
Managing Stream Back-Pressure During Asynchronous Tasks Using READABLE and DATA Events In Node.js
Over the weekend, I looked at using Node.js Transform streams as a means to manage back-pressure while executing asynchronous tasks (such as inserting stream data into a MongoDB database) during Stream consumption. I thought this was a clever approach; but, to be clear, it's not a perfect approach. By using the .pipe() method with a Transform stream, you have to worry about handling errors (which may unpipe your transform stream) and you still have to put the Transform stream into "flowing" mode so that it will start consuming upstream data. Since this approach - like any other approach - has pros and cons, I thought it would be worthwhile to look at a few other ways to manage asynchronous tasks being executed within the context of a Node.js Stream.
In my previous post, I used a Transform stream to parle stream data into MongoDB operations because the Transform stream automatically managed back-pressure, preventing the upstream sources from loading data too aggressively. But, Node.js also gives us the ability to manage back-pressure explicitly using either the "readable" event or the "data" event. To see these two approaches in action, I want to take my demo from over the weekend and refactor just the parts that execute the MongoDB operation. And, to reduce the signal-to-noise ratio, let's outline the workflow first and then look at the specifics afterwards.
Here's the flow of data with the "MongoDB processing" portion excluded. Basically, we're creating a file input stream, logging data-reads from that input stream (so as to observe the effects of back-pressure), piping that stream into the ndjson (Newline-Delimited JSON) stream, batching records into groups of 5, and then - the part that's excluded - pushing those batched items into a mocked-out MongoDB database:
// Require the core node modules.
var chalk = require( "chalk" );
var fileSystem = require( "fs" );
var ndjson = require( "ndjson" );
var through2 = require( "through2" );
// ----------------------------------------------------------------------------------- //
// ----------------------------------------------------------------------------------- //
// *********************************************************************************** //
// CAUTION: In the following code, I am manually setting many of the highWaterMark
// properties on the various streams in an attempt to make the console-logging more
// human-consumable and meaningful for the DEMO.
// *********************************************************************************** //
// The ndjson stream will pull data out of the input stream (file), split it on the
// newline character, deserialize each line as a separate JSON (JavaScript Object
// Notation) document, and then emit the native JavaScript value as a data item.
var inputStream = fileSystem.createReadStream(
( __dirname + "/data.ndjson" ),
// The default highWaterMark for a fs read-stream is 64KB (not the normal 16KB
// default of the core Readable stream). In order to not buffer too much memory at
// once -- FOR THE SAKE OF THE DEMO -- we're going to limit the buffer to 1KB.
{
highWaterMark: ( 1 * 1024 )
}
);
// There's a good chance that we're using the ndjson storage format because we're
// dealing with a massive amount of data and attempting to treat the data as a single
// object would become untenable. As such, we want to make sure that we don't read all
// of the data into memory at the same time or we run the risk of running out of memory.
// To see how data flows out of the ndjson stream, let's create a simple through stream
// that logs through-traffic to the console. This way, we can see how fast data is
// being pulled out of the data file and into memory for parsing.
var doStream = inputStream.pipe(
through2(
// Let's use the same buffer size as the read-stream so that our monitoring
// stream doesn't accidentally suck too much data into memory. Since a through
// stream has both a WRITE and a READ buffer, having a 1024 byte buffer size
// will actually allow ( 2 * 1024 ) bytes to be pulled out of the file (I think).
{
highWaterMark: ( 1 * 1024 )
},
function handleWrite( chunk, encoding, done ) {
console.log( chalk.bgMagenta.white.bold( "Pulling data from file:", chunk.length, "bytes" ) );
this.push( chunk, encoding );
done();
}
)
);
// Pipe the input file into the ndjson stream.
// --
// NOTE: By default, the ndjson stream uses a 16K (16,384) buffer size for the WRITE
// buffer. However, since the highWaterMark affects both the WRITE buffer and the READ
// buffer, this actually allows the ndjson stream to buffer 16K OBJECTS IN MEMORY in the
// READ buffer. FOR THE SAKE OF THE DEMO, we're going to lower this to prevent so much
// data form being buffered.
var transformStream = doStream.pipe(
ndjson.parse({
highWaterMark: 10 // Bytes for WRITE buffer, Objects for READ buffer.
