
BigSexy Poems Uses Angular And The Datamuse API To Help You Write Poetry
Beneath my nerdy exterior, I fancy myself a romantic. And, one of the ways in which I like to express that part of my psyche is through poetry. If you've followed this blog for long enough, you'll know that I like to write poems about ColdFusion and jQuery and Regular Expressions. But, I also like to write poems about love - y'all just don't get to see them sexy gems. For years, I've been using the RhymeZone site to aid in my writing endeavors. Just recently, however, I noticed that RhymeZone exposes an API - the Datamuse API. And, the moment I saw that, I knew that I had to build an Angular application to help fuel my fiery passions. I call this application, BigSexy Poems!
Run this demo in my BigSexy Poems project on GitHub.
View this code in my BigSexy Poems project on GitHub.
When I write poetry, the three tools that I find myself using most often are:
- Syllable counts for rhyming schemes (counted using my fingers).
- Rhyme suggestions (via rhymezone.com).
- Synonym suggestions (via thesaurus.com).
After reading through the Datamuse API documentation, I discovered that the Datamuse API can actually provide all three of these features. So, I set off to build a interface that brought all three facets together in one clean, easy-to-consume interface.
The first step was to create a Datamuse API Client. In Angular, this was fairly straightforward because the Datamuse API only exposes two end-points - "words" and "suggestions" - both of which return the same kind of "word" data:
// Import the core angular services.
import { HttpClient } from "@angular/common/http";
import { Injectable } from "@angular/core";
// ----------------------------------------------------------------------------------- //
// ----------------------------------------------------------------------------------- //
export interface Match {
defs?: string[];
numSyllables?: number;
score?: number;
tags?: string[];
word: string;
}
interface SuggestionsConfig {
s: string;
v?: string;
max?: number;
}
interface WordsConfig {
ml?: string;
sl?: string;
sp?: string;
rel_jja?: string;
rel_jjb?: string;
rel_syn?: string;
rel_trg?: string;
rel_ant?: string;
rel_spc?: string;
rel_gen?: string;
rel_com?: string;
rel_par?: string;
rel_bga?: string;
rel_bgb?: string;
rel_rhy?: string;
rel_nry?: string;
rel_hom?: string;
rel_cns?: string;
v?: string;
topics?: string;
lc?: string;
rc?: string;
max?: number;
md?: string;
qe?: string;
}
type Config = SuggestionsConfig | WordsConfig;
interface RequestParams {
[ key: string ]: string;
}
@Injectable({
providedIn: "root"
})
export class DatamuseClient {
private httpClient: HttpClient;
// I initialize the datamuse client.
constructor( httpClient: HttpClient ) {
this.httpClient = httpClient;
}
// ---
// PUBLIC METHODS.
// ---
// I get Datamuse suggestions based on the given configuration.
public async getSuggestions( config: SuggestionsConfig ) : Promise<Match[]> {
return( await this.makeRequest( "sug", config ) );
}
// I get Datamuse words based on the given configuration.
public async getWords( config: WordsConfig ) : Promise<Match[]> {
return( await this.makeRequest( "words", config ) );
}
// ---
// PRIVATE METHODS.
// ---
// I make the HTTP request to the Datamuse API.
private async makeRequest( resource: string, config: Config ) : Promise<Match[]> {
var result = await this.httpClient
.get<Match[]>(
`https://api.datamuse.com/${ resource }`,
{
params: this.makeRequestParams( config ),
withCredentials: true
}
)
.toPromise()
;
return( result );
}
// I take the various configuration objects and normalize them into a set of request
// parameters that can be used with the HttpClient.
private makeRequestParams( config: Config ) : RequestParams {
var params: RequestParams = {
max: "10"
};
for ( var key of Object.keys( config ) ) {
params[ key ] = config[ key ].toString();
}
return( params );
}
}
As you can see, there's very little going on there. The hardest part of consuming the Datamuse API is just trying to understand what all the Datamuse API arguments mean; and, how they can be used in combination. This is a non-trivial task and required a good deal of trial-and-error.
