
MySQL Multi-Range Read (MRR) Optimization Caused A Partial Database Outage
For the last few days, I've been working on a database performance optimization that decomposed a very complicated, multi-JOIN query into a series of much more straightforward queries. As a byproduct of this refactoring, I was able to move some of the database calls off of the master database and over to one of the read-replicas. To be honest, I was kind of excited about this task. If there's anything that I love more than writing SQL, it's watching the database CPU graph drop after a deployment. Unfortunately, the only thing that dropped after yesterday's deployment was my stomach - right through the floor. Just minutes after deploying, the CPU graph on the read-replica went from calm to catastrophic!
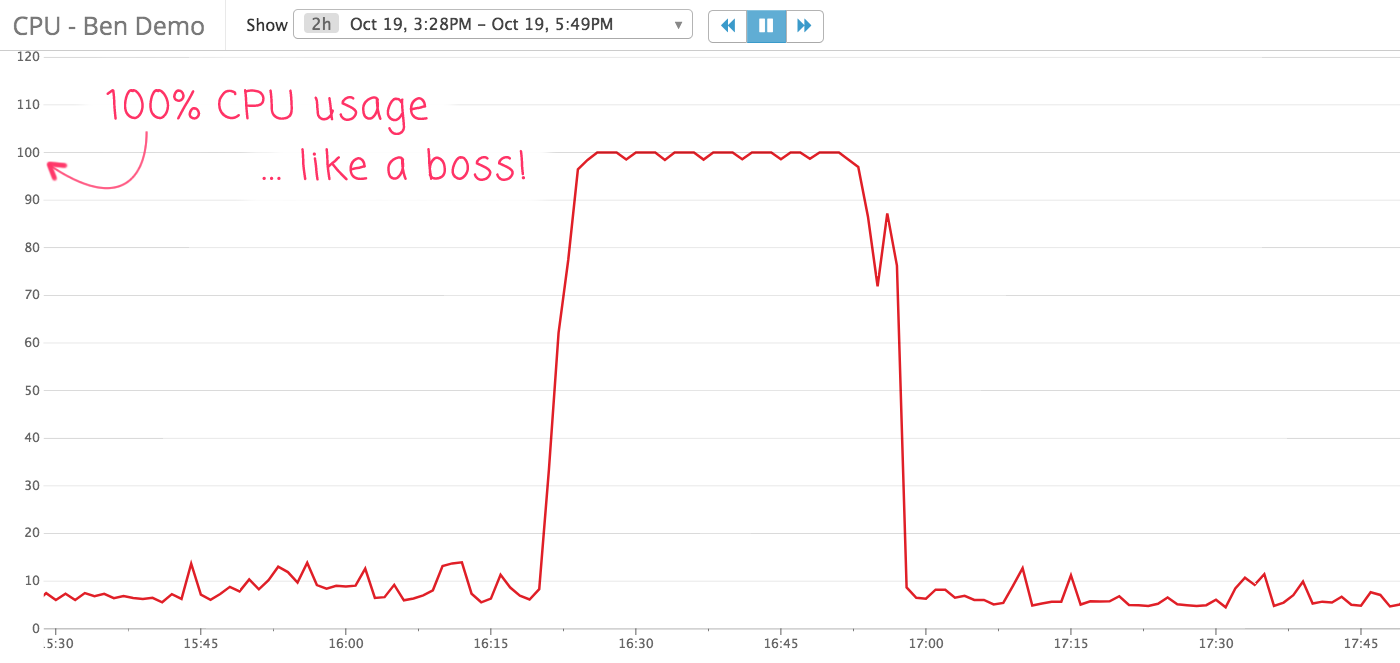
Well, that escalated quickly! And, caught me completely off-guard. All the testing that I had done seemed thorough. It worked locally. It worked in staging. It even worked in production when I turned on the feature flag for my test users. And, all of the "EXPLAIN" output that I had run on the new queries - prior to deployment - seemed to indicate that each query was well indexed and highly performant. However, when I flipped the feature flag on for everyone - well, the CPU graph speaks for itself.
We immediately flipped the feature flag off and start manually killing long-running queries. The replica significantly slowed down (both in replication lag and response time); and, I could see errors in the logs for hanging-requests; but, it never took the production app offline. Thank goodness for LaunchDarkly!