})
);
// As objects come out of the ndjson stream, deserialized back into native JavaScript
// objects, we want to persist them into a local (mocked out) MongoDB store. However,
// we have a limited number of connections available (and only so many connections that
// can even be queued). As such, we're going to process the items in batches of 5. This
// through stream will buffer the deserialized items, and then pass-through an array of
// 5-items when it becomes available.
var batchingStream = (function batchObjectsIntoGroupsOf5( source ) {
var batchSize = 5;
var batchBuffer = [];
var batchingStream = source.pipe(
through2.obj(
function handleWrite( item, encoding, done ) {
batchBuffer.push( item );
// If our batch buffer has reached the desired size, push the batched
// items onto the READ buffer of the transform stream.
if ( batchBuffer.length >= batchSize ) {
this.push( batchBuffer );
// Reset for next batch aggregation.
batchBuffer = [];
}
done();
},
function handleFlush( done ) {
// It's possible that the last few items were not sufficient (in count)
// to fill-out an entire batch. As such, if there are any straggling
// items, push them out as the last batch.
if ( batchBuffer.length ) {
this.push( batchBuffer );
}
done();
}
)
);
return( batchingStream );
})( transformStream );
// Now that we're pulling batches of items out of the ndjson stream, we're going to
// persist them to a mocked-out MongoDB database. However, since MongoDB writes are
// asynchronous, we want to wait until MongoDB returns before we move onto the next
// batch of documents. This way, we don't instantly pull all the ndjson content into
// memory and try to spawn an enormous number of connections to MongoDB.
// ----------------------------------------------------------------------------------- //
// ----------------------------------------------------------------------------------- //
// ----------------------------------------------------------------------------------- //
// ... MongoDB processing will go here.
// ----------------------------------------------------------------------------------- //
// ----------------------------------------------------------------------------------- //
// ----------------------------------------------------------------------------------- //
// I return an array of IDs plucked from the given batch of documents.
function pluckIds( batch ) {
var ids = batch.map(
function operator( item ) {
return( item.id );
}
);
return( ids );
}
// I write a document to a mock-MongoDB connection.
function writeToMongo( data ) {
var promise = new Promise(
function( resolve, reject ) {
setTimeout( resolve, 50 );
}
);
return( promise );
}
First, let's quickly look at the way I was consuming this data with a transform stream. As I said in my previous post, if you squint hard enough, you can think about a MongoDB operation as "transforming" raw data into MongoDB results:
// Now that we're pulling batches of items out of the ndjson stream, we're going to
// persist them to a mocked-out MongoDB database. However, since MongoDB writes are
// asynchronous, we want to wait until MongoDB returns before we move onto the next
// batch of documents. This way, we don't instantly pull all the ndjson content into
// memory and try to spawn an enormous number of connections to MongoDB.
var databaseStream = batchingStream.pipe(
through2.obj(
function handleWrite( batch, encoding, done ) {
console.log( chalk.gray( "Batch being processed:", pluckIds( batch ) ) );
// Write to the mock MongoDB connection.
var promises = batch.map(
function operator( item ) {
return( writeToMongo( item ) );
}
);
// Wait until all the MongoDB results come back for this batch of
// documents before we tell the through stream that we've processed the
// current read. This should create back-pressure that prevents the
// ndjson from aggressively reading data into memory.
Promise
.all( promises )
.then(
function handleResolve( results ) {
done( null, results );
},
function handleError( error ) {
done( error );
}
)
;
}
)
);
// Since our database stream is still a THROUGH stream, it will buffer results and
// exert back-pressure. In order to make sure data continues to flow, we need to attach
// a "data" handler, to put the through stream into FLOWING mode.
databaseStream.on(
"data",
function( results ) {
console.log( chalk.dim.italic( "Batch completed." ) );
}
);
I thought this was an elegant solution because it used the existing mechanics of the Transform stream to manage the back-pressure needed during the asynchronous MongoDB operation. But, as you can see at the bottom, since the Transform stream is still just a Stream, we have to attach a "data" event handler in order to put the Transform stream into "flowing" mode.
NOTE: I could have just called .resume() on the Transform stream in order to put it into flowing mode; but, I decided to put the console-logging in the "data" event handler rather than in the Promise resolution handler.
Ok, now let's take a look at the use of the "readable" event. By default, Transform streams start out in "paused" mode; but, that doesn't mean they are completely inactive. Even in paused mode, a Transform stream will fill up its internal Write and Read buffers with data; it's just that when "paused", it will stop processing data once the buffers are full. By attaching a "readable" event handler to a Transform stream, we can be told when buffer data is available for consumption. We can then explicitly read data from the Transform stream to access that buffered data.