To make the Datamuse API easier to integrate, I wrapped it in an abstraction that was tailored for the application - the WordService. The WordService class exposes methods for counting syllables, finding rhymes, and finding synonyms; but, it does so in a way that prevents - or, rather, tries to prevent - the Datamuse implementation from leaking through the layers of the call-stack.
I'm not entirely happy with the abstraction that I came up with. But, for the time being, it works well enough. One of the hardest parts to encapsulate was the idea of a "strong match". The strong matches are the words in the rhyme and synonym lists that get highlighted (bolded) as being particularly good choices. I didn't want the Datamuse API "score" concept to leaking through to the UI layers; plus, the "score" is documented as being "not interpretable as anything other than relative ranking." So, the WordService attempts to parle all of that information into an "isStrongMatch" property which the UI can consume in a "dumb" way.
// Import the core angular services.
import { ErrorHandler } from "@angular/core";
import { Injectable } from "@angular/core";
// Import the application components and services.
import { DatamuseClient } from "./datamuse-client";
import { Match as DatamuseMatch } from "./datamuse-client";
import { StorageService } from "./storage.service";
// ----------------------------------------------------------------------------------- //
// ----------------------------------------------------------------------------------- //
export type TypeOfSpeech = "noun" | "verb" | "adjective" | "adverb" | "unknown";
export interface MeansLikeResults {
query: string;
typeOfSpeech: TypeOfSpeech;
words: Word[];
}
export interface RhymeResults {
query: string;
words: Word[];
}
export interface SyllableResults {
[ key: string ]: number;
}
export interface Word {
value: string;
syllableCount: number;
typeOfSpeech: TypeOfSpeech;
isStrongMatch: boolean;
}
interface SyllableCountCache {
[ key: string ]: number;
}
@Injectable({
providedIn: "root"
})
export class WordService {
private datamuseClient: DatamuseClient;
private errorHandler: ErrorHandler;
private storageService: StorageService;
private syllableCountCache: SyllableCountCache;
// I initialize the word service.
constructor(
datamuseClient: DatamuseClient,
errorHandler: ErrorHandler,
storageService: StorageService
) {
this.datamuseClient = datamuseClient;
this.errorHandler = errorHandler;
this.storageService = storageService;
this.syllableCountCache = Object.create( null );
this.loadFromStorage();
}
// ---
// PUBLIC METHODS.
// ---
// I get words that generally mean the same thing as the given word.
public async getMeansLikes( word: string ) : Promise<MeansLikeResults> {
var rawResults = await this.datamuseClient.getWords({
ml: word,
qe: "ml",
md: "ps", // p: part of speech, s: syllable count.
max: 500
});
rawResults = this.filterOutScoreless( rawResults );
rawResults = this.filterOutTagless( rawResults );
rawResults = this.filterOutAntonyms( rawResults );
rawResults = this.filterOutProperNouns( rawResults );
var queryTypeOfSpeech: TypeOfSpeech = "unknown";
// Since we are using "qe" (query echo), the first result should be the word that
// we are searching for, unless Datamuse didn't recognize it.
if ( rawResults.length && ( rawResults[ 0 ].word === word ) ) {
// Strip off the first result.
var echoResult = rawResults[ 0 ];
rawResults = rawResults.slice( 1 );
queryTypeOfSpeech = this.getTypeOfSpeech( echoResult.tags );
}
var results = rawResults.map(
( item, index, collection ) => {
// Take advantage of the syllable-count metadata that was returned with
// each of the word results. We can cache this in order to short-circuit
// future API calls.
this.cacheSyllableCountMetadata( item.word, item.numSyllables );
var typeOfSpeech = this.getTypeOfSpeech( item.tags );
var isStrongMatch = this.isSynonym( item.tags );
return({
value: item.word,
syllableCount: ( item.numSyllables || 0 ),
typeOfSpeech: typeOfSpeech,
isStrongMatch: isStrongMatch
});
}
);
return({
query: word,
typeOfSpeech: queryTypeOfSpeech,
words: results
});
}
// I get words that rhyme with the given word.
