
Request Tracing Propagation When Consuming Amazon SQS Queues In Lucee CFML 5.3.8.201
As I continue to explore the use of Amazon SQS queues in Lucee CFML, I have to start thinking about request tracing. In a monolithic application, request tracing is much less of a value-add since most operations happen within a single request. Once I start using a message queue to decouple steps within a larger workflow, however, I break out of that single-request boundary. As such, if I want to identify "message creation" as being related to "message consumption", I have to propagate the concept of tracing through the message queue life-cycle. I'm sure there are loads of ways to do this. So, what follows is just one possible way to propagate request tracing through Amazon SQS in a Lucee CFML 5.3.8.201 application.
View this code in my Amazon SQS Lucee CFML project on GitHub.
Regardless of message queues, request tracing itself is something that I've struggled with. Early on in my career, I felt very strongly that all request-tracing and request-metadata information should be explicitly passed-down through the call-stack. I wanted to - as much as possible - avoid anything that was "magical", such as globally-available scopes in ColdFusion.
Or, more specifically, the request scope. Because, as it turns out, I use "magical" scopes, like url, form, and cgi, all the time without concern. In fact, it's not uncommon for me to use the "magical" function, getHttpRequestData(), in conjunction with the cgi scope in order to determine the IP address of an incoming request.
NOTE: When I say "magical" in this context, what I mean is a value that can be referenced without it having been explicitly provided through some sort of Inversion of Control (IoC).
I tried to wrestle with this dogmatic fear of the request scope a year ago. And, I've come to accept the fact that my life would have been much easier had I leaned into the power of the request scope as a means to pass request metadata down through the call-stack. It turns out that a request-level, global scope avoids a lot of messy "argument drilling" and actually works to decouple layers of the application.
ASIDE: I'm using the term "argument drilling" here in homage to the concept of "prop drilling" in ReactJS wherein a set of values are blindly passed-down through a layer of the application.
Of course, my emotional brain still wants to limit the amount of "magic" that the request scope provides. What I want is something that is magical but is still also very explicit. To that end, I'm going to wrap my access to the request scope in a ColdFusion component, RequestMetadata.cfc.
This component is still consumed as a single-instance - not a singleton - in that there is only one instance cached within the application scope and then shared across each incoming request. However, since it interfaces with the request scope under the hood, it can still provide magical, dynamic values on a per-request basis while still also being injectable as an explicit dependency.
For the purposes of this demo, the only methods that this RequestMetadata.cfc ColdFusion component will provide revolve around request tracing. And, in this demo, that concept will be limited to a single value, request.requestId:
component
output = false
hint = "I provide methods for access metadata and tracing information relating to the current request processing."
{
/**
* I ensure that the "request.requestId" value exists. If it does not exist, it is
* generated and assigned to the request scope. In either case, the final requestId
* value is returned.
*
* NOTE: This method should be called as the very first line of processing in an
* inbound HTTP request so that all subsequent processing within the request is more
* likely to have access to the same value.
*/
public string function ensureRequestId() {
return( request.requestId ?: setRequestId( generateRequestId() ) );
}
/**
* I generate a new requestId value.
*/
public string function generateRequestId() {
return( "request-#createUuid().lcase()#" );
}
/**
* I get the requestId for the current request context. If no requestId has been set
* yet, this action generates and assigns a requestId.
*/
public string function getRequestId() {
return( ensureRequestId() );
}
/**
* I apply the given requestId to the current request context.
*/
public string function setRequestId( required string newRequestId ) {
return( request.requestId = newRequestId );
}
}
The intention of this ColdFusion component is that the ensureRequestId() method will be one of the very first actions invoked at the top of an incoming request. So, for example, in the onRequestStart() of the ColdFusion application framework component - Application.cfc - I might have something like this:
/**
* I get called once when the request is being initialized.