The tricky part here is that the moment we read data from the Read buffer, the Transform stream may start processing more data in order to fill the void create by our read operation. This may then cause another "readable" event to be fired right-away. Since we're going to be processing an asynchronous MongoDB operation, we want to suppress subsequent "readable" events until the previous "readable" event has been processed. To do this, we have to detach the "readable" event handler while the MongoDB operation is pending. Luckily, the Stream class exposes a .once() method which will do this very thing for us:
// ... to do this, we're going to listen for the READABLE event, and then only read data
// out when MongoDB is not processing an operation. In order to ensure that each .read()
// doesn't immediately put the readable stream back into a READABLE state, we're going
// to attach the event-handler using .once(); this way, it will unbind itself after
// every readable event, allowing us to take explicit control over the flow of data
// (only re-attaching the READABLE event handler when we're ready to consume more data).
batchingStream.once(
"readable",
function handleReadable() {
var batch = this.read();
// If the .read() event returned a NULL, then it means there is no data available
// in the READ BUFFER. As such, we have to wait for data to become available.
// Let's re-attach the READABLE event handler to be alerted when data becomes
// available again and we can trying .read() again.
if ( ! batch ) {
return( batchingStream.once( "readable", handleReadable ) );
}
console.log( chalk.gray( chalk.bold( "[READABLE]" ), "Batch being processed:", pluckIds( batch ) ) );
// Write to the mock MongoDB connection.
var promises = batch.map(
function operator( item ) {
return( writeToMongo( item ) );
}
);
// When the READBLE event is fired, there is likely to be more data in the read
// buffer then can be consumed in a single .read() call. As such, we are going
// to call the event handler recursively until the .read() method no longer
// returns data. However, we still want to wait until the MongoDB results come
// back for this batch of documents before we go back and try to read more data.
// --
// NOTE: This lazy evaluation of the readable data should create back-pressure
// that prevents the ndjson stream from aggressively reading data into memory.
Promise
.all( promises )
.then(
function handleResolve( results ) {
console.log( chalk.dim.italic( "Batch completed." ) );
}
)
.catch(
function handleError( error ) {
// ... nothing will error in this demo.
console.log( chalk.red( "ERROR" ), error );
}
)
.then(
function handleDone() {
// When the Promise is fulfilled (either in resolution or rejection),
// let's try to recursively call the handler to read more data.
// --
// NOTE: We're invoking the handler in the context of the readable
// stream because the EventEmitter (base class for Streams) always
// invokes its handlers in the context of the EventEmitter sub-class.
handleReadable.call( batchingStream );
}
)
;
}
);
The other complexity with this approach is that a "readable" event may allow for multiple read operations, which is why we are invoking the handleReadable() event handler recursively from within the MongoDB operation resolution. That said, when we run this code, we can see from the terminal output that we are properly exerting back-pressure to the upstream sources:
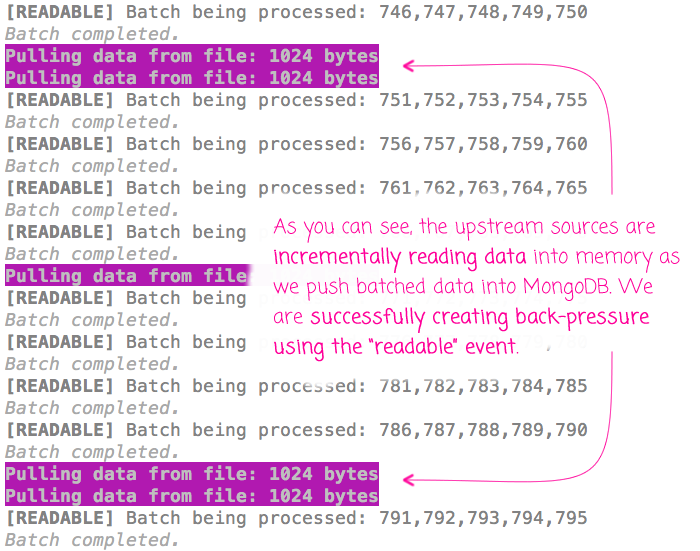
As you can see, by using the "readable" event and the .read() operation, we are able to manage the back-pressure up through the chain of Streams.
Now, let's look at using the "data" event. The "data" event emits data being made available from the source stream. So, unlike the "readable" event, we don't have to explicitly read data once our event-handler has been invoked - the readable data is part of the emitted event. But, unlike attaching the "readable" event handler, the source stream will be put into "flowing" mode the moment we attach the "data" event handler. This means that the source stream will start emitting data as fast as it can, regardless of how we consume that data.
