
ColdFusion Rollout For Feature Flag Based Deployment
For the last few months, I've been doing a deep dive on Angular 2 Beta. But, I needed a little break - a mental refresher, if you will. I wanted to do something with Redis (which I'm totally in love with these days). But, I wasn't exactly sure what to do. After some Googling, I came across a Ruby feature flag library called Rollout that used Redis as a persistence mechanism. Since we use LaunchDarkly at work for our feature flags, I thought this would be a great opportunity to think more deeply about both Redis and feature flags. So, I [loosely] ported the Ruby Rollout feature flag deployment library over to ColdFusion.
View my ColdFusion Rollout project on GitHub.
In general, feature flags help you deploy new features gradually using percentages, groups, and user identifiers. On the flip-side, feature flags are also a convenient way to quickly roll a feature back when things go horrible wrong (for shame!!). But, perhaps even more exciting than both of those benefits, feature flags help your engineering teams move away from long-running "feature branches" [in git] by allowing code to be continually merged into your integration branch without it actually being exposed to your users. This reduces merge conflicts, helps prevent bugs, and keeps your engineers on the same page.
My ColdFusion version of Rollout is heavily inspired by the Ruby Rollout library, but with my own personal take on naming and organization. Internally, my version of Rollout is optimized for bulk reads. All of the data is stored in a single value which contains all of the feature configurations. I chose this approach for my internal architecture because I'd rather go over the wire fewer times and pull back more data on each request. This also keeps the storage API simple to implement and easy to swap out.
Bulk reads also align well with what I consider to be the primary gesture of feature flag consumption: configuring user permissions at the start of an incoming request (and then using that configuration throughout the request and subsequent response rendering). While per-feature storage makes sense if you intend to consume one feature at a time, I almost always want to know how all features apply to the requesting user. By using a bulk read, I can get all that data with a single request to the storage mechanism.
For this, I see the primary method in ColdFusion Rollout as being:
- getFeatureStatesForUser( userIdentifier [, groups ] )
This takes the user identifier (and an optional set of groups) and returns a struct in which each key represents a feature and each value indicates whether or not that feature is enabled for the given user. I imagine making this call during request authentication and then making the result available throughout the request processing.
The optional groups collection can be an array, in which each value is a group in which the given user is a member:
<cfscript>
var features = rollout.getFeatureStatesForUser(
user.id,
[ "employee", "admin" ]
);
// ...
if ( features.canSeeSecretPortal ) {
// ....
}
</cfscript>
Or, the groups collection can be a struct in which each key is a group name and each value indicates whether or not the user is a member of that group. This allows you to easily calculate group membership as part of the method call without having to precompile the "right" list of group memberships:
<cfscript>
var features = rollout.getFeatureStatesForUser(
user.id,
{
employee: isEmployee( user ),
admin: isAdmin( user )
}
);
// ...
if ( features.canSeeSecretPortal ) {
// ....
}
</cfscript>
Of course, features don't have to be tied to a specific user - they can just be turned "on" or "off" as a matter of fact. Or, they can be toggled for a specific group of people (like internal employees or beta testers). At this time, these are the methods that can enable features in ColdFusion rollout:
- ensureFeature( featureName ) - Ensures that a feature exists, and defaults it to off if it doesn't exist.
- activateFeature( featureName ) - Sets the feature activation to 100% rollout, effectively enabling it for everyone.
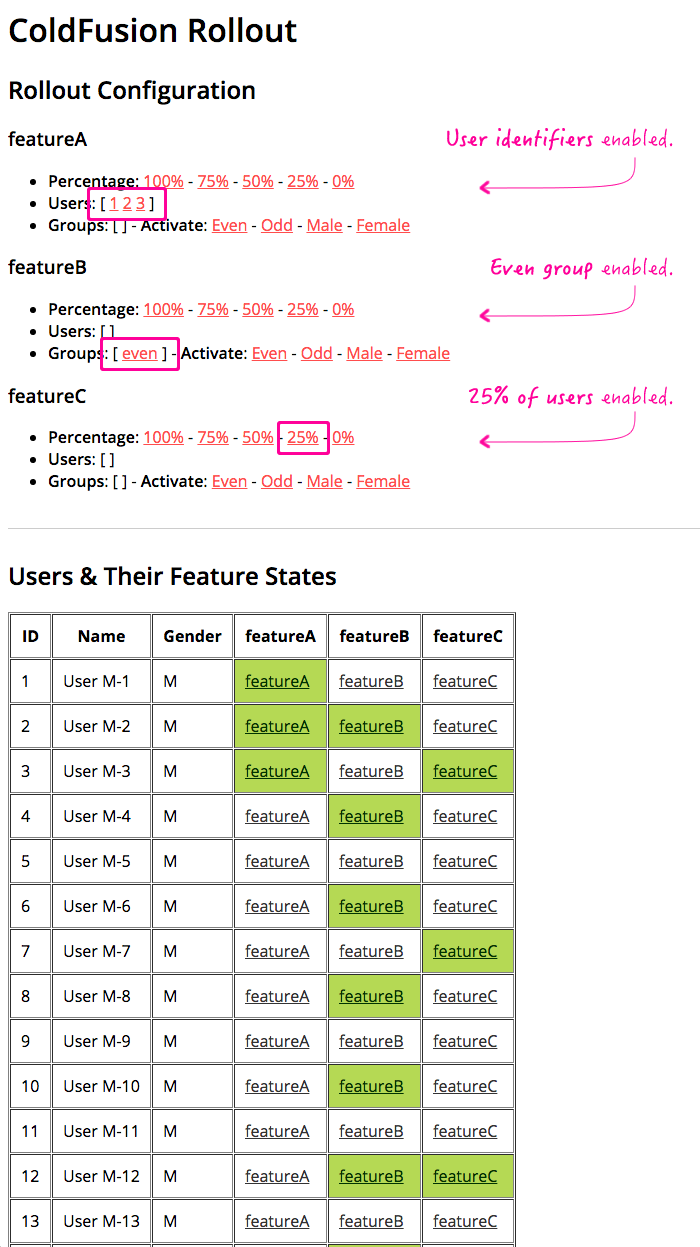
- activateFeatureForPercentage( featureName, percentage ) - Sets the feature activation to the given percent (which is consistently mapped to user identifiers [using the Adler-32 checksum algorithm](using the Adler-32 checksum algorithm)).
