
Creating Web Controls With ColdFusion Custom Tags
A while back, I watched John Farrar presenting his COOP Framework on UGTV. It's an interesting framework. One of the things that got me thinking was the way he creates .NET-like web controls using ColdFusion custom tags. His web controls were fairly high-level; they did things like accept a query and text/value columns and rendered an HTML Select box. This is a cool concept, but I wonder if it is almost too high level. I have been tossing around the idea of creating ColdFusion custom tag based web controls, but I was thinking about something a bit more low level. The problem with high level controls is that, while they are very easy to use, you lose hooks into the rendering. With a more low level approach, you can gain the benefits of centralized rendering, but also allow the programmer / front-end developer to more custom mold the data that get's displayed (such as formatting dates, numbers, and combining data columns (first_name + last_name = full_name).
It's hard to come up with a great example of where I would want to do something like this, but let's just look at a data list for the sake of starting a conversation. Let's say we are building a King of the Hill fan site and we want to list out some memorable Hank Hill quotes next to the episodes that they came from. We could easily put that into an HTML definition list:
<dl>
<dt>
"And They Call It Bobby Love"
</dt>
<dd>
Bobby, I know it's not good when a girl breaks
your heart. It's only natural to be sad. But the
couch is a happy place.
</dd>
<dt>
"Luanne's Saga"
</dt>
<dd>
I did what you couldn't do. Now, I'm not saying you're
not good at what you do, I'm just saying I'm better. I
went in there and fixed her, like fixing a carburetor.
And you know what? It was fun. Like fixing a carburetor.
</dd>
<dt>
"Father of the Bribe"
</dt>
<dd>
C. C plus. Two B minues. You really did it, son. You
set realistic goals and you reached them. Way to go.
</dd>
</dl>
That would work just fine. However, this completely locks us into that style of data listing. But, what if we took that definition list and, instead of using DL tags, we wrapped it in a ColdFusion custom tag, datalist.cfm:
<!--- Import graphical user interface tags. --->
<cfimport taglib="./" prefix="gui" />
<!--- Output data list. --->
<gui:datalist>
<dt>
"And They Call It Bobby Love"
</dt>
<dd>
Bobby, I know it's not good when a girl breaks
your heart. It's only natural to be sad. But the
couch is a happy place.
</dd>
<dt>
"Luanne's Saga"
</dt>
<dd>
I did what you couldn't do. Now, I'm not saying you're
not good at what you do, I'm just saying I'm better. I
went in there and fixed her, like fixing a carburetor.
And you know what? It was fun. Like fixing a carburetor.
</dd>
<dt>
"Father of the Bribe"
</dt>
<dd>
C. C plus. Two B minues. You really did it, son. You
set realistic goals and you reached them. Way to go.
</dd>
</gui:datalist>
Notice that the content of the tag has not changed at all, other than the fact that the DL tag has been replaced with a gui:datalist ColdFusion custom tag. But, if you look at the custom tag, you will see that it is merely wrapping the tag content in HTML DL tags to achieve the same result:
<!---
Check to see if we are in the end of the tag execution.
We only care at end once the tag content has been generated.
--->
<cfif (THISTAG.ExecutionMode EQ "End")>
<!--- Get the generated tag content. --->
<cfset VARIABLES.Content = THISTAG.GeneratedContent />
<!--- Format the new content. --->
<cfsavecontent variable="VARIABLES.NewContent">
<cfoutput>
<dl>
#VARIABLES.Content#
</dl>
</cfoutput>
</cfsavecontent>
<!---
Store the formatted content back into the tag to create
the display data.
