
Using RegEx To Filter Keys With Redis Key Scanner In Lucee CFML 5.2.8.50 And Jedis
Earlier this week, I wrote about Redis Key Scanner, which is a small Lucee CFML app that allows me to safely and efficiently iterate over the key-space of a Redis database such that I can get a sense of what keys exist, how long they will be persisted (ie, what is their Time To Live), and where they might be coming from. As I've started to use my Redis Key Scanner in Production, I realized that it needed better filtering capabilities. As such, I've gone back and added Include and Exclude filters that leverage POSIX Regular Expressions (RegEx) in order to narrow down the list of keys being displayed on each cursor iteration.
View this code in my Redis Key Scanner project on GitHub.
In the first implementation of the Redis Key Scanner, filtering was implemented on top of the SCAN operation. If we look at the signature of the Redis SCAN operation, we have:
SCAN cursor [MATCH pattern] [COUNT count] [TYPE type]
The MATCH parameter can be used to include keys based on a glob style pattern. So, for example, I could use the pattern *session* to include keys that contain the substring, session. This is useful; but, quite limited. And, in fact, as I've been using the Redis Key Scanner to explore my Redis database, what I've found is that I want to exclude keys much more than I want to include them.
To enhance the filtering feature, I've dropped the use of the MATCH argument altogether. Instead, I'm pulling back all of the keys in the given iteration; then, I'm using Lucee CFML's POSIX Regular Expression support to filter the keys in memory.
This approach may sound like it is much more "expensive". However, you have to remember that - even in the native MATCH functionality - the pattern is applied to the results after they are retrieved. The difference is that the SCAN operation's MATCH does the filtering on the Redis side whereas Redis Key Scanner now does the filtering on the application side. In both approaches, the iteration over the key-space is unchanged; but, in my approach, more of those keys are transfered over the wire to the ColdFusion application. This small overhead in performance is, hopefully, offset by the vast increase in functionality.
To see how this update has been implemented, all we have to do is look at the .scan() method of the Scanner.cfc ColdFusion component:
/**
* I scan over the Redis keys, using the given cursor and pattern.
*
* NOTE: The Include / Exclude patterns are applied to the keys AFTER they have been
* scanned AND RETURNED to the server. As such, it's possible to use patterns that
* result in zero results prior to the end of a full iteration of the Redis database.
*
* @scanCursor I am the cursor performing the iteration.
* @scanPatternInclude I am the post-scan include-RegEx to apply to the result-set.
* @scanPatternExclude I am the post-scan exclude-RegEx to apply to the result-set.
* @scanCount I am the number of keys to scan in one operation.
*/
public struct function scan(
required numeric scanCursor,
required string scanPatternInclude,
required string scanPatternExclude,
numeric scanCount = 100
) {
assertIsConfigured();
var scanParams = loader
.create( "redis.clients.jedis.ScanParams" )
.init()
.count( scanCount )
;
var scanResults = withRedis(
( redis ) => {
return( redis.scan( scanCursor, scanParams ) );
}
);
var results = {
previousCursor: scanCursor,
cursor: scanResults.getCursor(),
keys: scanResults.getResult()
};
// If we have an include RegEx pattern, limit the results to INCLUDE those keys
// that MATCH the given pattern.
if ( scanPatternInclude.len() ) {
results.keys = results.keys.filter(
( key ) => {
return( key.reFindNoCase( scanPatternInclude ) );
}
);
}
// If we have an exclude RegEx pattern, limit the results to INCLUDE those keys
// that DO NOT MATCH the given pattern.
if ( scanPatternExclude.len() ) {
results.keys = results.keys.filter(
( key ) => {
return( ! key.reFindNoCase( scanPatternExclude ) );
}
);
}
return( results );
}
As you can see, each iteration of the Redis cursor pulls all of the matched keys into the ColdFusion memory space (as results.keys). Then, using Lucee CFML, I'm reducing the results using the .filter() and .reFindNoCase() member methods.
ASIDE: The Redis
SCANoperation matches keys using a case-sensitive comparison. By pulling the keys into Lucee CFML first, I am able to make matching more intuitive for the user by using a case-insensitive filter.