*/
public void function onRequestStart() {
// Setup the tracing ID for the rest of the request.
application.requestMetadata.ensureRequestId();
// .... truncated for snippet ....
}
This call would, internally to the RequestMetadata.cfc component, generate a new request ID and then store it in the request scope. Once this is done, every other reference to the requestId that is made within the bounds of the same request will all reference the same value.
Unless you call the setRequestId() method to override the existing requestId value; but, we'll get to that shortly.
Once we introduce a message queue into our ColdFusion workflow, request tracing takes on two new facets:
Taking the
requestIdin the current request and storing it alongside each message that is produced within a given request.Taking the
requestIdthat is stored alongside a given message and then associating it to the request that is consuming said message.
In my post exploring the separation of concerns when consuming Amazon SQS queues in Lucee CFML, I used a "glue layer" that acted as the point-of-contact between the message queue and the greater ColdFusion application. This glue layer is primarily responsible for directing messages and mapping actions; however, it can also serve as our request tracing propagation layer.
To explore this new concept, I've created a demo in which we use a message queue to send out a transactional email: the user submits an email address, we push that email address onto the queue, and then a background process pulls that message off of the queue and sends the email. We don't actually have a working email provider in this demo; however, we're going to assume that we have Postmark; and, that we're going to propagate the original requestId using a custom SMTP header, X-PM-Metadata-.
Now, our "emailer" doesn't know anything about Amazon SQS, the message queue or, the asynchronous nature of our invitation workflow. All it knows about is our magical RequestMetadata component:
component
output = false
hint = "I provide methods for sending transactional emails."
{
/**
* I initialize the email service.
*/
public void function init( required any requestMetadata ) {
variables.requestMetadata = arguments.requestMetadata;
}
// ---
// PUBLIC METHODS.
// ---
/**
* I send out a new user invitation email.
*/
public void function sendInvitation( required string toEmail ) {
// In this demo, we don't actually have an email API configured. As such, we'll
// just log to the console as a simulation.
systemOutput( "Sending invitation to [#toEmail#].", true );
// As part of the outgoing email simulation, let's include a custom SMTP header
// for our tracing ID. Since I use PostMark as my transactional email SaaS
// provider, I'm going to lean on their custom metadata headers. We'll be able to
// propagate this value through any PostMark webhooks.
systemOutput( "> X-PM-Metadata-Request-ID: [#requestMetadata.getRequestId()#]", true );
}
}
Again, we don't have a working transactional email SaaS (Software as a Service) provider - we're just using the systemOutput() function to simulate our call to Postmark. And, as part of that output, we're propagating the requestId. But, where does that requestId value come from?
Well, the user form that initiates this invitation workflow doesn't know anything about it:
<cfscript>
param name="form.toEmail" type="string" default="";
// If we have a new user email to process, put it on the message queue - a background
// thread will monitor the queue for new messages and then send out an invite email.
if ( form.toEmail.len() ) {
application.emailQueueService.addMessage(
"invitation",
{
toEmail: form.toEmail
}
);
}
</cfscript>
<cfoutput>
<!doctype html>
<html lang="en">
<head>
<meta charset="utf-8" />
<title>
Request Tracing Propagation When Consuming Amazon SQS Queues In Lucee CFML 5.3.8.201
</title>
<link rel="stylesheet" type="text/css" href="./index.css" />
</head>
<body>
<h1>
Request Tracing Propagation When Consuming Amazon SQS Queues In Lucee CFML 5.3.8.201
</h1>
<form method="post" action="./index.cfm">
<input
type="text"
name="toEmail"
placeholder="New user email..."
size="40"
maxlength="75"
autofocus
autocomplete="off"
/>
<button type="submit">
Send invitation
</button>
</form>
</body>
</html>
</cfoutput>
As you can see, there's no mention of the requestId here - all we have is a call to emailQueueService.addMessage(). This emailQueueService ColdFusion component is our aforementioned glue layer. It's the messy part of the application that binds the ColdFusion business logic to the Amazon SQS API. In the above template, it's responsible for outbound messages to the queue. And, as we'll see below, it's responsible for routing inbound messages to our EmailService component.
