
Using Transform Streams To Manage Backpressure For Asynchronous Tasks In Node.js
The other day, I looked at using the Newline-Delimited JSON (ndjson) standard for storing large amounts of data in flat files. The ndjson approach works well because it limits the amount of data that the Node.js process has to parse or serialize at any one time (which prevents memory exhaustion). But, if you want to pipe an ndjson stream into another asynchronous operation, such as a database insertion, you can quickly find yourself reading too much data into memory. To get ndjson streams to play well with asynchronous operations, I've been experimenting with Transform streams as a means to manage backpressure, which keeps the ndjson stream from running out of control.
If you have an ndjson stream (or any Readable stream), attaching a "data" listener to the stream:
readableStream.on( "data", handler );
... will put the readable stream into "flowing" mode, which means that it will start emitting data events as fast as they can be produced by the underlying source. Unfortunately, if you're trying to take that data and insert it into a MongoDB database, for instance, the "data" handler has no way of telling the upstream source to pause while the MongoDB operation is executing. As such, you can quickly overwhelm your MongoDB connection pool and command queue as well as consume an inappropriately large amount of process memory.
To get around this, you can start trying to attach and detach "data" handlers in order to move the readable stream back and forth between "flowing" and "paused" mode. Or, you can try to manually control the stream using the .resume() and .pause() methods; but, then you have to worry about listening to the "readable" event and dealing with multiple reads per "readable" event.
Doing it manually is messy. That's the beauty of the .pipe() method and the reason that the Node.js documentation suggests using .pipe() whenever possible. Now, you can't pipe a stream into MongoDB; but, if you squint hard enough, you can .pipe() a stream into a Transform stream that "transforms" documents into "MongoDB results".
If we can shift our mental model to think about MongoDB operations as data transformations, then we can use the .pipe() method, which means we get all of the automatic backpressure goodness provided by the Node.js stream implementation:
through2.obj(
function handleWrite( document, encoding, done ) {
var promise = storeInMongoDB( document );
// Since this is a "transform" stream (using through2), we can't push data onto
// the WRITE BUFFER until the MongoDB operation has returned. Therefore, by using
// the MongoDB promise as means to delay pushing data, we can get the underlying
// stream implementation to exert backpressure on the upstream source. This
// allows the two different asynchronous constructs - Streams and Promises - to
// dovetail quite nicely.
promise.then(
function handleResolve( result ) {
done( null, result );
},
function handleError( error ) {
done( error );
}
);
}
)
By using a Transform stream (using through2 in this case), we can leverage the native backpressure mechanism while waiting for our asynchronous MongoDB operations (in this case) to resolve.
To see this in action, I put together a demo in which we read-in an ndjson file and pipe it into a Transform stream that is writing to a mock MongoDB database. Of course, just doing that doesn't actually shed light on the flow of data. As such, I've added a through2 stream in between the file-input stream and the ndjson parser so that we can log actual data reads to the terminal. This way, we can clearly see that backpressure prevents the entire ndjson file from being pulled into memory.
And, because playing with Node.js streams is "fun", I've also added another Transform stream that batches the ndjson items into small collections that can be processed by the MongoDB database in parallel. This is just an attempt to add a little more real-world flare to the exercise.
NOTE: You could just use .insertMany() on a real MongoDB database to handle multiple documents; but, this detail was less about data access practices and more about Node.js streams and backpressure.
In the following code, I am explicitly setting many of the highWaterMark stream properties so as to lower the amount of data that can be buffered into the stream memory. This way, I can make the backpressure effects of the demo more visible without working on a massively large dataset.
// Require the core node modules.
var chalk = require( "chalk" );
var fileSystem = require( "fs" );
var ndjson = require( "ndjson" );
var through2 = require( "through2" );
// ----------------------------------------------------------------------------------- //
// ----------------------------------------------------------------------------------- //
// *********************************************************************************** //
// CAUTION: In the following code, I am manually setting many of the highWaterMark
// properties on the various streams in an attempt to make the console-logging more
// human-consumable and meaningful.