--->
<cfset THISTAG.GeneratedContent = VARIABLES.NewContent />
</cfif>
Running the page with this new ColdFusion custom tag, you can see that will are still getting our definition list output:
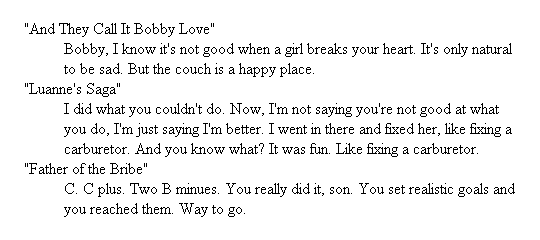
This is a really minor change, but it has a HUGE impact on how flexible our web site is; this has, essentially, taken our definition list and changed it from semantic HTML to pure data storage. This means nothing to us if we want to stick with the definition list, but imagine if someone came in and decided that definition lists were too hard to style across all browsers and that we needed to switch over to tables which are much more cross-browser and archaic browser compatible. If we had straight HTML then this would be an enormous effort to put into effect. However, since our ColdFusion custom tag wrapper gives us a centralized point of rendering, we can easily swap out the logic of the datalist.cfm ColdFusion custom tag to change the data list rendering across the site:
<!---
Check to see if we are in the end of the tag execution.
We only care at end once the tag content has been generated.
--->
<cfif (THISTAG.ExecutionMode EQ "End")>
<!--- Get the generated tag content. --->
<cfset VARIABLES.Content = THISTAG.GeneratedContent />
<!--- Create the XSLT transformation code. --->
<cfsavecontent variable="VARIABLES.XSLT">
<?xml version="1.0" encoding="ISO-8859-1"?>
<xsl:transform
version="1.0"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<!--- Match the root template. --->
<xsl:template match="dl">
<table border="1" cellpadding="4">
<col width="25%" />
<col width="75%" />
<tbody>
<!--- Loop over all the data terms. --->
<xsl:for-each select="dt">
<tr valign="top">
<td>
<!--- Output term. --->
<xsl:value-of select="." />
</td>
<td>
<!--- Output definition. --->
<xsl:value-of
select="following-sibling::dd[ position() = 1 ]"
/>
</td>
</tr>
</xsl:for-each>
</tbody>
</table>
</xsl:template>
</xsl:transform>
</cfsavecontent>
<!--- Format the new content. --->
<cfset VARIABLES.NewContent = XmlTransform(
("<dl>" & VARIABLES.Content & "</dl>"),
Trim( VARIABLES.XSLT )
) />
<!---
Store the formatted content back into the tag to create
the display data.
--->
<cfset THISTAG.GeneratedContent = VARIABLES.NewContent />
</cfif>
Here, rather than just echoing out the definition list, we are taking it, treating it like XML, and transforming it into a table display using XSLT and ColdFusion's XmlTransform() function. Now, having made no changes to the HTML at all, we get this completely different output:

This kind of centralized rendering feels hugely powerful, but I am not sure that I am sold on it. I do like that using ColdFusion custom tags and XSLT forces the front-end developer to write XML-compliant code; this almost forces standards compliance, which is what we should all be shooting for anyway. But, I am not sure that this is useful enough or even a valid case study. In order to really have useful centralized rendering of web controls, you would need to have very consistent interfaces; again, this is probably something that we should be doing anyway (consistent applications are much more pleasing to use), but I wonder if this requirement for consistency almost forces us to remove any creativity.
I know that if we write semantic XHTML, we can use CSS to change a lot of rendering across the sites. But, I just think that CSS has it's limits. What if huge changes need to be made? Any thoughts?
Want to use code from this post? Check out the license.

Reader Comments
Ben..
Usually your examples make quite a lot of sense, but this one fails. For one thing, why go halfway and only replace the OUTER container tag (the dl)? Sure you COULD use XSLT to replace the dt and dd tags with their tabular counterparts but that just seems excessive when you could have just passed in a CSV dataset to begin with.
What are the chances that someone would be up to using a custom tag in this manner, and didn't have their data stored in a db? They could then output it in any manner they chose.
Regarding your original question, I can sort of agree with you on coops high level approach, but only partially. It gives you enough framework-ness that you can use the premade controls provided, but also gives you the power to create your own.
