
CUID2 For ColdFusion / CFML
A couple of years ago, I built a ColdFusion port of the CUID library which we've been using successfully at InVision. The CUID library provides collision-resistant IDs that are optimized for horizontal scaling and performance. Just recently, however, Eric Elliott released Cuid2 - an updated version of the library intended to address some philosophical security issues. I wanted to create a ColdFusion port of his new Cuid2 library.
View this code in my CUID2 For ColdFUsion project on GitHub.
The CUID2 token is guaranteed to start with a letter and be of a consistent, configured length. The values within the token consist of the Base36 character set, which is [a-z0-9]. The ColdFusion port of CUID2 is thread safe and can be cached and reused within your ColdFusion application:
<cfscript>
// Cachced reference to the CUID instance.
cuid2 = new lib.Cuid2();
writeDump({ token: cuid2.createCuid() });
writeDump({ token: cuid2.createCuid() });
writeDump({ token: cuid2.createCuid() });
writeDump({ token: cuid2.createCuid() });
</cfscript>
Running this ColdFusion code gives us the following output:
token: uem955pnse56id49y6bcmjz8
token: ek9lgqi0mfkh9wmxnb6rvzuc
token: lycfyvl0dlspi0us6smqkkr0
token: x0hhypk7l7k4hga8newn4gnw
The Cuid2.cfc ColdFusion component can be instantiated with three optional arguments:
new Cuid2( [ length [, fingerprint [, algorithm ] ] ] )
length- The desired size of the generated tokens. This defaults to 24 but can be anything between 24 and 32 (inclusive).fingerprint- An additional source of entropy associated with the device. This will default to the name of the JVM process as provided by theManagementFactoryRuntime MX Bean.algorithm- The hash algorithm to be used when reducing the sources of entropy. It defaults tosha3-256, which is the CUID2 standard; but, can be set tosha-256on older versions of Java (8) which do not support theSHA3family of algorithms.
Under the hood, the randomness is provided by ColdFusion's built-in function, randRange(), which is being executed with the sha1prng algorithm for pseudo-random number generation. We can perform a high-level test of the randomness by generating 1,000,000 tokens and then seeing how well these values get distributed into a set of buckets:
<cfscript>
cfsetting( requestTimeout = 300 );
length = 24;
cuid = new lib.Cuid2( length );
count = 1000000;
tokens = [:];
buckets = [:];
BigIntegerClass = createObject( "java", "java.math.BigInteger" );
// Create buckets for our distribution counters. As each CUID is generated, it will be
// sorted into one of these buckets (used to increment the given counter).
for ( i = 1 ; i <= 20 ; i++ ) {
buckets[ i ] = 0;
}
bucketCount = BigIntegerClass.init( buckets.count() );
startedAt = getTickCount();
for ( i = 1 ; i <= count ; i++ ) {
token = cuid.createCuid();
// Make sure the CUID is generated at the configured length.
if ( token.len() != length ) {
throw(
type = "Cuid2.Test.InvalidTokenLength",
message = "Cuid token length did not match configuration.",
detail = "Length: [#length#], Token: [#token#]"
);
}
tokens[ token ] = i;
// If the CUIDs are all unique, then each token should represent a unique entry
// within the struct. But, if there is a collision, then a key will be written
// twice and the size of the struct will no longer match the current iteration.
if ( tokens.count() != i ) {
throw(
type = "Cuid2.Test.TokenCollision",
message = "Cuid token collision detected in test.",
detail = "Iteration: [#numberFormat( i )#]"
);
}
// Each token is in the form of ("letter" + "base36 value"). As such, we can strip
// off the leading letter and then use the remaining base36 value to generate a
// BigInteger instance.
intRepresentation = BigIntegerClass.init( token.right( -1 ), 36 );
// And, from said BigInteger instance, we can use the modulo operator to sort it
// into the relevant bucket / counter.