// *********************************************************************************** //
// The ndjson stream will pull data out of the input stream (file), split it on the
// newline character, deserialize each line as a separate JSON (JavaScript Object
// Notation) document, and then emit the native JavaScript value as a data item.
var inputStream = fileSystem.createReadStream(
( __dirname + "/data.ndjson" ),
// The default highWaterMark for a fs read-stream is 64KB (not the normal 16KB
// default of the core Readable stream). In order to not buffer too much memory at
// once -- FOR THE SAKE OF THE DEMO -- we're going to limit the buffer to 1KB.
{
highWaterMark: ( 1 * 1024 )
}
);
// There's a good chance that we're using the ndjson storage format because we're
// dealing with a massive amount of data and attempting to treat the data as a single
// object would become untenable. As such, we want to make sure that we don't read all
// of the data into memory at the same time or we run the risk of running out of memory.
// To see how data flows out of the ndjson stream, let's create a simple through stream
// that logs through-traffic to the console. This way, we can see how fast data is
// being pulled out of the data file and into memory for parsing.
var doStream = inputStream.pipe(
through2(
// Let's use the same buffer size as the read-stream so that our monitoring
// stream doesn't accidentally suck too much data into memory. Since a through
// stream has both a WRITE and a READ buffer, having a 1024 byte buffer size
// will actually allow ( 2 * 1024 ) bytes to be pulled out of the file (I think).
{
highWaterMark: ( 1 * 1024 )
},
function handleWrite( chunk, encoding, done ) {
console.log( chalk.bgMagenta.white.bold( "Pulling data from file:", chunk.length, "bytes" ) );
this.push( chunk, encoding );
done();
}
)
);
// Pipe the input file into the ndjson stream.
// --
// NOTE: By default, the ndjson stream uses a 16K (16,384) buffer size for the WRITE
// buffer. However, since the highWaterMark affects both the WRITE buffer and the READ
// buffer, this actually allows the ndjson stream to buffer 16K OBJECTS IN MEMORY in the
// READ buffer. FOR THE SAKE OF THE DEMO, we're going to lower this to prevent so much
// data form being buffered.
var transformStream = doStream.pipe(
ndjson.parse({
highWaterMark: 10 // Bytes for WRITE buffer, Objects for READ buffer.
})
);
// As objects come out of the ndjson stream, deserialized back into native JavaScript
// objects, we want to persist them into a local (mocked out) MongoDB store. However,
// we have a limited number of connections available (and only so many connections that
// can even be queued). As such, we're going to process the items in batches of 5. This
// through stream will buffer the deserialized items, and then pass-through an array of
// 5-items when it becomes available.
var batchingStream = (function batchObjectsIntoGroupsOf5( source ) {
var batchSize = 5;
var batchBuffer = [];
var batchingStream = source.pipe(
through2.obj(
function handleWrite( item, encoding, done ) {
batchBuffer.push( item );
// If our batch buffer has reached the desired size, push the batched
// items onto the READ buffer of the transform stream.
if ( batchBuffer.length >= batchSize ) {
this.push( batchBuffer );
// Reset for next batch aggregation.
batchBuffer = [];
}
done();
},
function handleFlush( done ) {
// It's possible that the last few items were not sufficient (in count)
// to fill-out an entire batch. As such, if there are any straggling
// items, push them out as the last batch.
if ( batchBuffer.length ) {
this.push( batchBuffer );
}
done();
}
)
);
return( batchingStream );
})( transformStream );
// Now that we're pulling batches of items out of the ndjson stream, we're going to
// persist them to a mocked-out MongoDB database. However, since MongoDB writes are
// asynchronous, we want to wait until MongoDB returns before we move onto the next
// batch of documents. This way, we don't instantly pull all the ndjson content into
// memory and try to spawn an enormous number of connections to MongoDB.
// --
// NOTE: The default highWaterMark for streams in Object mode is 16 objects.
var databaseStream = batchingStream.pipe(
through2(
{
objectMode: true,
highWaterMark: 10 // Buffer a few batches at a time.
},
function handleWrite( batch, encoding, done ) {
console.log( chalk.gray( "Batch being processed:", pluckIds( batch ) ) );
// Write to the mock MongoDB connection.
var promises = batch.map(
function operator( item ) {
return( writeToMongo( item ) );
}
);
// Wait until all the MongoDB results come back for this batch of
// documents before we tell the through stream that we've processed the
// current read. This should create back-pressure that prevents the
// ndjson from aggressively reading data into memory.