I'm considering using COOP in some personal projects just as a learning experience.
Ben,
That is an interesting approach and certainly shows some benefits to using XHTML-compliant code. I worry, however, what would happen if someone included a <br> (non-closing) in the code.
I probably would have done it like this:
<gui:datalist>
<gui:def term="And They Call It Bobby Love">
Bobby, I know it's not good when a girl breaks
your heart. It's only natural to be sad. But the
couch is a happy place.
</gui:def>
</gui:datalist>
It does require use of the custom tags, but it saves you from the XML parsing (and related risks) and allows you more flexibility (like whether or not to put your term in quotes).
the example you gave is an interesting idea, but I agree that it was not the best execution.
I think a better way, while following elements of your original idea, to convey it would be having the user pass some sort of data element into the custom tag (could a query, and structure, an array, or a separated list).
The tag would take the data and then display it in any html data rendering format, such dl, ul, ol or table.
I think that approach would get the idea across better.
Just my two cents.... I expect change.
Ben, I messed around with something like this a few years ago. I was particularly interested in the idea of polymorphic displays so that you could, for example, send 3 items to a tag (or object) and receive back, say, a series of radio buttons. Send 20 items and you would receive back a drop-down box.
I came to think that, fun though it was to play with it, it was a bit of a solution in search of a problem. But I'd encourage you to continue with your idea: maybe you'll come up with the perfect balance.
I LOVE this out of the box thinking. :-) Needs more time in the oven though. ;-) For R&D purposes, it was well worthwhile. It could spark a better idea down the road.
It could accept a query as an attribute, but then I guess the XML transformation isn't quite as necessary.
@Andy,
I am not sure if I understand what you are saying. I think we have some miscommunication of thoughts. I am not sure what database has to do with this? The same thing would be done whether a "static" html page of a database driven html page. The only difference with the database driven page is that you might have a CFLoop tag building the elements inside of the web control custom tag.
Passing in a CSV value is interesting. My concern with that is that I think it loses readability. Plus, with a CSV, data formatting is even more important. Could be good, but could be causing complications as well.
@Steve,
Having a non-closing BR tag, I believe is non XHTML standards compliant, but not sure off hand. But, this kind of thing does raise a valid point - when you HAVE to have a certain level of validation, your "data in" method has to be extremely well thought out. For example, if you have some FCK editor or something that has even the smallest possible chance of not returning XHTML compliant code, then you have to either scrub data yourself or not use XML quite in this manner (more CDATA escaping would need to be done).
@Tony,
Agreed that this is not the best example, but I was a bit hard pressed to come up with one as right now, these are just thoughts racing round in my head. As far as stopping at just the DL tag, don't think about it this way. If we include the DL tag, then DT and DD are simply HTML tags. However, the second we use the custom tag, DT and DD become XML element nodes - they are no longer HTML elements.
It's not a partial conversion - once you swap the parent, the entire structure / intent of the block of code changes.
@Hal, @Dan,
I knew a guy who told me that he built all his pages in XML and used XSLT to render them. Apparently, this was all done on the fly and I never saw the code, but he said it was wicked fast. He was a PHP programmer, so I am not sure I would have been able to read the code anyway.
While I am not there, I do like the idea of describing the data of the page first and then rendering it based on that description. I like it in theory, anyway - in practice is a whole different story.
I need to give this some more thought time, but I am not done with it yet.
Awesome. That's a really neat way to do it Ben. I hadn't really thought of using XSL to transform the contents of the custom tag! I'm going to have to see about performance if I try that in our applications.
This approach definitely seems to be the best, using a custom tag for each and every data node (as suggested by some other people in this thread) is going to be terribly expensive. Now I know premature optimization is the root of all evil, but this actually is from a recent experience...
The CFUnited Scheduler used a HTML generation taglib I had developed that allowed declarative markup generation in the style of XSL, but with the flexibility of CFML (xsl has really crippled string operations for instance).
