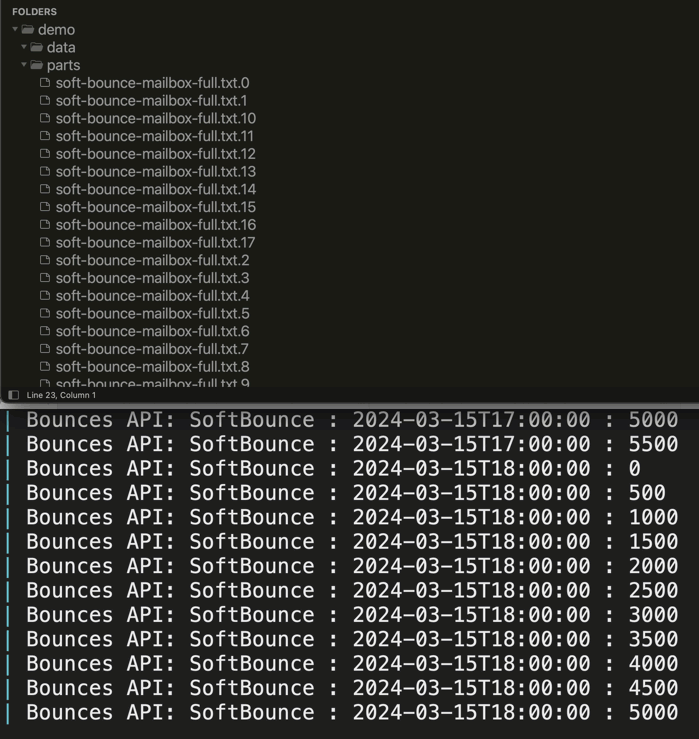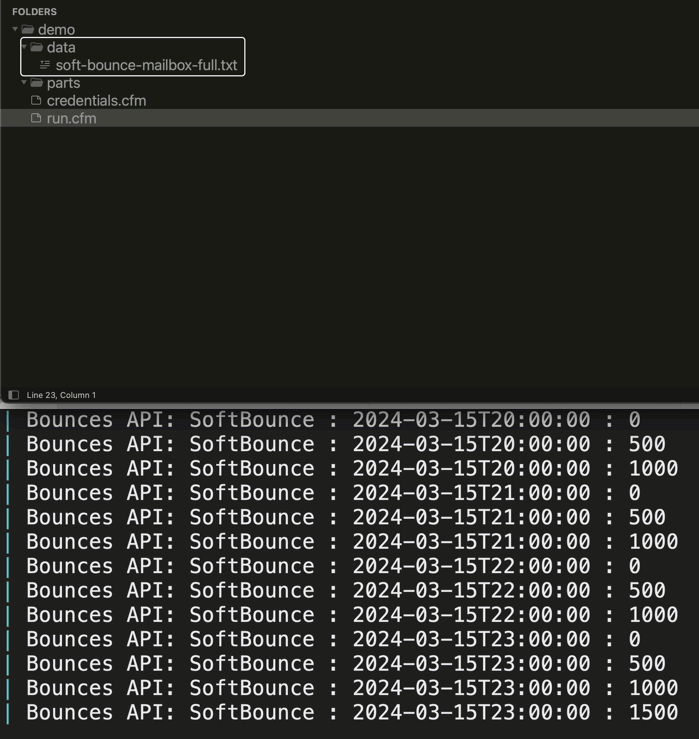
As you can see from the terminal logging, I'm iterating over the From / To time-frame 1-hour at a time. And within each hour, I'm incrementing the paginated results 500-entries at a time. And, once the whole workflow is done, the final results file is generated and all part files are deleted.
There's something intensely satisfying about using the local file system as a means to cache data. Once you start working with databases, one develops an instinct to reach for the database for all persistence needs. But, when running workflows locally, the file system is a magical cache with zero added complexity!
Postmark has a Bounces WebHook
Postmark, like many SaaS (Software as a Service) providers, can use WebHooks to alert your application about important events. Bounces are one such event. In theory, I could have used the Bounces WebHook to incrementally improve the health of our email list over time. But, unfortunately, that ship has somewhat sailed. That will have to be a lesson learned on a different day.
Want to use code from this post? Check out the license.

Reader Comments
Post A Comment — ❤️ I'd Love To Hear From You! ❤️
Post a Comment →