
Building Tree Structures From Hierarchical Data In ColdFusion
The other day on the CFBreak newsletter, Robert Zehnder had a code kata post about creating tree structures using a recursive function. His approach is clever and makes you think. And it inspired me to talk about how I build tree structures in ColdFusion. Which is something I've had to do a lot in my career. While significantly less clever than Robert's recursive brain teaser, my approach uses a two-pass O(n) algorithm.
Consider this sample data (provided by Robert), which contains book categories. Each book category can optionally reside within a parent category based on a parentID. In my case, the 0 represents a root category (Robert used null, but I tend to prefer unified data types).
In the following data, note that Fiction and Non-Fiction are root categories and have a parentID of 0. Every other category is a sub-category; and several sub-categories may reside within a single parent.
[
{ "id": 1, "parentID": 0, "name": "Fiction" },
{ "id": 2, "parentID": 0, "name": "Non-Fiction" },
{ "id": 3, "parentID": 1, "name": "Science Fiction" },
{ "id": 4, "parentID": 1, "name": "Fantasy" },
{ "id": 5, "parentID": 3, "name": "Space Opera" },
{ "id": 6, "parentID": 3, "name": "Cyberpunk" },
{ "id": 7, "parentID": 4, "name": "Epic Fantasy" },
{ "id": 8, "parentID": 2, "name": "History" },
{ "id": 9, "parentID": 8, "name": "Ancient History" },
{ "id": 10, "parentID": 8, "name": "Modern History" }
]
When converting this type of hierarchical data into a tree structure, I use a two-pass algorithm. The first pass creates an index that groups all of the elements by a given key / facet. In this case, I'll group all the elements by the parentID. This would give me an index:
index[ parentID ] => children[]
The second pass then uses this index to inject a .children property into each element. Not all categories have sub-categories; so the second pass has to have fall-back logic when the index look-up fails.
Note: my algorithm mutates the original data structure instead of mapping onto a new one. Since I'm essentially always reading data out of database in order to perform this kind of work, the data I'm consuming is always isolated and an in-place mutation is never a problem.
In the following ColdFusion code, I'm building the tree structure twice: once using the data as-is and once after the set of categories has been sorted. Since the algorithm consumes the data in the order provided, sorting the set of categories implies that the set of sub-categories will also be sorted.
<cfscript>
// Data and exploratory concept borrowed from:
// https://kisdigital.com/posts/2026/04/stump-the-programmer-the-recursive-shelf
flatData = [
[ id: 1, parentID: 0, name: "Fiction" ],
[ id: 2, parentID: 0, name: "Non-Fiction" ],
[ id: 3, parentID: 1, name: "Science Fiction" ],
[ id: 4, parentID: 1, name: "Fantasy" ],
[ id: 5, parentID: 3, name: "Space Opera" ],
[ id: 6, parentID: 3, name: "Cyberpunk" ],
[ id: 7, parentID: 4, name: "Epic Fantasy" ],
[ id: 8, parentID: 2, name: "History" ],
[ id: 9, parentID: 8, name: "Ancient History" ],
[ id: 10, parentID: 8, name: "Modern History" ],
];
// Version 1: using the data as-is, in the order it was provided.
writeDump(
var = buildTree( flatData ),
label = "Unsorted"
);
// Version 2: sorting the data first. Since the array is grouped as-is, and then woven
// together as-is, if we sort the original array, the sort will be maintained through
// the entire algorithm.
// --
// Note: the buildTree() algorithm is idempotent in that it will just overwrite the
// already-injected "children" array from the first version.
writeDump(
var = buildTree( arraySortOn( flatData, "name" ) ),
label = "Sorted"
);
// ------------------------------------------------------------------------------- //
// ------------------------------------------------------------------------------- //
/**
* I build a hierarchical tree from the given array-of-structs. A "children" array is
* injected IN PLACE within each struct based on the "parentID" relationship. Elements
* that have no children receive an empty array.
*/
private array function buildTree( required array data ) {
// The algorithm does two passes on the array - O(n). The first pass creates an
// index that groups every element by the "parentID". The second pass uses said
// index to weave the elements together.
var indexByParent = arrayGroupBy( data, "parentID" );
// Pass 2: weave the elements together via the index.
for ( var element in data ) {
element.children = ( indexByParent[ element.id ] ?: [] );
}
// The root of the tree is the layer of elements that has no parent.
return indexByParent[ 0 ];
}
/**
* I return an index of the given array with elements grouped by the given keyed-value.
*/
private struct function arrayGroupBy(
required array input,
required string key
) {
var index = {};
for ( var element in input ) {
var facet = toString( element[ key ] );
if ( index.keyExists( facet ) ) {
index[ facet ].append( element );
} else {
index[ facet ] = [ element ];
}
}
return index;
}
/**
* I sort the given array on the value sorted in the given key.
*/
private array function arraySortOn(
required array input,
required string key
) {
return input.sort( ( a, b ) => compareNoCase( a[ key ], b[ key ] ) );
}
</cfscript>
This arrayGroupBy() user defined function (UDF) is worth its weight in gold. I use it all the time in my work. That and arrayIndexBy() - essentially the non-grouped version - are some of my most valued tools.