So I had stuff like:
<htl:Tag name="td" class="title">
<cfif len(trackCode) AND trackCode NEQ "KN">
<htl:Attribute name="class" value="deleteable" append="true"/>
...
</cfif>
...
</htl:Tag>
The htl:Attribute allowed adding attributes to the containing tag without having to do <cfif> statements inside the < and >, or use large blocks with string appends before the html tag to figure out classes. I also added a condition="" attribute to the htl:Attribute that allowed nice declarative attribute changes without the extra cfif step too...
<htl:Attribute name="class" value="movable" append="true" condition="#len(property)#"/>
Which was sweet and really made the code beautiful (at least to me), but it turned out it was terribly sluggish in production.
Now sluggish is relative, I mean you used the scheduler last year.. did it feel slow?
In any case, with some profiling it showed that creating the lists of topics and sessions like this meant calling the htl:Attribute tag almost 700 times per synchronous request! htl:Tag might be called 50 times... which has a serious impact on performance.
So I inlined all that logic, which definitely made the code uglier, but it gave 200%+ increase in performance. Requests that took almost 2s were now taking 600ms. So with that in mind I think something between COOP and what you have is probably the best in terms of cost to productivity gains.
(Sorry for the super long comment :()
@Elliott,
The biggest problem with using the "string" data between the custom tags is that in order to get it into any kind of usable format, it needs to be parsed. This is always going to take some sort of performance hit. I guess the balancing act becomes custom tag usage vs. string parsing (such as to XML document model). Custom tags have overhead to execute, but so does string parsing.
As far as the schedule last year, I don't recall it being noticeably slow. Is it going to be the same code this year? I will keep my eye out for it.
More custom tags:
* Overhead of execution
* No string parsing
Less custom tags:
* Overhead of string parsing
Right now, I think only time and experimentation will tell. However, I will use your experience as a starting foot.
@Ben
The scheduler is the same code, with the refactoring to remove those custom tags and some other changes for better error messages. If there was something in particular you (or anyone else) wanted, I could certainly add that too!
The major thing to keep in mind in ColdFusion is that CF built in functions can be TONS faster than writing your own. Specifically, doing any kind of string parsing using listFind() is going to be many times faster than doing it with mid() left() and "eq". The smaller the chunks of the data that you're using for parsing, the slower it gets.
For instance I wrote a documentation generator for documenting our codebase using special comments instead of hint="". I started by using a very simplistic parser, but it had issues so I wrote a fairly effective CF parser that parses CF tag by tag, using the same rules as the real CF parser, into a data structure that could be analyzed. It also opens the door to some curious code transformation for optimization, but that's another topic! :P
Anyway, the parser written in CF was *SUPER* slow. Parsing 200 lines of cfcomponent with a few cffunctions could take 7000ms. Ouch. I rewrote it in Java and now I could parse ModelGlue.cfc (500ish lines) in about ~40ms. Wow! What's so slow? CF has no char data type, and to do proper parsing of ColdFusion code you need to parse char by char with some lookahead. That meant that the ModelGlue.cfc which is about 22.5k chars, was creating at least 22.5k single char string objects (and all the CF variable overhead and type casting too)! Compound the speed of the CF operators and cffunction calls for each char on that and you get mega-slow.
So that's something to keep in mind too. The more work you do in built-in CF functions and java the faster your code will be. The same is of course true in any other high level language. php is fastest when most of the work is done in built-in functions which are written in C++, which is also the reason that rewriting built in functions is such a bad bad idea! :P
I'm not sure that the discussions on performance are as helpful as it would seem. You can usually optimize performance without messing with the API.
For example, each nested custom tag could only have a cfassociate and do nothing else. The parent tag could then just use the child tags as a data set. This should be very performant (I have done this several times and it always seems very fast).