The two main methods of interest below are addMessage() and processMessage(). These two methods work with the requestId value as messages are being written to and then subsequently read from the Amazon SQS queue:
component
output = false
hint = "I provide methods for interacting with the email-queue - I GLUE the concept of the queue to larger application context."
{
/**
* I initialize the email queue service with the given SQS client. Note that the SQS
* client is assumed to be created specifically for the email-queue in Amazon SQS.
*/
public void function init(
required any sqsClient,
required any requestMetadata,
required any emailService
) {
variables.sqsClient = arguments.sqsClient;
variables.requestMetadata = arguments.requestMetadata;
variables.emailService = arguments.emailService;
}
// ---
// PUBLIC METHODS.
// ---
/**
* I create and persist a new message for processing the given transactional email.
*/
public void function addMessage(
required string emailType,
required struct emailData
) {
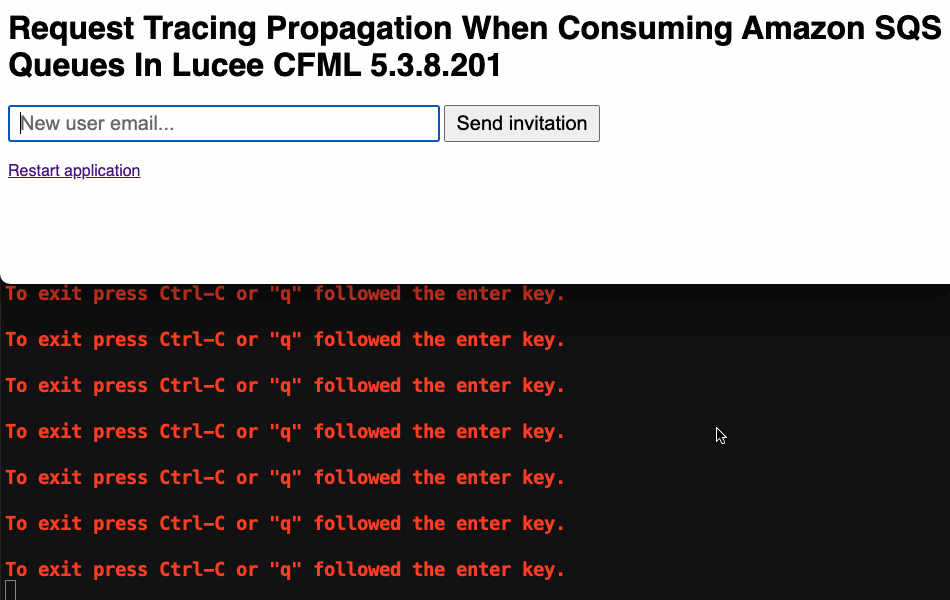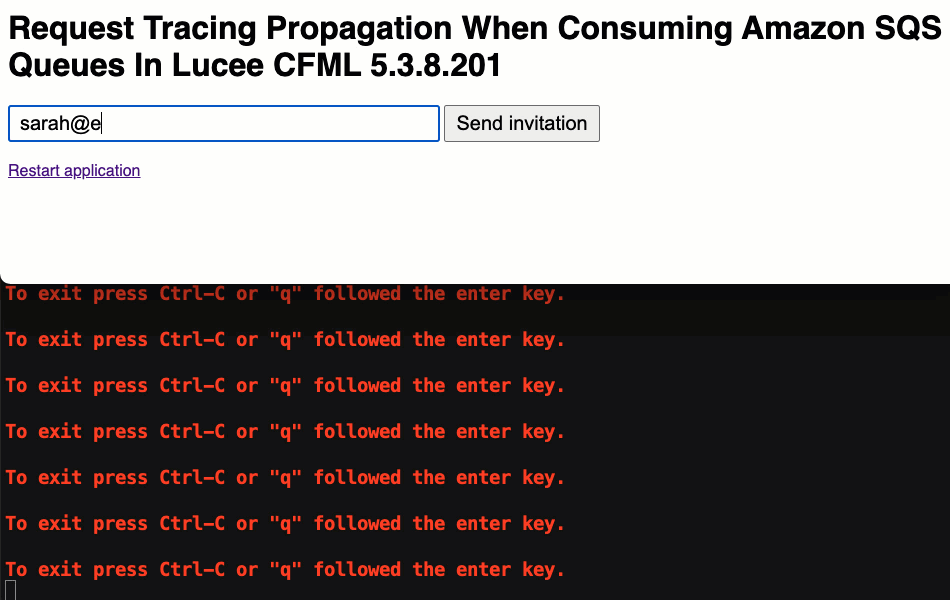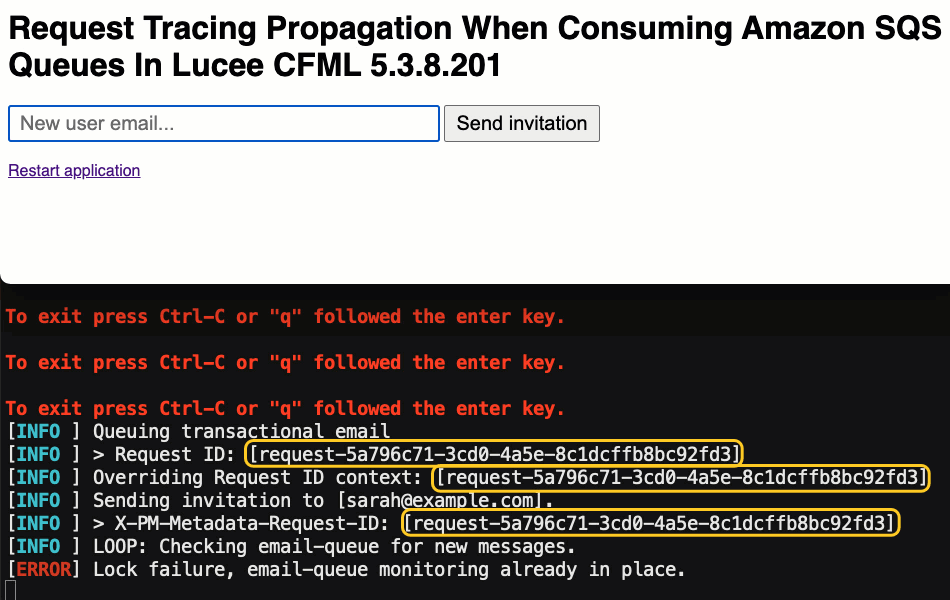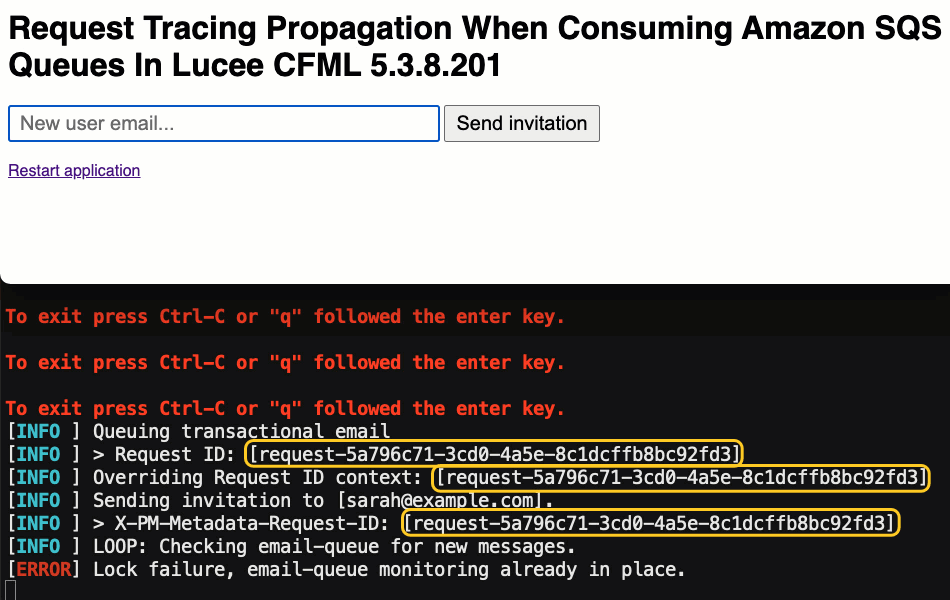
systemOutput( "Queuing transactional email", true );
systemOutput( "> Request ID: [#application.requestMetadata.getRequestId()#]", true );
// The QUEUE is DECOUPLING the incoming request from the subsequent processing.