When we run this ColdFusion code, we get the following page output:
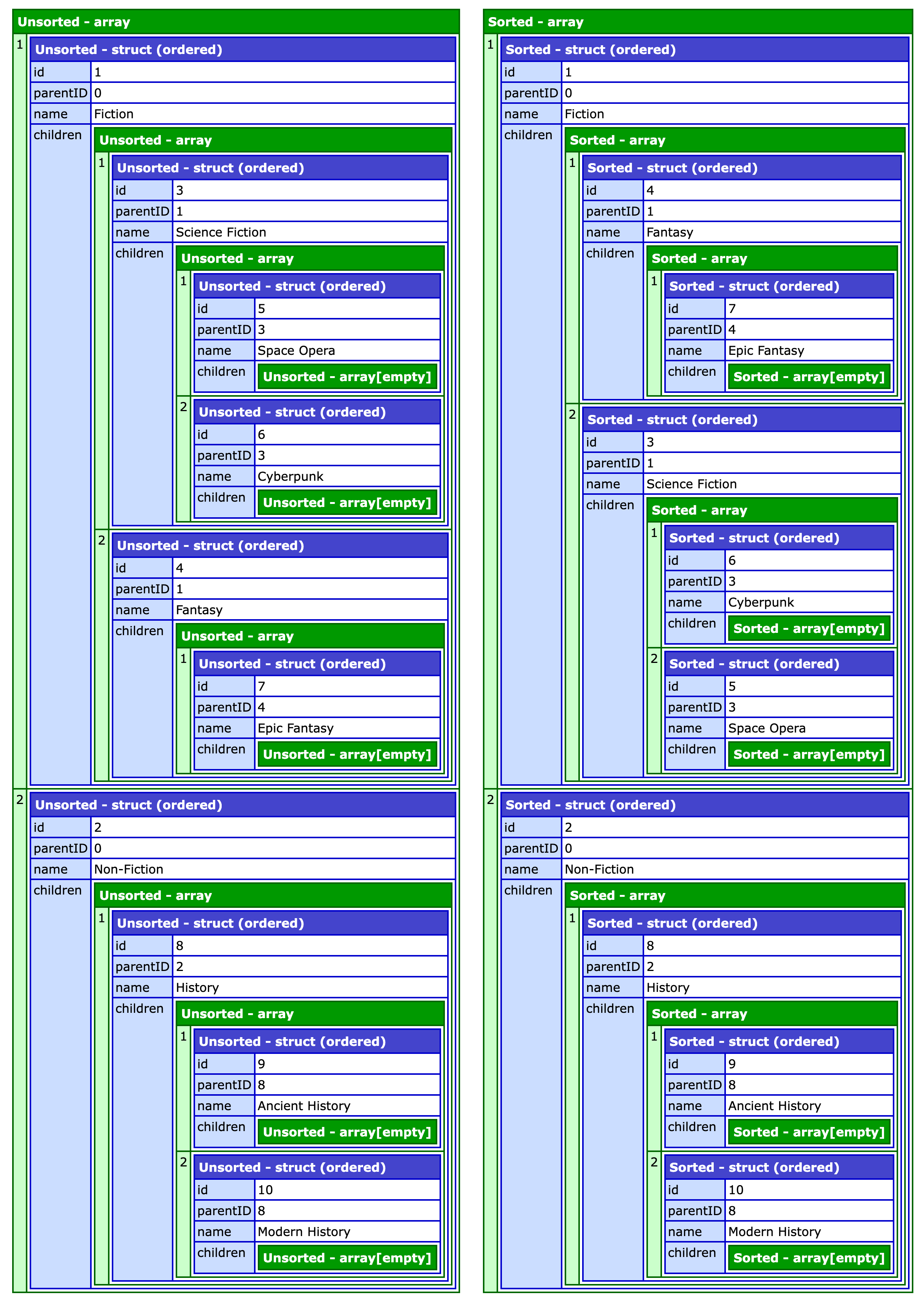
The flat array of book categories has been turned into a nested data structure with the root object being an array of top-level categories (ie, those with no parent). The array on the left is the unsorted version and the array on the right is the sorted version.
I use this kind of approach a lot. And since I own the data, I rarely have to think about data integrity; which is why I have no contingency logic here for mismatched IDs. That said, bugs do happen; and if I do end up with a situation where &mash; for example — I have an invalid parent ID, I'll usually put a temporary hotfix in place (to stop the errors) while I buy time to cleanup the data in the database.
Want to use code from this post? Check out the license.

Reader Comments
😮
I was always wary of recursive functions because it feels like it adds complexity. I was working on a comment system at the time that would take a flat array of comments and build the tree. I tried to over-complicate it, but the recursive function made it easy.
I am glad you enjoyed the puzzle. 😃
@Robert,
The recursion is always fun to think about! And sometimes it makes the algorithm clearer. I was just trying to show a non-recursive way that I do the same kind of work. It's all in good fun, to keep the brain working! Love the puzzle idea, hope to see more of them.
Post A Comment — ❤️ I'd Love To Hear From You! ❤️
Post a Comment →