The more important discussion is one of API. By this, I mean do you pass in CSV data, a query, nested custom tags, or nest XHTML in the tag (as in the original example).
This really comes down to the intent of the tag, the amount of flexibility needed, and (more importantly) the desired audience.
Ben mentioned a front-end developer. If this is someone familiar only with HTML then passing in nested custom tags or XHTML will likely make the most sense to them.
If you expect that it will be used by a ColdFusion programmer, then it might make more sense to pass in a query or a structure.
If you are collecting data from a file or external process, then CSV or XML data may make more sense.
I think it is much more important to set your API based on the problem being solved and the audience than to adjust your API based on perceived performance implications.
@Steve Bryant
htl:Attribute was just a listFind() and a cfassociate, and that lone was causing the major slowdown. Custom Tag creation is quite slow compared to inline code, and part of designing a good API is thinking about where it'll be used. If this is something that's going to happen in a loop, all those custom tags can cause a major slowdown.
We need to remember that CF is not Java or C++. Function invocation and custom tags invocation are no where near equivalent to a pointer dereference and a jump. They are more close to thousands of times slower. So where this API might be used turns out to be very important.
Calling left() vs <mytag:left> vs mycomponent.myLeft() have radically different implications.
So don't be obsessed with performance, but don't ignore what you're doing either.
Elliott,
I think you understand me too quickly.
I wasn't speaking of your solution at all, but rather speaking to the general comments about deciding the API based on performance.
Certainly, there are cases where performance considerations must influence even the API. Even so, I think it is best to first consider what API is best to solve the problem. Then optimize as needed (even if that process precedes the release of any code).
To speak to your situation, that you first decided on an API and then changed it to meet performance needs is, I think a better approach than limiting the API based on perceived performance issues prior to finding out if you really have a problem (though if you know you have a ton of looping then experience may guide you well).
After all, the first rule of optimization is not to do it.
Steve,
Oh definitely! Sorry if I jumped ahead of you there.
@Elliott,
I wonder, if you always knew what tag you would be associating to, and you look out the ListFind(), would that be a significant increase in speed. It could be, that you develop tags with names specific enough that the association is always known. This would lead to more verbose naming conventions, but, could be a big speed increase?
OK... I will join in just a bit. :) (since I created COOP)
@Ben,
(In response to the article...)
1. I like XSLT but for the technology to be truly portable it has to be something people will use. Most developers kick and whine like a stuck pig about doing common XML alone! (Thought I like aspects of your concept completely.) So if it was included it would need to be layered so it could be used or not used.
2. I am working on another library called CFish that will handle this and many other aspects of presentation. My initial concern is that we need to be careful not to mix the presentation containers with the content or we loose portability at large. :) ... that is a whole different discussion. I will say that CSS is about * content, * content containers, and *presentation. Contrary to the supposition of just being "content and presentation".
3. The biggest advantages to COOP are preDOM coding and separating out the processing (coding) from the mark-up. We tend to "prototype" and then refactor the mark-up page to the co-processor. (It seems like our two concepts could intermingle is all this point is making.)
4. COOP Update
+ working on version 2.0 that doesn't break anything
+ we added unit testing on all CFC and tags to make sure things are working
+ ICE libraries > we are packaging libraries (or zoning) and have much work done already. We will go ahead and start releasing some of this stuff.
@Hal,
We talk about code reuse. We talk about code generation. Yet, we fail to talk about application reuse. If we can make sites skin'd then we could change the look of an application and redeploy to another site without having to rewrite the the program to get it to work with another presentation layer. (This is a prevailing problem... not one we need to search out. We just need to see what has been right before our eyes from the start.) This is why things like Nuke were created on other platforms and we could go beyond them with CF! :)
@Elliott and @Steve,
I might want to translate our later versions of CFish into that parser! Good post.
@John,
True, XSLT and XML is probably a barrier for many people, so in that sense, we definitely are going to be add not just processing overhead with it, but development overhead. In the long run, not the best solution in terms of ease of implementation.