Promise
.all( promises )
.then(
function handleResolve( results ) {
done( null, results );
},
function handleError( error ) {
done( error );
}
)
;
}
)
);
// Since our database stream is still a THROUGH stream, it will buffer results and
// exert back-pressure. In order to make sure data continues to flow, we need to attach
// a "data" handler, to put the through stream into FLOWING mode.
databaseStream.on(
"data",
function( results ) {
console.log( chalk.dim.italic( "Batch completed." ) );
}
);
// ----------------------------------------------------------------------------------- //
// ----------------------------------------------------------------------------------- //
// I return an array of IDs plucked from the given batch of documents.
function pluckIds( batch ) {
var ids = batch.map(
function operator( item ) {
return( item.id );
}
);
return( ids );
}
// I write a document to a mock-MongoDB connection.
function writeToMongo( data ) {
var promise = new Promise(
function( resolve, reject ) {
setTimeout( resolve, 50 );
}
);
return( promise );
}
As you can see, we're logging when data comes out of the read-file (and into the ndjson parser), when the MongoDB "transform" stream starts working on a batch of documents, and finally, when the results of a batch have completed. And, when we run this code through Node.js, we get the following terminal output:
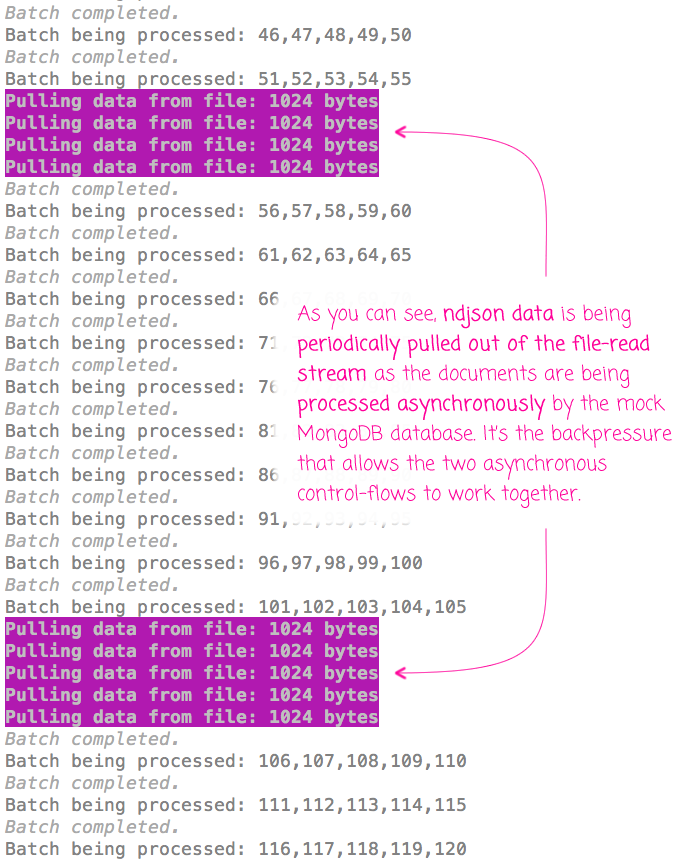
As you can see, ndjson data is being incrementally read into memory as the MongoDB transform stream has a chance to process it. And, while you can't see this from the screenshot, watching the terminal output (see the video above) makes it clear that the MongoDB transform stream is exerting backpressure which is preventing the ndjson stream from aggressively reading data into the V8 process.
Node.js streams are powerful, but complicated. Not only do you have to worry about how a stream is operating, you also have to be cognizant of how downstream consumers of a stream are behaving. Trying to manually manage a stream's mode (flowing vs. paused) can be tedious and complicated. But, if you can use a Transform stream (such as through2), you can leverage the native .pipe() method to encapsulate many of the complexities surrounding stream consumption. This makes it much easier to connect a Node.js stream to other asynchronous operations like database commands.
Want to use code from this post? Check out the license.