bucketIndex = ( intRepresentation.remainder( bucketCount ) + 1 );
buckets[ bucketIndex ]++;
}
</cfscript>
<cfoutput>
<p>
Tokens generated: #numberFormat( count )# (no collisions)<br />
Time: #numberFormat( getTickCount() - startedAt )#ms
</p>
<ol>
<cfloop item="key" collection="#buckets#">
<li>
<div class="bar" style="width: #fix( buckets[ key ] / 100 )#px ;">
#numberFormat( buckets[ key ] )#
</div>
</li>
</cfloop>
</ol>
<style type="text/css">
.bar {
background-color: ##ff007f ;
border-radius: 3px 3px 3px 3px ;
color: ##ffffff ;
margin: 2px 0px ;
padding: 2px 5px ;
}
</style>
</cfoutput>
Since the CUID2 token is, essentially, a Base36-encoded value, we can decode that value back into a byte array; and then, use that byte array to initialize a BigInteger class. And, once we have a numeric representation of the CUID2 token, we can use the modulo operator to sort it into a given bucket. Assuming we have 20 buckets, you can think of this operation like:
asBigInt( token ) % 20 => bucket
Now, when we run the above ColdFusion code, we get the following output:
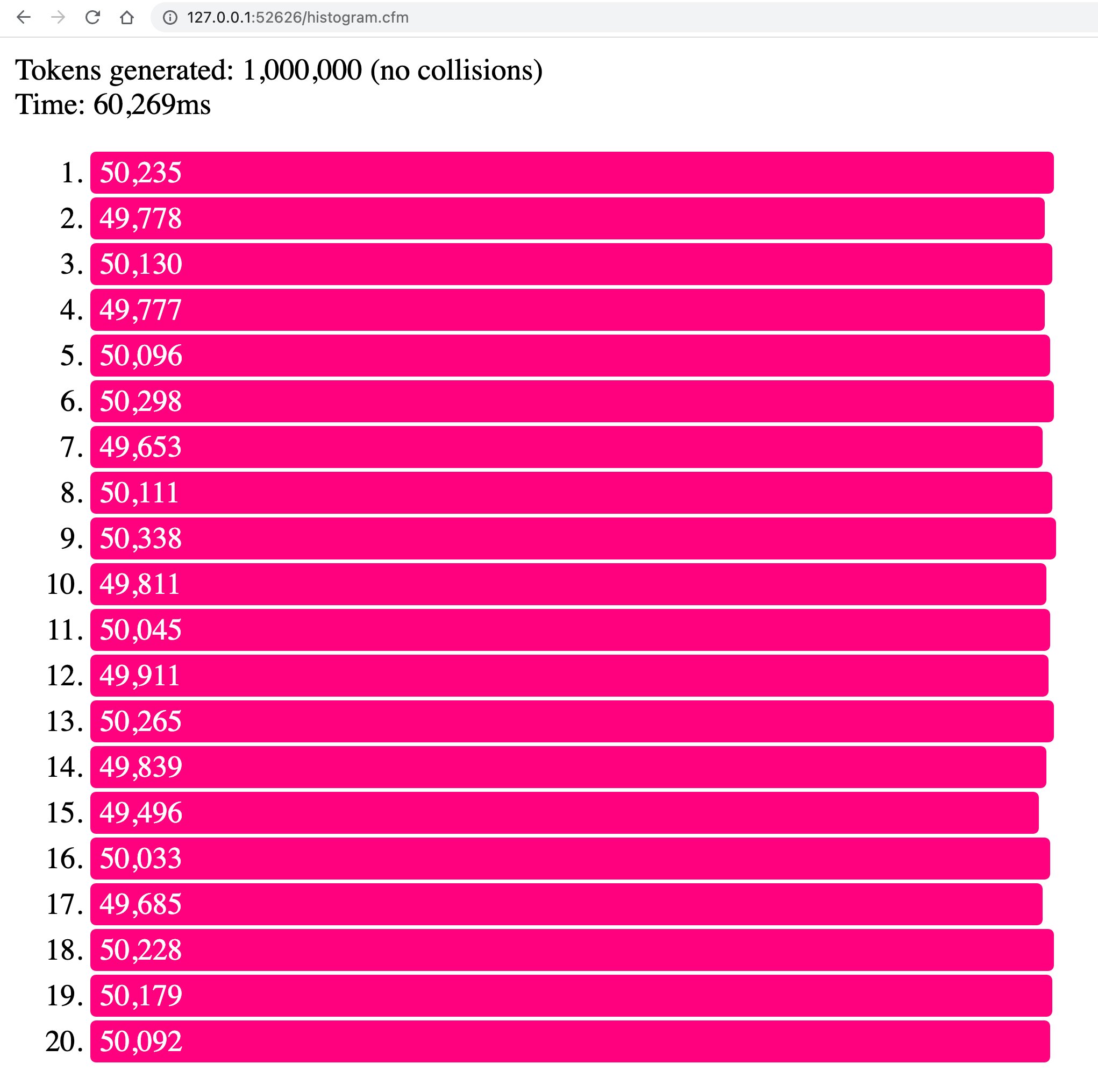
As you can see, the 1,000,000 CUID2 tokens are, roughly, evenly distributed across the 20 buckets. And, in those million keys, no collisions were detected.