As far as the whole separation between content and presentation and that mind set, when it comes to something like this, we are definitely have a paradigm shift. But, I think any time you abstract out the way a web element gets created, you are starting to move display out of the interfaces. I am not saying that is a bad thing - it definitely allows for global changes to made from a central place. But, it does limit what the front end developer can do. Of course, I suppose, in .NET, they have all those "renderer" hooks and elements, but even then, its going way beyond simple CSS and XHTML.
And, by the way, I love the idea of preDOM coding. While it might not be the same exact mindset, I definitely would love to see it as an additional application event - OnCommitStart():
www.bennadel.com/index.cfm?dax=blog:771.view
As far as talking about application re-use, I feel that something like that is going to have to use a system where you really describe the content entire first and the render it totally second. I know that's not really contributing to the conversation, but I thought I would chime in.
@Ben
If I remember right the tag invocation alone was enough to really throw performance off, but it's something I could see testing again just to see...
@Elliott,
I have not tested this in any way, but I gotta imagine that custom tags can't add TOO much overhead. Granted, I have no idea what's going on behind the scenes, but if you think about what a custom tag is doing:
1. Creating a local scope.
2. Writing contents to a separate buffer.
3. Associating with parent tags (if directed to).
I mean, is there really anything else going on? I find it hard to believe that ColdFusion doesn't have a way to compile this down. To me, it looks just like a UDF invocation where you pass attributes rather than arguments.
But, like I said, I know nothing about what is *actually* happening behind the scenes.
@Elliott,
Any line of code we execute will have a performance hit. :)
I would advise to not hit tags in a looped format. Yet, to just hit one or two tags in the flow should not have an effect that we would be concerned with unless of course the code inside the tag has a performance issue. (Which would not be a tag issue.)
In COOP there were two things that we could not achieve with CFCs.
1. The wrapping of code/content due to the existence/absence of end tags.
2. With people disliking script among CFers it is a real pain to achieve the same thing. In particular most developers (including us programmers when creating a design) think in tags. I guess a Flash/AS3 programmer may be free of these constraints! lol ... but the rest of us are not so advanced.
Using XSLT inside a custom tag is not so far streched. I have had cases where this was necessary. A lot of CMS systems capture the content in XML form, no matter if you are saving it to a database, a flat file or what not. They force you to use some type of XSLT to process the output anyway. These include some of the biggest industry names out there like EMC (formely Documentum's WebPublisher, which always ranks in the top spots in Enterprize CMS usage).
You guys are likely experienced with doing XSLT... could you suggest some sources for the general community to master (or become fluid and functional) in this skill?
@John,
I wrote an intro on XSLT a while back:
www.bennadel.com/index.cfm?dax=blog:952.view
I got a lot of my info from the W3Schools site:
http://www.w3schools.com/xsl/
@ben "I knew a guy who told me that he built all his pages in XML and used XSLT to render them. Apparently, this was all done on the fly and I never saw the code, but he said it was wicked fast."
Not exactly completely related, but a number of years ago, we were building a table version of a nested set hierarchy. rather easy to do, in itself and was just a cfoutput over the resultset, and required a fair number of conditionals. The tree had several thousand nodes and took a long time to render.
we took the same query, converted it to xml with cfxml, wrote the xslt to build the exact same structure, and applied it with xmltransform. the result was an identically rendered tree in less than 25% of the time of the previous version.
however for every day simple application stuff, xslt probably won't yield a noticable gain.
@John
a great place to learn stuff regarding xpath and xslt is zvon.org
@Matt,
That is incredibly interesting. So, if I understand what you are saying, the XSLT equivalent of the ColdFusion logic executed faster??
@Ben
yes. the reason we figured it worked faster was that we didn't have to evaluate as many conditionals when we created the xml, the xsl transformation then just applied the rules to the xml.
Very cool.