Reader Comments
Very elegant solution. I had to deal with large amounts (10s of GB) ndjson data recently. The data came from elasticsearch and had to be inserted into mongodb.
I ended up with Node's readline - interface. On each 'line' event, I paused the stream, parsed the JSON, transform some of the data, upsert into mongodb, wait for promise to fulfill or fail, log if something went wrong, resume the stream and repeat.
@Bastibeckr,
It can get kind of funky, right? I'd like to re-explore this topic, trying some of the alternate approaches. The first time I tried it, I was using the "readable" event and then trying to use the .read() method to pull back data. But, I was running into a situation where the .read() method was returning more than one data item, which meant I had to deal with processing those in serial, and making sure that subsequent "readable" events weren't triggering as well.
@Ben,
This was my first contact to ndjson and googled "node read huge file line by line". I knew I would run into memory issues if I try to parse all the data at once. And if I would use standard JSON-arrays, one parse error would destroy the whole file.
I like the concept of one-object-per-line. If there is an parsing error in one object, it's no problem. I write the line in question to a log file and correct the error manually.
Here is my first approach: https://gist.github.com/bastibeckr/e1e4c035dbeb5fb3ff031d0f269cc971
@All,
After posting this, I thought it would be worthwhile (if only for myself) to go back and compare this use of Transform streams to the use of the "readable" and "data" events for managing back-pressure:
www.bennadel.com/blog/3237-managing-stream-back-pressure-during-asynchronous-tasks-using-readable-and-data-events-in-node-js.htm
... all three approaches can be used to accomplish the same thing. But, each has their benefits and drawbacks and will likely depend on how you want to consume the data.
@Bastibeckr,
That's interesting - I am not sure that I even knew there was a "readline" module in Node :) That said, I was looking at how some of the JSON streams were implemented and it looks like one of them (I think ndjson) uses something called "split2" under the hood. The split2 module does something similar - it will buffer a stream and then emit that stream split on a given pattern, which defaults to "\r\n". So, it's essentially splitting the source stream on the newline, which is what I assume "readline" is also doing.
In node, it seems there's a hundred and one ways (and modules) to do the same thing... is that a pro or a con :P
Thank you for posting an approachable example explaining Node stream usage for the purpose of seeding database tables. I took your example and ported it to take CSV files into Postgresql via Loopback. I had written a prior implementation that worked (sort of) but whenever one table depended on another table (i.e. initializing foreign keys) I had to run the script multiple times because I could never deterministically know when a prior operation had finished. My attempts to block within a stream transform just blew up my stream or ran my process out of memory. Now, it works perfectly and is much more elegant. I am out of the mire and back on the road to solving seemingly more important problems of actually implementing the business logic for my app. Thank you for helping me get past a hard spot!
Hi Ben. Thanks for the post! I was wondering, is the `data` event really necessary? You mention: "Since our database stream is still a THROUGH stream, it will buffer results and exert back-pressure. In order to make sure data continues to flow, we need to attach "data" handler, to put the through stream into FLOWING mode."
But, when reading the it says:
"All Readable streams begin in paused mode but can be switched to flowing mode in one of the following ways:
Adding a 'data' event handler.
Calling the stream.resume() method.
Calling the stream.pipe() method to send the data to a Writable."
Aren't you doing #3 here with the pipe? Wouldn't that make it redundant to also attach the listener?
@Adam,
Correct, for all of the intermediary streams. However, I'm adding a "data" event handler to the last stream in the chain. The .pipe() takes care of moving data from one stream to another. But, the final databaseStream isn't being piped into anything. As such, it has nowhere to "write" the data, which will cause it to buffer and exert back-pressure. As such, at the very end of all the chains, I need to attach the "data" event handler to allow the chained streams to actually drain somewhere.
@Jubilee-Scott,
That's awesome!! Glad this was helpful, that pleases me greatly :D
Thanks so much for this article. I'm a long time Java developer so new to Node js and am spending time learning about streams. Your approach was tremendously helpful to pointing me in the right direction, reading ndjson from a request stream and sending it to Mongo. I structured mine a little differently but the basic approach is following your example. Works pretty well as far as I can tell!