public async getRhymes( word: string ) : Promise<RhymeResults> {
var rawResults = await this.datamuseClient.getWords({
rel_rhy: word,
md: "ps", // p: part of speech, s: syllable count.
max: 500
});
var results = this.filterOutScoreless( rawResults ).map(
( item, index, collection ) => {
// Take advantage of the syllable-count metadata that was returned with
// each of the word results. We can cache this in order to short-circuit
// future API calls.
this.cacheSyllableCountMetadata( item.word, item.numSyllables );
// The score that is passed back from Datamuse is (documented as
// being) not interpretable as anything concrete - it is merely a way
// to rank results. As such, we're going to consider the first 80% of
// the results to be "strong" matches; with the caveat that anything
// less that 100 is not a strong match. Just making it up as we go
// here :D
if ( item.score < 100 ) {
var isStrongMatch = false;
} else {
var isStrongMatch = ( index <= Math.max( collection.length * 0.8 ) );
}
// When getting rhymes, the "part of speech" is not a critical component.
// As such, if there are no tags, then we can just default to an empty
// collection.
var typeOfSpeech = this.getTypeOfSpeech( item.tags );
return({
value: item.word,
syllableCount: ( item.numSyllables || 0 ),
typeOfSpeech: typeOfSpeech,
isStrongMatch: isStrongMatch
});
}
);
return({
query: word,
words: results
});
}
// I get the syllable counts for the given collection of words.
// --
// NOTE: Since this method makes parallel requests, it catches individual errors and
// returns an object that may contain partially-degraded word results (ie, where the
// syllable count is zero).
public async getSyllableCounts( words: string[] ) : Promise<SyllableResults> {
var unknownWords = words.filter(
( word ) => {
return( ! ( word in this.syllableCountCache ) );
}
);
// If there are any unknown words, let's populate the local cache before we
// process the contextual request. This way, the entire match can be calculated
// using the local cache.
// --
// CAUTION: We are NOT GOING TO CACHE failed requests.
if ( unknownWords.length ) {
var promises = unknownWords.map(
async ( word ) => {
// Since we're making a number of requests in parallel, we don't want
// to let one bad request kill the entire response. If one of the
// requests fails, we'll just have to re-try it next time.
try {
var results = await this.datamuseClient.getWords({
sp: word,
qe: "sp",
md: "s", // s: syllable count.
max: 1
});
// At this point, even though the result came back successfully,
// there's no guarantee that it's the word we were looking for.
// Since we're using the "SP" spelling end-point, the result may
// contain a "spelling suggestion", not the word that we were
// searching for. As such, we need to check the results before we
// attempt to cache them.
if ( results.length ) {
// If the word that came is NOT THE SAME WORD we requested,
// it means the API doesn't understand the word we are
// looking for. That will not change the next time. Let's
// cache this as zero.
if ( results[ 0 ].word !== word ) {
this.syllableCountCache[ word ] = 0;
// The word DOES MATCH and has a valid syllable count.
} else if ( results[ 0 ].numSyllables ) {
this.syllableCountCache[ word ] = results[ 0 ].numSyllables;
}
}
} catch ( error ) {
this.errorHandler.handleError( error );
}
}
);
await Promise.all( promises );
// Once the parallel requests come back, we should (may) have changes to the
// syllable count cache that we want to persist for next time.
this.saveToStorage();
} // END: Unknown words.
var results = words.reduce(
( reduction, word ) => {
// CAUTION: Even at this point, the cache may not have the word we are
// looking at (due to a network or API failure). As such, we're going to
// fall-back to "0".
reduction[ word ] = ( this.syllableCountCache[ word ] || 0 );
return( reduction );
},
Object.create( null )
);
return( results );
}
// ---
// PRIVATE METHODS.
