
Inspecting Primary And Secondary Index Key Utilization For MySQL 5.7.32 In Lucee CFML 5.3.7.47
The day before Thanksgiving, I was paged at 3:30AM because one of our API end-points suddenly starting failing on all requests. A quick look at the errors logs revealed one of my long-time worst nightmares: a column in our MySQL database had run out of "INT space". It was an old column and was accidentally defined as INT when it should have been defined as INT UNSIGNED. We fixed the issue by migrating the data-type on the column. But, in order to sleep at night, I need to know that this won't happen again. So, I've started to look at how I can introspect the MySQL database schema in order to see—and eventually measure—how much wiggle-room I have left in my Primary and Secondary indices.
In any relational database, the type of column determines how much data can be stored within it. In MySQL, numeric column's limit depends on whether or not it is signed. As I mention in my previous post on CF_SQL_INTEGER truncation behavior in Lucee, an INT column in MySQL has the following ranges:
SIGNED INT→ Range from -2,147,483,648 to 2,147,483,647.UNSIGNED INT→ Range from 0 to 4,294,967,295.
Using these known limits, I want to see if I can use MySQL's information_schema to generate insights on the current database state. Specifically, I want to look at the primary and secondary indices to see how close numeric values are to their theoretical max based on their data-type.
To be clear, non-indexed values can also run out of space. However, there is no efficient way to inspect non-indexed values without performing full-table scans. As such, even if we wanted to look at a non-indexed value, it would like not be possible without (potentially) impacting the overall database performance.
That said, values that are most likely to run out of space are primary keys - specifically AUTO_INCREMENT columns - which are implicitly indexed. And, when those values show up in other tables, as "foreign keys", they are usually indexed there as well using secondary keys. As such, by focusing on key constraints, I am confident that we will be able to inspect the most relevant data.
It looks like the information_schema has three tables that will serve our introspection purposes:
information_schema.TABLESinformation_schema.STATISTICSinformation_schema.COLUMNS
According to the MySQL docs, some of the values in these tables are cached statistics. As such, they may not be 100% accurate. In our exploration, however, we're going to use SQL statements to inspect real-time key values; so, the cached nature won't affect us this time.
By focusing on numeric keys - and, specifically the first column in those keys - we know that we can run the following SQL query using a "covering index":
SELECT
key_column
FROM
my_table
ORDER BY
key_column DESC
LIMIT
1
Since the MySQL database stores primary and secondary index values in order, getting the max and min values within the (first) indexed column only requires a single-read. It's incredibly fast! It pulls that data entirely out of the index without having to read any row-data.
Given this optimization, here's the plan:
- Find all numeric keys (primary and secondary).
- Determine their max theoretical value based on the column-type.
- Query for the max actual value using the above query.
- Calculate the percentage of "INT space" used.
In the end, I created two different ColdFusion scripts: one for Primary keys and one for Secondary keys. In reality, this could have been combined into a single script. But, I was just using trial-and-error and this made sense at 6AM this morning.
Here's the script I made for Primary Keys:
<cfscript>
// In this query, we're going to be inspect the numeric PRIMARY KEY columns to see
// how much wiggle-room they have in terms of INT storage space.
```
<cfquery name="stats">
SELECT
t.table_name,
t.table_rows,
/*
CAUTION: No all primary keys are auto incrementing values. On tables in
which the primary key is a foreign key reference, this column will be
returned as an empty value.
*/
t.auto_increment,
s.column_name,
s.cardinality,
c.data_type,
c.column_type,
IF( c.column_type LIKE '%unsigned%', 4294967295, 2147483647 ) AS max_possible_value,
/* These will be calculated in the ColdFusion code. */
( 0 ) AS current_value,
( 0 ) AS percent_used
FROM
information_schema.TABLES t
INNER JOIN
information_schema.STATISTICS s
ON
(
t.table_schema = 'invisionapp'
AND
s.table_schema = t.table_schema
AND
s.table_name = t.table_name
AND
/*
We only care about the PRIMARY KEY constraint in this particular
query. This is not the only column that can run out of space -
we'll look at other columns after this.