For backwards compatibility reasons, Node.js doesn't automatically put a stream back into "paused" mode if you remove the "data" event listener. As such, we can't use the same .once() hack we used above. Instead, we have to explicitly call .pause() on the source stream while we are processing the "data" event. This will prevent subsequent "data" events from being emitted until we explicitly call .resume() on the stream. While paused, the source stream should exert back-pressure, preventing upstream sources from reading data into memory too aggressively:
// ... to do this, we're going to listen for the DATA event. Unlike the READABLE event,
// attaching the DATA event handler puts the source stream into "flowing" mode, which
// means that data is going to be emitted from the source stream until the source stream
// is explicitly paused. Since we only want to handle data when MongoDB is not processing
// an operation, we have to pause the stream during processing and then resume it once
// the processing as completed.
// --
// NOTE: Unlike with the READABLE event, we can't use the .once() hack for DATA. For
// backwards compatibility reasons (with older version of Node.js), removing the "data"
// event handler will not automatically pause the stream.
batchingStream.on(
"data",
function handleData( batch ) {
// Pause the source stream while we're processing this batch of items. This
// should create back-pressure that prevents the ndjson stream from aggressively
// reading data into memory.
batchingStream.pause();
console.log( chalk.gray( chalk.bold( "[DATA]" ), "Batch being processed:", pluckIds( batch ) ) );
// Write to the mock MongoDB connection.
var promises = batch.map(
function operator( item ) {
return( writeToMongo( item ) );
}
);
// Wait until the MongoDB results come back before we try to read more data.
Promise
.all( promises )
.then(
function handleResolve( results ) {
console.log( chalk.dim.italic( "Batch completed." ) );
}
)
.catch(
function handleError( error ) {
// ... nothing errors in this demo.
console.log( chalk.red( "ERROR" ), error );
}
)
.then(
function handleDone() {
// When the Promise is fulfilled (either in resolution or rejection),
// let's put the source stream back into "flowing" mode so that it
// will start emitting DATA events again.
batchingStream.resume();
}
)
;
}
);
As you can see, this code is a bit more straightforward. No explicit reads; no recursively invoked event handlers. And, when we run the above code through Node.js, we get the following terminal output:
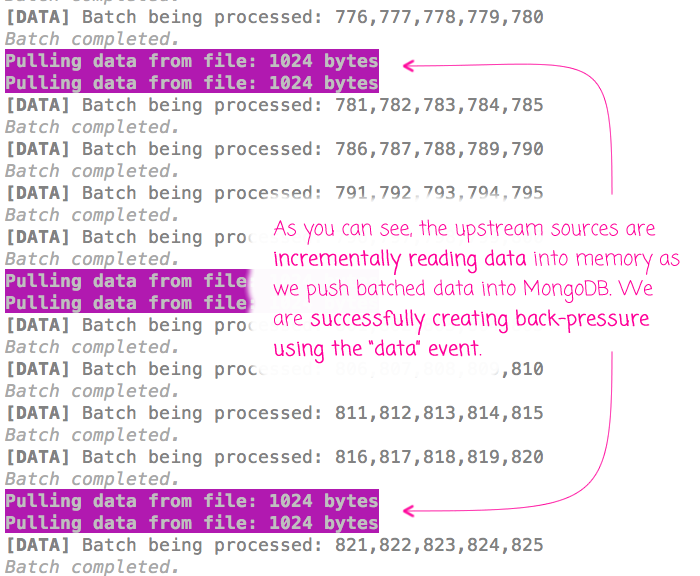
As you can see, by using the "data" event and the .pause() and .resume() operations, we are able to manage the back-pressure up through the chain of Streams.
I don't think any one of these approaches is necessarily right or wrong. I think each approach has its pros and cons and will depend on the context and how you intent to consume the results of the asynchronous operation that you're performing during Stream consumption. I still think the use of the Transform stream is an elegant approach because there's no explicit back-pressure management; but, using the "data" event may require the smallest Stream mental model. In every case, however, the key point is that we are managing back-pressure during an asynchronous operation so that our Streams don't run out of control.
Want to use code from this post? Check out the license.

Reader Comments
Awesome solution ... Any suggestions on how to use Node to parse an HTTP RESTful API request that returns a readable stream of binary data (not json formatted, variable length messages)?
Caveats:
1. The API returns a server response with status codes and header: Acccept-range: bytes
2. Actual streaming data/messages may not be available and/or sent immediately.
3. The Stream is continuous (as in: it streams until a "Logout" request is sent) which means there's no "Content=length" or EOF marker.
I think a "through stream" approach will also work here but I can't get the HTTP request (NODE request module) to pause/wait for the streamed data after the original server response is received.
Thanks and as always, Great Work
STC
ps. I have a perl solution but it's so SLOW and can't keep up with streaming server.