// ---
// I determine if the given collection contains the given reference.
private arrayContains( collection: any[], value: any ) : boolean {
var foundItem = collection.find(
( item ) => {
return( item === value );
}
);
return( !! foundItem );
}
// When we make calls to Datamuse, we are always asking for the number of syllables
// to be returned in the response metadata. This will help us build out the cache of
// syllable counts.
private cacheSyllableCountMetadata( word: string, numSyllables?: number ) : void {
// If the syllable count was not available, there's nothing to cache.
if ( ! numSyllables ) {
return;
}
// If the word is already cached, we can skip.
if ( word in this.syllableCountCache ) {
return;
}
// If the word contains a space, it's a turn-of-phrase. In such a case, we won't
// know where the distribution of syllables falls in that phrase. As such, it's
// not easy to cache.
if ( word.includes( " " ) ) {
return;
}
this.syllableCountCache[ word ] = numSyllables;
this.saveToStorage();
}
// I return a Datamuse response that excludes antonyms.
private filterOutAntonyms( results: DatamuseMatch[] ) : DatamuseMatch[] {
var filteredResults = results.filter(
( result ) => {
return( ! this.arrayContains( result.tags, "ant" ) );
}
);
return( filteredResults );
}
// I return a Datamuse response that excludes proper nouns.
private filterOutProperNouns( results: DatamuseMatch[] ) : DatamuseMatch[] {
var filteredResults = results.filter(
( result ) => {
var isNoun = this.arrayContains( result.tags, "n" );
var isProper = this.arrayContains( result.tags, "prop" );
return( ! ( isNoun && isProper ) );
}
);
return( filteredResults );
}
// I remove any Datamuse matches that don't have a score. If there is no score, then
// the word or phrase barely matches the query. It's probably not worth returning.
private filterOutScoreless( results: DatamuseMatch[] ) : DatamuseMatch[] {
var filteredResults = results.filter(
( result ) => {
return( "score" in result );
}
);
return( filteredResults );
}
// I return a Datamuse response that excludes items without a tags property.
private filterOutTagless( results: DatamuseMatch[] ) : DatamuseMatch[] {
var filteredResults = results.filter(
( result ) => {
return( "tags" in result );
}
);
return( filteredResults );
}
// I return the part of speech indicated in the given tags collection. Or, unknown
// if the tags do not contain any known indicator.
private getTypeOfSpeech( tags?: string[] ) : TypeOfSpeech {
if ( ! tags ) {
return( "unknown" );
}
var tag = tags.find(
( tag ) => {
return(
( tag === "n" ) ||
( tag === "v" ) ||
( tag === "adj" ) ||
( tag === "adv" ) ||
( tag === "u" )
);
}
);
switch ( tag ) {
case "n":
return( "noun" );
break;
case "v":
return( "verb" );
break;
case "adj":
return( "adjective" );
break;
case "adv":
return( "adverb" );
break;
default:
return( "unknown" );
break;
}
}
// I determine if the given tags indicate a synonym match.
private isSynonym( tags: string[] ) : boolean {
var value = tags.find(
( tag ) => {
return( tag === "syn" );
}
);
return( !! value );
}
// I try to update the cache using data from the storage service.
private loadFromStorage() : void {
// NOTE: Object.assign() can handle anything that's not an object. As such, we
// don't have to worry about the .getItem() coming back undefined - if it does,
// the value will just be ignored, leaving our cache untouched.
Object.assign(
this.syllableCountCache,
this.storageService.getItem( "syllable-counts" )
);
}
// I try to save the current cache to the storage service.