I would not necessarily consider my CUID2 port as production ready since no one else has looked at it and I haven't tried running it in production. But, if you are looking for a CUID2 port in ColdFusion, hopefully this will at least point you in the right direction.
Not Sortable / Not Increasing
Part of the security issue that CUID2 is addressing (over CUID) is to remove any sense of sorting / increasing order. When an ID - of any kind - is generated in order, the order "leaks information" about the token. Since CUID2 has no predictable order, it is inherently more secure. Elliott talks about the security considerations more in the CUID2 repository.
Want to use code from this post? Check out the license.

Reader Comments
Here's an article that Eric Elliott wrote about his new Cuid2 approach (and why his previous approach was insufficient from a security standpoint): Identity Crisis: How Modern Applications Generate Unique Ids. It goes into a lot of depth (though much of what is there is also on the Cuid2 GitHub page as well).
I've been trying to look at the low-level performance of the
Cuid2.cfc- using some reflection, I'm dynamically instrumenting the methods to see how long they execute during the generation of 1M CUID tokens:www.bennadel.com/blog/4390-dynamically-instrumenting-coldfusion-component-methods-with-gettickcount-to-locate-performance-bottlenecks.htm
Surprisingly, the test is spending 30% of its time just running
randRange(). This seems somewhat strange.So, my current implementation takes about 60-seconds to generate 1M CUID tokens. Which is not terribly fast. I've been playing around with how to get the performance improved by:
Scoping all variable access (ie, adding the
arguments.andvariables.prefixes wherever they make sense.Using BIF (built-in functions) instead of Member Methods (ie,
len(value)instead ofvalue.len().Inlining some hot functions (such as the
toBase36()call).Through these means, I was able to get the cost of 1M CUID tokens down from about 60-seconds to 24-seconds. This is a significant performance improvement; but, at what cost?!
When I do this, the code becomes much less readable. Is it really worth the faster token generation? Is token generation really going to be a limiting factor in terms of performance. I have to remember that this only gets used during write operations; and, that the vast majority of applications are read heavy, not write heavy. Which means I may really be improving the performance of something that is, in and of itself, not a natural bottleneck in the application.
Out of curiosity, what's wrong with CreateUUID, apart from it being 11 chars longer? It's also compatible with SQL's uniqueidentifier datatype (if you insert an extra hyphen). I used it in an application that's been running for 17 years 24x7 and it's never clashed. It was interesting to hear how CUID2 works, a good article as always Ben. :-)
@Gary,
Honestly, I can't really speak to the pros/cons of UUIDs or CUIDs - I just like trying to build it. I still use Auto-incrementing values in my applications. Over in the CUID2 for JavaScript repository Elliott has some comparisons of CUID2 to other UUID algorithms.
I've updated the post with a Warning at the top to indicate that this is an incomplete version of the implementation. Only algorithms using the
SHA3family of hashing can be considered implementations of CUID2. And, sinceSHA3wasn't added until Java 9, implementing this for Java 8 would mean loading a 3rd-party JAR, which just makes this whole thing less developer friendly than I would like.Ok, I've removed the warning and updated the
Cuid2.cfcto default tosha3-256. This works fine on Java 9+; but, if you are still on Java 8, then it can be explicitly set tosha-256as a constructor argument. I've updated the blog post to include the optional argument description.