// However, the overall workflow is still inherently linked. In order to make
// debugging this workflow easier, we're going to propagate the request tracing
// ID as an ATTRIBUTE on the SQS queue message. This way, we can tie the message
// processing to the message generation.
sqsClient.sendMessage(
serializeJson({
emailType: emailType,
emailData: emailData
}),
// Sending as an ATTRIBUTE, not as part of the core message. This is not a
// critical distinction - I probably just wanted a reason to use the
// attributes collection :D
{
requestId: requestMetadata.getRequestId()
}
);
}
/**
* I delete the given message from the queue.
*/
public void function deleteMessage( required struct message ) {
sqsClient.deleteMessage( message.receiptHandle );
}
/**
* I process the given message, translating the message into an interaction with the
* rest of the application logic. In this case, we're sending transactional emails.
*/
public void function processMessage( required struct message ) {
var body = deserializeJson( message.body );
var emailType = body.emailType;
var emailData = body.emailData;
// This service only knows how to GLUE the message queue to the rest of the
// application, it doesn't know what goes on under the hood. As such, for each
// message, we want to override the current request ID context so that lower-
// level processing can carry on (and consume request metadata) as if it were
// part of the original request. This will make the overall workflow easier to
// debug in the future.
systemOutput( "Overriding Request ID context: [#message.attributes.requestId#]", true );
requestMetadata.setRequestId( message.attributes.requestId );
switch ( emailType ) {
case "invitation":
emailService.sendInvitation( emailData.toEmail );
break;
default:
systemOutput( "Unknown email type: [#emailType#]", true, true );
break;
}
}
/**
* I look for new messages on the queue.
*
* CAUTION: While this request will block-and-wait for new messages to arrive (if
* waitTime argument is non-zero), it will do so only once. We are not putting the
* onus of continual polling inside this component. Instead, we are placing that
* responsibility in another area of the app (in this demo, a scheduled task).
*/
public void function processNewMessages(
numeric maxNumberOfMessages = 3,
numeric waitTime = 20,
numeric visibilityTimeout = 10
) {
var messages = sqsClient.receiveMessages( argumentCollection = arguments );
for ( var message in messages ) {
// Since we are gathering more than one message at a time in this demo (in
// order to reduce the dollars-and-cents cost of making API calls to Amazon
// SQS), we want to wrap each message processing in a try-catch so that one
// "poison pill" doesn't prevent the other messages from being processed.
try {
processMessage( message );
} catch ( any error ) {
systemOutput( "An email-queue message failed to process.", true, true );
systemOutput( "> Request ID: [#requestMetadata.getRequestId()#]", true, true );
systemOutput( message, true, true );
systemOutput( error, true, true );
}
deleteMessage( message );
}
}
}
As I explained in my first post on writing messages to Amazon SQS in Lucee CFML, there's the message body, which is a String representation of your message. And then, there are the message attributes. These are key-value pairs that can be sent alongside the message in order to help with subsequent processing and routing decisions.