*/
s.index_name = 'PRIMARY'
AND
/*
Some tables have compound keys - that is, a non-synthetic primary
key that is composed of multiple columns. For the sake of this
experiment, we're going to assume that the first column is the
one that is likely to run out of space. As such, we're going to
limit the results to columns that are the FIRST column in the
sequence of index-columns.
*/
s.seq_in_index = 1
)
INNER JOIN
information_schema.COLUMNS c
ON
(
c.table_schema = t.table_schema
AND
c.table_name = t.table_name
AND
c.column_name = s.column_name
AND
/*
We only care about INT vs. UNSIGNED INT in this particular query.
While there are other types of numeric values, those are less
likely to cause a problem for us.
*/
c.data_type = 'int'
)
ORDER BY
t.table_name ASC
;
</cfquery>
```
// Now that we have the general stats on the primary keys, let's inspect each table
// and get its current primary key value.
// --
// NOTE: For tables that are using AUTO_INCREMENT column definitions, we could have
// used the "t.auto_increment" value in the above query. It's cache statistics; but,
// it would be close enough (cache lasts 24-hours according to MySQL docs).
loop query = stats {
// Since we know that this query contains the PRIMARY KEY columns, we know that
// we can efficiently get the MAX value by ordering the column DESC with a LIMIT
// of 1 without doing a full-table scan.
```
<cfquery name="pkey">
SELECT
( #stats.column_name# ) AS value
FROM
#stats.table_name#
ORDER BY
#stats.column_name# DESC
LIMIT
1
</cfquery>
```
stats.current_value[ stats.currentRow ] = val( pkey.value );
// Round-up for max possible FEAR value.
stats.percent_used[ stats.currentRow ] = ceiling( stats.current_value / stats.max_possible_value * 100 );
}
stats.sort( "percent_used, table_name, column_name", "desc, asc, asc" );
dump( stats );
</cfscript>
As you can see, I use the information_schema tables to figure out which columns pertain to numeric keys. I then iterate over that list of columns and, for each column, run the aforementioned SQL query to get the real-time max-value of the column. And, when we run the above ColdFusion code, we get the following output.
NOTE: This screenshot has been truncated for security purposes.
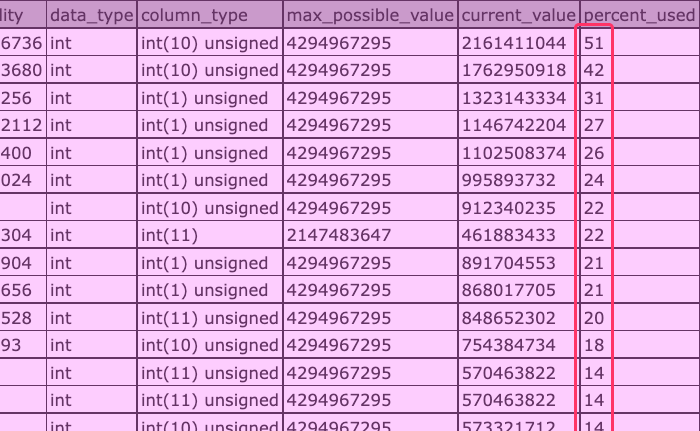
As you can see, I was able to gather the current value of the given, compare it to the max theoretical value of the column based on its type, and then calculate the percentage used for that key. Now, I should be able to start graphing that value in Datadog with attached monitoring and alerting thresholds.
The above ColdFusion script is for the primary keys; the following ColdFusion script is for the secondary keys. It's basically the same query except I'm changing a few of the conditions.
<cfscript>
// In this query, we're going to be inspect the numeric SECONDARY KEY columns to see
// how much wiggle-room they have in terms of INT storage space.
