
Mapping Arrays-To-Structs And Structs-To-Arrays Using Mapping Functions In Lucee CFML 5.3.6.61
When mapping one data-set onto another data-set in ColdFusion, we can usually use the built-in .map() functions. This works great when the input and the output data-sets are the same type. But, every now and then, I want to map an Array onto a Struct; or, a Struct onto an Array; which isn't something that the current mapping functions cater to. Normally, I implement this type of mapping with a for-loop; but, as a sort of code-kata, I wanted to see what a more "functional" type of solution might look like in Lucee CFML 5.3.6.61.
With the built-in mapping functions, the resultant data-set is defined by the return value of the iterator / operator function. But, when the mapping operation changes the underlying data-type, using the return value as the drive feels a bit awkward. For example, how would you map an Array item onto a Struct entry using a return value? One option would be to return the value as some sort of tuple:
<cfscript>
function arrayToStructOperator( item, index ) {
return( [ index, item ] );
}
</cfscript>
Here, the return value is a "two tuple" in which the first item represents the "Key" in the resultant Struct; and, the second item represents the "Value" in the resultant Struct. This "works"; but, is quite unattractive and is hard to understand if you didn't write the code.
Another option would be to ignore the return value altogether and use a passed-in "mapper" function:
<cfscript>
function arrayToStructOperator( mapTo, item, index ) {
mapTo( index, item );
}
</cfscript>
Here, the mapTo() function, which is passed to the each iteration of the operator, takes two arguments - key and value - which drive the resultant Struct collection. To me, this feels more clear; and, even allows us to skip items within the array (should we want to do that).
I wanted to use this approach in my exploration. Here's what I came up with for mapping Arrays-to-Structs in Lucee CFML:
<cfscript>
friends = [ "Sarah", "Danny", "Todd", "Vera", "Seema" ];
lookup = mapArrayToStruct(
friends,
( mapTo, friend, index ) => {
// The mapTo() function setups the (key, value) pair in the resultant Struct.
mapTo(
friend.lcase(),
{
initials: friend.left( 1 ).lcase(),
name: friend
}
);
}
);
dump( lookup );
// ------------------------------------------------------------------------------- //
// ------------------------------------------------------------------------------- //
/**
* I map the given Array onto a Struct using a mapTo() operator which is passed to the
* given callback for each item in the array. The mapTo() function takes two arguments
* which are consumed as the (key,value) of the resultant struct. If the mapTo()
* function is NOT called for a given Array item, that Array item is excluded from the
* resultant mapping. The callback function is called with the following arguments:
*
* operator( mapTo, item, index, collection )
*
* @collection I am the collection being mapped.
* @operator I am the operator being invoked on each collection item.
*/
public struct function mapArrayToStruct(
required array collection,
required function operator
) {
var results = {};
// This mapping closure will be passed to the operator for EACH ITEM in the given
// collection. It's how the items are mapped to the key/value Struct entries.
var mapTo = ( key, value ) => {
results[ key ] = ( value ?: nullValue() );
};
// In Lucee CFML, the CFLoop tag for Arrays can expose BOTH the INDEX and the
// VALUE at the same time, which allows us to iterate over the collection faster
// and with less complexity (when compared to a typical FOR-Loop).
loop
index = "local.index"
item = "local.item"
array = collection
{
operator( mapTo, item, index, collection );
}
return( results );
}
</cfscript>
Like the build-in .map() functions, my mapArrayToStruct() function operator receives the value, index, and initial collection as arguments. But, it also receives a mapTo() function as the first argument. It's this function that allows us to explicitly map an Array-item to a Struct entry. And, when we run the above Lucee CFML code, we get the following output:
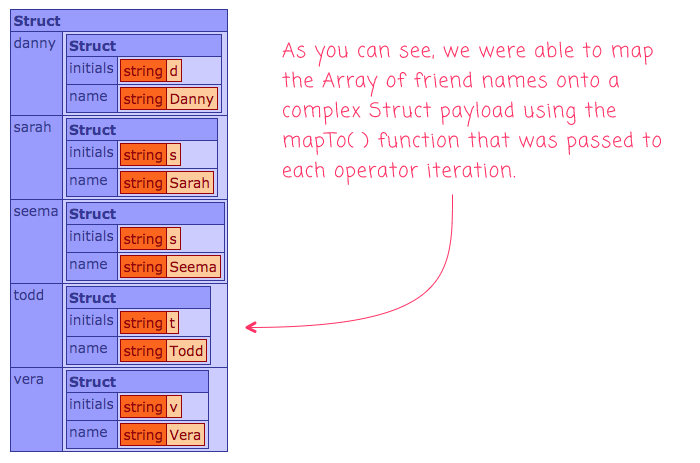
As you can see, we were able to take our Array of friend-names and map it onto a complex Struct result using the mapTo() function.