- activateFeatureForGroup( featureName, groupName ) - Enables the feature for all users associated with the given group.
- activateFeatureForUser( featureName, userIdentifier ) - Enables the feature for the given user.
- activateFeatureForUsers( featureName, userIdentifiers ) - Enables the feature for the given set of users.
Percentage-based rollouts act independently of user identifiers and groups. This doesn't do complex targeting like LaunchDarkly does. If you activate a feature for a given user, it will still be active for that user even if the feature is being rolled-out to 0% of user-base. The same is true for features enabled for a given group.
Ultimately, I got onto this project because I wanted to play around with Redis. In the end, however, Redis became little more than a footnote - an implementer of the Storage API. Right now, the project ships with an in-memory storage adapter (for testing) and a Jedis storage adapter:
<cfscript>
// Use the in-memory store.
var storage = new lib.storage.InMemoryStorage();
var rollout = new lib.Rollout( storage );
// Or, use the Jedis / Redis store.
var jedisPoolConfig = createObject( "java", "redis.clients.jedis.JedisPoolConfig" ).init();
var jedisPool = createObject( "java", "redis.clients.jedis.JedisPool" ).init( jedisPoolConfig, javaCast( "string", "localhost" ) );
var storage = new lib.storage.JedisStorage( jedisPool, "demo:features" );
var rollout = new lib.Rollout( storage );
</cfscript>
Check out the video above - I tried to include a working demo that showcases a number of the features:
I'm relatively new to the concept of feature flags. While I've known about them for a while (from various podcasts and conversations), LaunchDarkly was my first actual hands-on experience. ColdFusion Rollout doesn't have nearly the feature-set that LaunchDarkly has; but, this was a lot of fun to think about. It really gave me pause and forced me to think deeply about how feature flags can be defined and how they can be consumed. Much fun! Such wow!
Want to use code from this post? Check out the license.

Reader Comments
@Ben
How do you handle feature persistence where percentage-based distribution is used? In other words, how do you ensure the same 25% get Feature A every time they visit the site? If you move Feature A from 25% distributed to 75% distributed, how do you ensure the initial 25% continue to receive Feature A and that the only impact is that you're adding another 50% to the original distribution?
@Chris,
Under the hood, the "user identifier" is being mapped onto a percentage using a checksum calculation. In this case, I'm using the Adler32 algorithm (provided by Java) to generate a percentage like this (more or less):
return( getChecksum( userIdentifier & salt ) % 100 )
In this case, the "Salt" is a feature name. So, if I was checking to see if user 1234 was getting feature "CanDelete", it would be:
return( getChecksum( 1234 & "CanDelete" ) % 100 )
So, its just some sort of bit-based math under the hood (I don't really understand the specifics of the checksum). But, the point is, it is consistent. You always give it the same ID and the same Salt and it will always give you same percentage.
Then, I just need to compare a user's generated percentage to the rollout percentage, like:
var hasFeature = ( getBucket( 1234, "CanDelete" ) <= 75% )
So, to your question, when I increase from 25% to 50% to 75%, it keeps all the existing users in the earlier percentage because the same inputs are always uses. Meaning, going from 25% to 26% is really:
> All the people who were covered by 25% PLUS all users whose bucket is "26".
Now, this all depends on being able to consistently identify a user with a given ID / identifier. If the user logs into the app, no problem, that's just their user / account ID. But, if these are non-logged-in users, then I guess you would have to generate some Cookie value and use that as the identifier.
@Ben
Thanks for the brilliant and insightful answer. That's a very clever solution!
@Chris,
My pleasure! And just to give credit where credit's due - this is *basically* how it's done in the Ruby Rollout library; so I didn't break any new ground. The only real difference is that I am using the Feature Name as a "salt" to add some variety based on a fixed user population but a dynamic feature set.