After the dust settled, I started digging into the incident, pouring over the slow query logs and the process list output. It was confusing - even in the logs, the new queries seemed to run very fast. In an attempt to cast a wider net, I started to increase the time-window of my slow-query-log search. Then, WAT?! There was a large subset of queries that took over 20-minutes to complete and were trying to read-in millions of records:
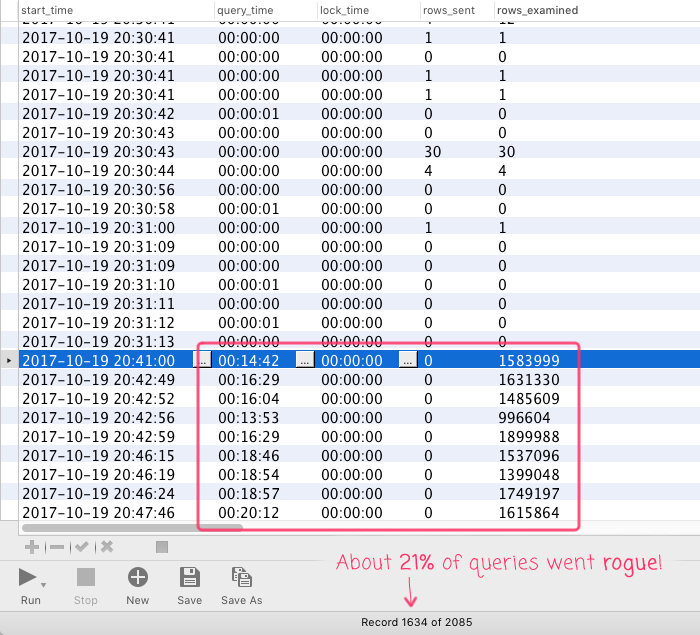
NOTE: Keep in mind that this is only for the queries that ran slow enough to show up in the slow-query-log (which I think has a 200ms threshold at this time). As such, this 21% is likely to be quite a bit smaller in the larger context of all the queries related to the refactoring.
When I ran the "EXPLAIN" on these specific query instances, I saw something that I had never seen before:
Using index condition; Using where; Using MRR; Using temporary; Using filesort
What's this, "using MRR," you speak of?
It turns out, MRR stands for "Disk-Sweep Multi-Range Read". And, it's an optimization that MySQL applies if it thinks that your query is about to perform inefficient disk access to retrieve data:
Reading rows using a range scan on a secondary index can result in many random disk accesses to the base table when the table is large and not stored in the storage engine's cache. With the Disk-Sweep Multi-Range Read (MRR) optimization, MySQL tries to reduce the number of random disk access for range scans by first scanning the index only and collecting the keys for the relevant rows. Then the keys are sorted and finally the rows are retrieved from the base table using the order of the primary key. The motivation for Disk-sweep MRR is to reduce the number of random disk accesses and instead achieve a more sequential scan of the base table data.
I don't fully understand how this works; or, what threshold is required to switch the query optimizer over to the new plan; or, why this "optimization" was only applied to about 21% of the new queries. But, I can say that, for those queries, it ended up creating a query execution plan that attempted to pull millions of records into memory.
To understand the context of this MRR query optimization, imagine that I have a table that represents "links" from one entity to another. The "SHOW CREATE TABLE" for this table might look something like this:
CREATE TABLE demo_link (
id int(1) unsigned NOT NULL AUTO_INCREMENT,
entityID int(1) unsigned NOT NULL,
targetEntityID int(1) unsigned NOT NULL,
/* ... other columns ... */
PRIMARY KEY (id),
KEY IX_byTarget (targetEntityID) USING BTREE,
KEY IX_byEntity (entityID, targetEntityID) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8 ROW_FORMAT=COMPACT;
In this table, the "entityID" is the source of the link and the "targetEntityID" is the destination of the link. But, the destination is not required. If the link points to a non-entity value, like an external URL, the "targetEntityID" is zero.
When consuming this table in the refactored code, I was compiling a list of entity IDs; then, I was passing that list of IDs into the query for a set of IN-clauses using ColdFusion template interpolation (in the following query, the "##" delimiters represent variable interpolation of a string):
SELECT
l.entityID,
COUNT( * ) AS linkCount
FROM
demo_link l
WHERE
l.entityID IN ( #entityIDList# )
AND
l.targetEntityID IN ( #entityIDList#, 0 ) -- NOTICE THE ZERO!!
GROUP BY
l.entityID
;
This query was attempting to gather some statistics about the links attached to a particular set of entities. With the requirement that each link entity and its target both be in the given ID-list. However, notice that at the end of the "target" ID-list, I'm also appending a zero. This accounts for links that don't target an entity but rather link to something like an external URL.