Now, we can take that resultant structure and go back the other way, mapping the Struct to an Array, also using a mapTo() function:
<cfscript>
lookup = {
sarah: { initials: "S", name: "Sarah" },
danny: { initials: "D", name: "Danny" },
todd: { initials: "T", name: "Todd" },
vera: { initials: "V", name: "Vera" },
seema: { initials: "S", name: "Seema" }
};
friends = mapStructToArray(
lookup,
( mapTo, key, value ) => {
// The mapTo() function setups the item in the resultant Array.
mapTo( value.name );
}
);
dump( friends );
// ------------------------------------------------------------------------------- //
// ------------------------------------------------------------------------------- //
/**
* I map the given Struct onto an Array using a mapTo() operator which is passed to
* the given callback for each entry in the Struct. The mapTo() function takes one
* argument which is consumed as the (item) of the resultant Array. If the mapTo()
* function is NOT called for a given Struct entry, that Array item is excluded from
* the resultant mapping. The callback function is called with the following
* arguments:
*
* operator( mapTo, key, value, collection )
*
* @collection I am the collection being mapped.
* @operator I am the operator being invoked on each collection entry.
*/
public array function mapStructToArray(
required struct collection,
required function operator
) {
var results = [];
// This mapping closure will be passed to the operator for EACH ENTRY in the
// given collection. It's how the items are mapped to the Array items.
var mapTo = ( value ) => {
results.append( value );
};
// In Lucee CFML, the CFLoop tag for Structs can expose BOTH the KEY and the
// VALUE at the same time, which allows us to iterate over the collection faster
// and with less complexity (when compared to a typical FOR-Loop).
loop
index = "local.index"
item = "local.item"
collection = collection
{
operator( mapTo, index, item, collection );
}
return( results );
}
</cfscript>
As you can see, the concept here is exactly the same - we're iterating over some data-structure and, for each entry, we're calling the operator and passing in the mapTo() function which is used to define the resultant Array. And, when we run this Lucee CFML code, we get the following output:

Anyway, just some fun ColdFusion noodling on a Monday morning - a little something-something to help get the creative juices flowing. I really love that Lucee CFML exposes both "Index" and "Value" in a single CFLoop tag - that's super convenient.
Want to use code from this post? Check out the license.

Reader Comments
If you want to return a different data type, wouldn't you just use the built in
reduce()function?Or even a little simpler (can't edit my original comment)
@Brad,
That's a good point. I often forget about
.reduce(). There's something about it's function-signature that never quite set right in my tum-tum. I think it's the fact that I am to define the initial data-structure at the end. Usually, when I go to write a.reduce()call, I get to the end and just feel like it would be easier to read as a simple for loop.For example, I could accomplish all of this with a
forloop:This ^^ is where I usually end-up after I try to write a reduce. Which, I tend to feel ends-up being even more readable.
Which begs the question: why do I often want to have a more "functional" way of doing this? I suppose the answer is that I often want something I can chain off of? Maybe. Something where I could call:
mapStructToArray( ... ).map( ... ).filter( ... )... kind of a thing. And, to be fair,
.reduce()does give me that opportunity. So, you do raise a good point!Yes, to your point, the FP versions of map, each, reduce are always going to be possible via manual iteration and if that's more readable to you, then no issue using it. For me, the difference is more philosophical. An FP approach allows me to forget the collection as a whole for a moment, and only worry about the little bundle of logic necessary to process a single item. Plus I get a local function scope to use so my variables don't become litter in the greater page scope, which is even more important since CFML doesn't have block scoping. I don't need to worry about orchestrating the looping mechanics myself, which often times requires additional flags and counter variables. I think you appreciate all that too, which is why you wrote an entire post basically rewriting a custom implementation of reduce, but named
mapStructToArray():)Also, A little trick for not specifying the default value of the accumulator (that even JS doesn't support) is instead of this:
You can do this where you just set it as the default param value on the closure
The main drawback of that approach is that if the
collectionis empty, the closure never runs at all, and the default is never used, andreduce()will return null in those cases.And for what it's worth, you aren't required to set a default value for your accumulator at all. You can simply detect when it's null inside your closure, but that's typically more boilerplate, not less.
@Brad,
Yeah, to be clear, I enjoy the Functional approaches to the other methods. I use
.map()and.filter()all day long :D I especially love the async iteration for them, which I often use to download files in parallel (where it makes sense).Cool tip about the default value of a Functional argument! To be honest, I tend to get much more "relaxed" about defining iteration arguments (ie, omitting things like
requiredandarray) since I kind of look at them as "implementation details" that are super-local to the context in which they are being used. As such, I totally forgot you could even provide a default.