```
<cfquery name="stats">
SELECT
t.table_name,
t.table_rows,
s.column_name,
s.cardinality,
c.data_type,
c.column_type,
IF( c.column_type LIKE '%unsigned%', 4294967295, 2147483647 ) AS max_possible_value,
/* These will be calculated in the ColdFusion code. */
( 0 ) AS current_value,
( 0 ) AS percent_used
FROM
information_schema.TABLES t
INNER JOIN
information_schema.STATISTICS s
ON
(
t.table_schema = 'invisionapp'
AND
s.table_schema = t.table_schema
AND
s.table_name = t.table_name
AND
/*
We only care about the secondary column constraints in this
particular query.
*/
s.index_name != 'PRIMARY'
AND
/*
Many secondary indices use a compound key - a key composed of
multiple columns. Again, in order to keep things easy, we're
going to limit our scope to the first column in each index so
that we can efficiently gather the max value in the CFML.
*/
s.seq_in_index = 1
)
INNER JOIN
information_schema.COLUMNS c
ON
(
c.table_schema = t.table_schema
AND
c.table_name = t.table_name
AND
c.column_name = s.column_name
AND
/*
We only care about INT vs. UNSIGNED INT in this particular query.
While there are other types of numeric values, those are less
likely to cause a problem for us.
*/
c.data_type = 'int'
)
ORDER BY
t.table_name ASC
;
</cfquery>
```
// Now that we have the general stats on the secondary keys, let's inspect each table
// and get its current secondary key value.
loop query = stats {
// Since we know that this query contains columns that are the first column in an
// index sequence, we know that we can efficiently get the MAX value by ordering
// the column DESC with a LIMIT of 1 without doing a full-table scan.
```
<cfquery name="pkey">
SELECT
( #stats.column_name# ) AS value
FROM
#stats.table_name#
ORDER BY
#stats.column_name# DESC
LIMIT
1
</cfquery>
```
stats.current_value[ stats.currentRow ] = val( pkey.value );
// Round-up for max possible FEAR value.
stats.percent_used[ stats.currentRow ] = ceiling( stats.current_value / stats.max_possible_value * 100 );
}
stats.sort( "percent_used, table_name, column_name", "desc, asc, asc" );
dump( stats );
</cfscript>
I'm already feeling more confident that I'll be ready for the next key-failure. I intend to set something up as nightly scheduled-task that runs these queries and then stores the "percent used" value as a tagged statsD metric. When I have that working, though, I'll write it up as a fast-follow blog post.
Want to use code from this post? Check out the license.

Reader Comments
As a fast-follow to this post, I wanted to look at translating they key-space readings into StatsD Gauges such that I can graph and monitor the column sizes:
www.bennadel.com/blog/4166-recording-datadog-statsd-gauges-for-database-key-utilization-in-lucee-cfml-5-3-7-47.htm
At work, we use Datadog, which provides a special tagging extension to the normal StatsD metrics. This allows us to breakdown metrics by table/column values which, in turn, allows new columns to show up on our graphics automatically as the database schema changes over time! 💪💪💪
We use Microsoft SQL Server and I needed to audit the current max/min values of all numeric columns in a database (not just columns flagged as primary or secondary keys). I'm sharing here in case it's beneficial for other devs that use MSSQL.
I'm using this T-SQL that I found on the TechBrothersIT blog.
https://gist.github.com/JamoCA/95ef5759c507832b707fafd5515873bf
Upon initial review, it works well with ColdFusion 2016 and the Microsoft SQL JDBC driver. (We stopped using Adobe's DB driver back in CF8/9 as we needed to connect to a newer server that wasn't supported by Adobe yet.)
@James,
I'll tell you, one of the things I miss about using MS SQL (what I used in the beginning of my career) is the ability to create temporary tables as variables like that. I know MySQL can create "temporary" tables; but, they're not the same - I think they're still persisted to disk and you have to drop them (I can't quite remember all the quirks because I don't use them). Plus, MS SQL looks to have a lot of really cool advanced stuff added over the past decade or so - all the recursive SQL and pivot tables and doing things "over" other things (whatever that means 🤪). Anyway, good stuff - thanks for sharing!