private saveToStorage() : void {
this.storageService.setItem( "syllable-counts", this.syllableCountCache );
}
}
The rest of the Angular application just takes this WordService, consumes it, and transforms responses into something that can be used by the user interface (UI). It's not perfect; and, there's a lot of cool stuff we can add; but, ultimately, I'm quite pleased with the results:
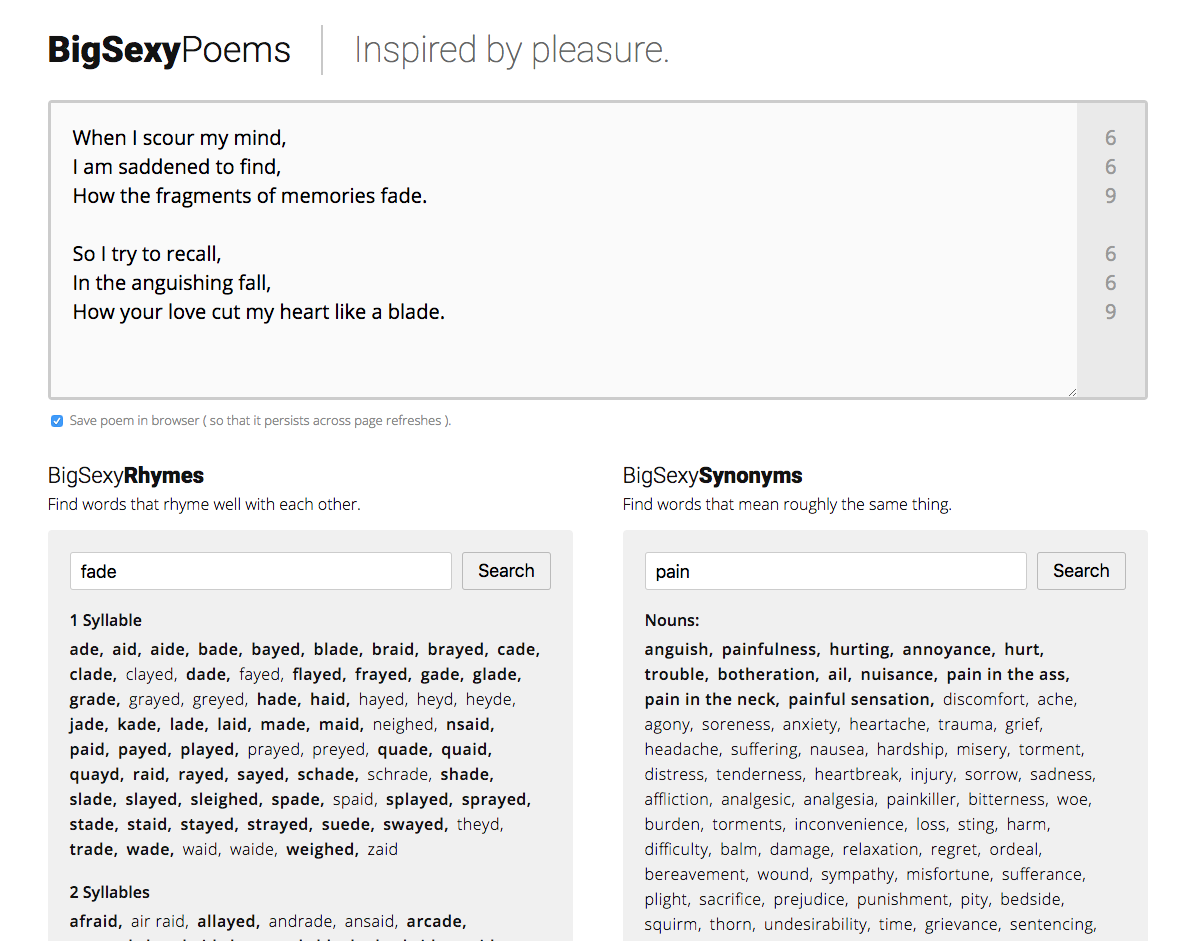
Originally, my long-term plan was to create a Docker-based application that would use Angular on the front-end; but, then, make calls to a back-end that proxied the Datamuse API and cached responses in a Redis database. Of course, that was before I realized that you could consume the Datamuse API over CORS-based (Cross-Origin Resource Sharing) AJAX requests. That kind of changes the landscape. I think there would still be value in having a dedicated back-end. But, for the moment, that's not a decision I have pressure to make.
If nothing else, this was a great Angular code kata! Hopefully you can see how fun and exciting Angular and TypeScript are to work with. TypeScript - especially in this application - forces you to really think about the shape of data and about how it can be passed-around within a call-stack. No more making assumptions that just "happen to work" most of the time.
Epilogue: What Is A BigSexy?
BigSexy is your muse. BigSexy is your inspiration. BigSexy is the part of your soul that feels deeply, lives with abandon, and loves without limits. BigSexy is the creative part of your consciousness that you don't understand and that you can't live without. BigSexy is the spirit of life.
Want to use code from this post? Check out the license.

Reader Comments