
Updating In-Memory (Temporary) SQL Tables With UPDATE / DELETE Clauses
This never occurred to me to try, but today, trying to solve a problem, I ran a SQL statement that attempted to use the UPDATE clause on an in-memory table. Much to my surprise (and delight), this worked! I had no idea that you could do this. To test it even further, I ran a DELETE clause as well. Worked like a charm!
Here is a demo of this in action:
<cfquery name="qID" datasource="#REQUEST.DSN.Source#">
DECLARE
@id TABLE (
id1 INT,
id2 INT
)
;
<!---
Populate the in-memory table variable with the
pivot data. We are going to store the same ID
into both columns so that we can demonstrate
that it was updated.
--->
INSERT INTO @id
(
id1,
id2
)(
SELECT TOP 5
p.id AS id1,
p.id AS id2
FROM
pivot100 p
);
<!--- Update the in-memory query. --->
UPDATE
@id
SET
id2 = (id2 + 5)
;
<!--- Delete from the in-memory query. --->
DELETE FROM
@id
WHERE
id1 >= 4
;
<!--- Select all values from the in-memory table. --->
SELECT
*
FROM
@id
</cfquery>
<!--- Dump out the query with both ID columns. --->
<cfdump
var="#qID#"
label="ID Query"
/>
CFDumping out the returned ColdFusion query object, we get:
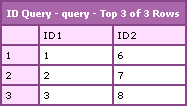
Notice that the UPDATE added 5 to the id2 column and that the DELETE deleted the last two records. I can't believe I am only learning this now!
Want to use code from this post? Check out the license.

Reader Comments
Trying to do it in a Query of Query is not so simple though! (but doable)
Very true! If ColdFusion could come up with a way to support UPDATE and DELETE in query of queries... I don't know what I would do, but it would be nuts!
Ben -
Thanks for posting this. I always enjoy reading your blog since I always learn something.
I've never thought about using in-memory sql tables. What would be some good reasons to use them?
In-memory tables are great for when you need to do some sort of intermediary data filtering before your primary query. For instance, you might create a table variable that holds just a column of "valid" IDs for a table. Then you could join that to another table:
SELECT
u.id
FROM
user u
INNER JOIN
@valid_user vu
ON
u.id = vu.id
Assuming that @valid_user is a table object that has only valid IDs, this INNER JOIN would force only users with IDs in that valid_user table to be returned.
Not the best example, but I promise in-memory tables are awesome :)
Ben,
Thank you for this. I have never used temp tables before because I usually did most database work through datasets. This could be very useful.
One question. is this supported with this syntax in both MSSQL and mySQL?
Thanks for this and your articles on CSV Parsing in particular. They have been very helpful with a project I am doing at home during the time I should be sleeping.
Regards,
Michael
@Michael,
Glad to help. I am not sure about mySQL as I work in MS SQL Server 99% of the time. I assume that this stuff is mostly standard, but I that is just a guess. I know mySQL had a lot of "annoying" features in earlier versions that have been cleaned up in the latest release (or so I have been told) so hopefully this should work in the newest version.
It's probably worth noting that table variables (@temp) in MS SQL are stored in RAM, as opposed to regular temp tables (#temp) are stored in the tempdb and require disk I/O. I use table variables when handling under 3000 records or so. Any larger and SQL Server will automatically start swapping data in the table to disk and the performance benifit is lost. Also I believe you can place indexes on a temp table, but not a table variable.
Another random fact. SQL Server 2005 will let you insert into a table variable with the output of a stored proc:
INSERT INTO @tmp
(col_1,
col_2)
EXEC ps_return_records
In SQL server 2000 you could only do this with temp tables.