The indices on this table should be fine. I have an index that includes the two columns in the WHERE clause as part of a compound key: (entityID, targetEntityID). And, in the vast majority of the new queries - the ones that even ran slow enough to show up in the slow-query-log - this manifested with the given "EXPLAIN" output:
Using where; Using index
But, in the 21% of slow-queries for this new code, the MRR - Multi-Range Read - optimization bypassed my desired index and attempted to use the other index on "targetEntityID". Essentially, MySQL tried to run this portion of the query first:
l.targetEntityID IN ( #entityIDList#, 0 )
Unfortunately, the selectivity on the zero is atrocious! There are millions of links in the database that have zero as the "targetEntityID". So, what was intended to be an optimization for disk access ended up reading a crushing number of records into memory. Hence the 100% CPU usage.
To work around this MRR "optimization," my co-worker Vitaliy Mogilevskiy suggested that I create a derived table for the first part of the WHERE clause and then run the second part of the WHERE clause against the result. Something like this:
SELECT
temp.entityID,
COUNT( * ) AS linkCount
FROM
-- By creating a derived table, we don't get to leverage the full compound key;
-- but, we do force MySQL to use the "right" index to collect the intermediary rows.
(
SELECT
l.entityID,
l.targetEntityID
FROM
demo_link l
WHERE
l.entityID IN ( #entityIDList# )
) AS temp
WHERE
temp.targetEntityID IN ( #entityIDList#, 0 ) -- NOTICE THE ZERO!!
GROUP BY
temp.entityID
;
By creating the derived table, we only get to leverage the first column in the compound key. However, it does prevent MySQL from applying the MRR optimization. So, although this approach is certainly slower that using the full compound key, it's infinitely faster that reading millions of rows from the wrong index. With this derived table in place, when I run an "EXPLAIN" on the new query, I get the following:
DERIVED: Using where; Using temporary; Using filesort
INNER: Using where; Using index
As you can see, no more "using MRR"!
Ultimately, it would be great to have some sort of materialized view of this statistical data that is kept up-to-date. But, I don't have that. So, I have to make do with the database structures that I do have. And, it seems like creating a derived table will be sufficient for avoiding the Multi-Range Read optimization while still leveraging the prefix of the compound index.
I love SQL - it's just a wonderful adventure!
EPILOGUE
It's awesome that I've learned something new about MySQL. But, the truth is, I don't yet know how to bake this insight into my future database work. Meaning, this only affected a subset of the individual queries. So, how do I account for that? How do I validate query execution plans when only some instances of those queries are problematic? Do I just have to know that this MRR - Multi-Range Read - optimization exists and try to preemptively create derived tables to prevent it? Or, do I deploy code and then wait to see if any of it starts running poorly?
Ultimately, the reason that this all exploded was the "0" being appended to the second-range condition. That's what ruined the selectivity. So, maybe I should only worry about this when I have a range that includes a value with horrible selectivity? Of course, that seems like a massively complicated mental model to keep in the forefront of my mind while also trying to solve a myriad of other problems. That doesn't seem sustainable.
Want to use code from this post? Check out the license.

Reader Comments
Part of what made debugging this incident challenging was the fact that in MySQL's slow_log table, the "start_time" is actually the "end" or "log" time of the query. This means that queries actually show up "out of order", so to speak:
www.bennadel.com/blog/3358-mysql-s-slow-query-log-start-time-column-is-actually-the-end-time-of-the-query.htm
That said, with a little date-math, we can make the slow_log table much more intuitive (in my opinion).
Hi Ben
What happens if you do:
AND (
l.targetEntityID in (...)
OR
l.targetEntityID = 0
)
Would it help with the scan or would MySQL optimize this back to your version or something similar?
@Morten,
Great question - I tried that. No luck - same exact result. I believe that the MySQL optimizer actually normalized the "IN ()" construct to be equivalent to a series of OR-conditions. As such, I'm pretty sure the execution plan comes out to be exactly the same.
I did try to play around with MySQL "hint' syntax for "NO_MRR":
https://dev.mysql.com/doc/refman/5.7/en/optimizer-hints.html#optimizer-hints-index-level
... but I couldn't get it to work. I think MySQL also has a syntax where you can explicitly tell it which index to use. But, since I couldn't get the "hint" syntax to work, I figured that any meta-solution would be "brittle" at best. At least with the derived query, I *know* it will be consistent.