And, of course, in order to leverage this new filtering, I've updated the user interface (UI) to include form-inputs for both the Include and Exclude Regular Expression patterns:
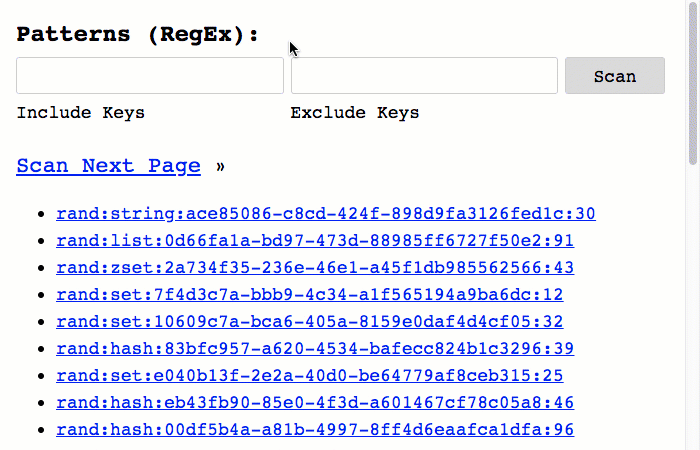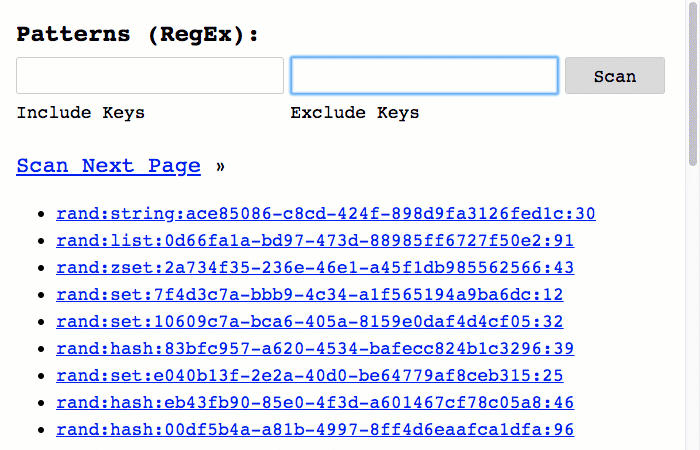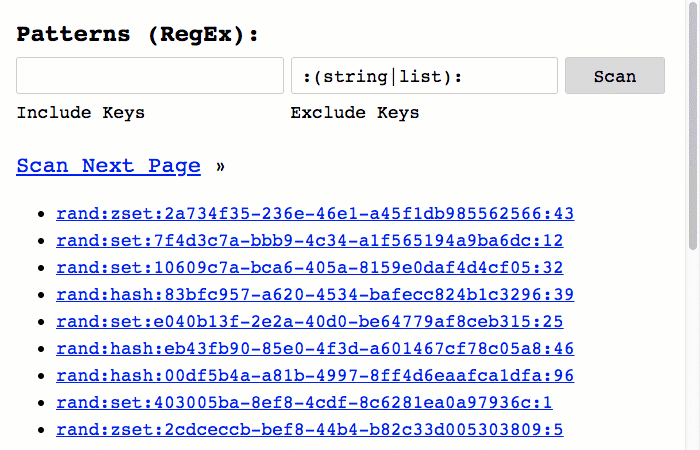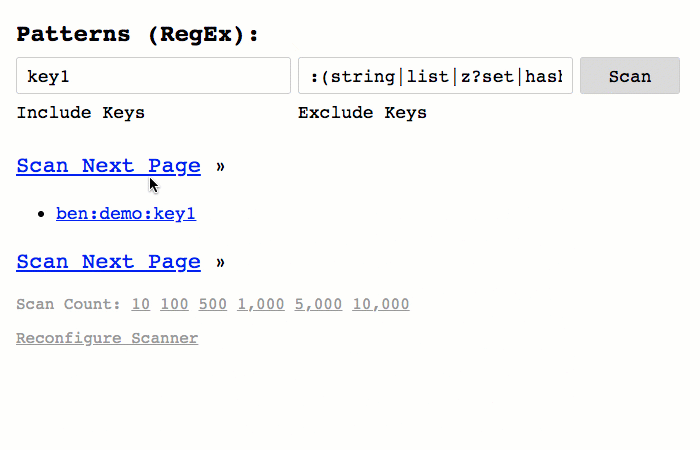
As you can see, I'm able to use fairly robust Regular Expression (RegEx) patterns in order to both include and exclude keys during the Redis key-space iteration.
ASIDE: I've also added the ability to define the
COUNTof eachSCANoperation. But, I have not showcased this feature in this post or its demonstration.
Inspecting our Redis database has been fascinating. I'm seeing keys in the key-space that are bizarrely out of place. Some keys appear to relate to features that were removed years ago. It's also obvious that many places in the application attempt to set multiple keys without a Transaction (leaving keys in place with no TTL); and, even more saddening is seeing how many places in the application create keys that will live forever. It's no wonder our Redis instance is using so much memory.
Once I finish my investigation, I'll have to write a Lucee CFML script that iteratively walks the key-space and applies a TTL (Time to Live) to all keys that don't have one. But, that's a topic for a future post.
Want to use code from this post? Check out the license.

Reader Comments
Just out of interest why do you have keys that live forever, or do you think that was a mistake on the Dev's part.
And how do you actually expire a key?
@Charles,
It is typically a mistake on the part of the developer. The issues fall into two camps:
The developer simply did not think about how the key was going to be used and never set a TTL (Time to Live). As such, they key just lives forever.
The developer set a TTL; but, didn't set it as part of a single operation or
multitransaction and something broke half-way through. In those cases, the key-value is set, but the TTL is never assigned.That's not to say that you can't use Redis for persistent, long-term storage. I'm only saying that we haven't used it for that, and therefore the keys that we have that are everlasting are all "bugs" in one way or another.
@All,
As a follow-up, I created this Redis Key Scanner to help me better understand the contents of the Redis database such I could create a subsequent task that scans the key-space and adds TTL values:
www.bennadel.com/blog/3712-adding-a-ttl-to-all-persistent-keys-in-redis-using-launchdarkly-feature-flags-and-lucee-cfml-5-2-9-40.htm
This code was a lot of fun to write!