In this case, I'm propagating the current requestId value as an attribute of the message. When it comes time to process the message, I then pull that requestId attribute out of the message and apply it to the current request scope using the requestMetadata.setRequestId() method. Once this is done, any reference to the requestId that is made during the rest of the processing will inherently propagate the requestId from the original request that initiated our new-user invitation workflow.
But, thar be dragons with this approach. If I process multiple messages within the same request, I may end up overwriting the requestId several times. As long as the processing of each message is completely synchronous, everything will be fine. However, if something in the call-stack spawns an asynchronous thread, there's no way to determine which requestId will be associated with the request scope during the asynchronous thread execution.
ASIDE: Since I've started exploring the use of Amazon SQS in Lucee CFML, several people have suggested binding the AWS SQS queue to an AWS Lambda Function such that each messages is processed by an isolated Lambda invocation. This would, of course, remove any need to overwrite the
requestIdmore than once during message processing. But, it does mean yet another moving part in an increasingly distributed architecture.
That said, if we run this ColdFusion application and send some invitations, we can see this in the server logs:
There's more to this demo from a code perspective; however, it's not terribly relevant to the concept of request tracing. Nor is it different than what I outlines in my separation of concerns post. That said, if you want to view the remaining code:
Application.cfc- this configured the application and wires all of the ColdFusion components together. It also spawns a background thread (in the form of a Scheduled Task) that monitors the Amazon SQS queue.email-queue-manager.cfm- the Scheduled Task that runs in the background, continually executing long-polling against the Amazon SQS queue.SqsClient.cfc- a wrapper around the Amazon SDK for Java. This simplifies the calls to the SQS API.
Message queues are all quite new to me. I've read about them in the past; but, these posts are really my first hands-on attempt at consuming Amazon SQS queues in Lucee CFML. As such, there's bound to be issues with this approach. So, if anyone has any pro-tips on how they perform request tracing with message queues, I'm quite keen to hear them!
Want to use code from this post? Check out the license.

Reader Comments
Great stuff, Ben!
I use the request scope all the time. In fact I convert some of my application variables [including components references] into the request scope like:
Inside onRequestStart
I was always under the impression, we had to lock application scope calls outside onApplicationStart?
I was also told never to call application variables directly, inside templates.
So, the request scope acts as a wrapper for such variables.
I also know that a MURA CMS plug-in, has a wrapper method onGlobalRequestStart where all request variables are held. After updating a request variable here, it is necessary to refresh the application, to set the changes. So, I believe this might be a wrapper for the application scope?
But, maybe all this advice is outdated! 🤣
Sorry. This is the code [you must have been a bit puzzled]: 😂
I mean this works best when you have a component reference or a big struct that is expensive, in terms of memory.
Obviously my example is trivial. But, it is really the caching idea behind it, that I want to emphasize.
@Charles,
Yeah, "when to lock" is always a little fuzzy in my head, especially when we're dealing with a layer of abstraction above the Java layer. The way I understand it, Structs are synchronized under the hood. Meaning, it's always safe to have multiple requests read/write to the same Struct at the same time. I believe you can even iterate (
for-in) over a Struct safely from two different threads simultaneously.Arrays, on the other hand, are not synchronized and reading/writing an Array from two threads can lead to deadlocks and infinite loops (since pointers can get messed up - in ColdFusion, I think Arrays are really "linked lists" under the hood, not native Array data-types).
The
requestscope should be very safe to read/write without locking since you know it's already locked-down to a single request. Of course, if you spawn aCFThreadthat also writes to therequestscope, you might have to think about it a bit more; but, for the most part, the chances of a race-condition on therequestscope is already heavily limited.Thank you for your analysis.
Finally, after 20 years, I can write correct onRequestStart variables! 😀
@Charles,
💪 Noice!