
Routing External Links Through An Intermediary Page In ColdFusion
Yesterday, I looked at parsing URLs in ColdFusion. This was top-of-mind for me because I added external-link interception in Big Sexy Poems, my CFML-based poetry app. We used to do this at InVision; but, you've probably seen similar patterns on sites like LinkedIn that render user generated content (UGC) in which a malicious actor might embed links to an external site. Often times, the hosting site (ex, LinkedIn) will route these external links through an intermediary / interstitial page that warns the consuming user that they are about to leave the current site.
External Link Interception Workflow
When routing external links through a proxy page, the workflow goes like this:
Before rendering user generated content, look for embedded links.
Iterate over links to locate ones that point to a different domain.
Rewrite the
hrefattribute of said links to point to an interstitial page with the originalhrefattribute (external URL) passed-along as a query-string parameter.Render interstitial page with a warning about leaving the current site and provide a call-to-action for following the provided UGC link.
To see this in practice, I've added a Markdown description to my Demo Collection for Big Sexy Poems:
These are poems that I post publicly for demo purposes (of Big Sexy Poems).
For more formation about Ben Nadel, see
https://www.linkedin.com/in/bennadel/
To see the code that build this site, see
https://github.com/bennadel/app.bigsexypoems.com
Because I have Flexmark set to auto-link embedded URLs, the two references to LinkedIn and GitHub will be parsed into <a> tags. Which means that when I render the description HTML, it will render links to external sites.
At the time of rendering, I'm inspecting the user generated content, and I'm routing these external links through to my go.external controller:

If I were to then click on one of the links, instead of going to LinkedIn directly, I'd go the event=go.external controller to see the warning about off-site navigation:
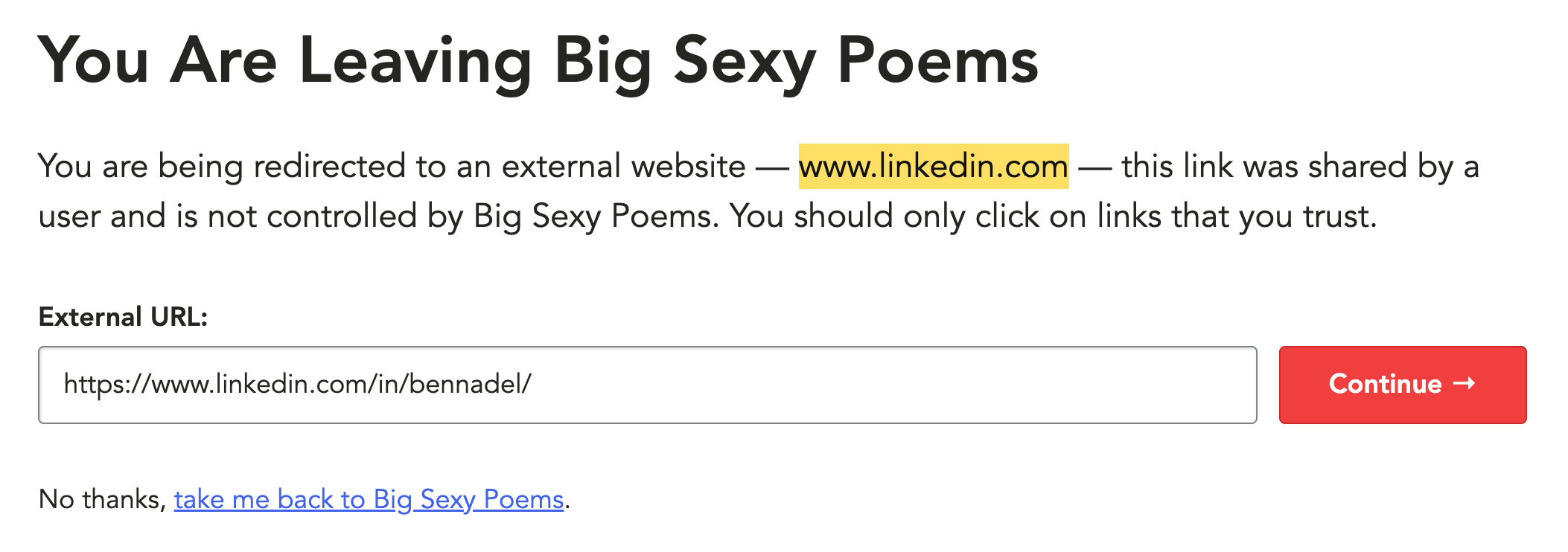
The interstitial page clearly identifies that the user is about to leave the current site (Big Sexy Poems); that the given URL was provided by another user and is not inherently trustworthy; identifies the top-level domain in question; and finally, provides access to the link for inspection.
ColdFusion Implementation Details
The primary mover in this workflow is a ColdFusion component that takes the HTML to be rendered and returns HTML with external links rerouted through the go.external controller. I'm doing this at rendering time when I'm gathering up the data to display on the page. Interception is a runtime concern; as such, I didn't want to persist this redirect to the database.
Here's a truncated version of the data-loading getPartial() for the Collection detail (the first screenshot from above):
<cfscript>
/**
* I get the partial data for the view.
*/
private struct function getPartial(
required struct authContext,
required numeric collectionID
) {
var collection = .... ;
var poems = .... ;
// Proxy any external links through an interstitial page where we can alert the
// user that they are about to leave the site.
collection.descriptionHtml = externalLinkInterceptor.intercept( collection.descriptionHtml );
return {
collection,
poems,
};
}
</cfscript>
The ExternalLinkInterceptor.cfc component passes the original, external URL through as a Base64url-encoded parameter. Since an external URL has a lot of sub-components (path, search parameters, fragment, etc), the Base64url-encoding just keeps things simple.
Here's my ColdFusion interceptor - the primary method is intercept() - this is where the external links are found and proxies. The decode() method is a simple utility method for decoding the Base64url-encoding on the interstitial page.
component hint = "I rewrite external links in HTML to route through an interstitial warning page." {
// Define properties for dependency-injection.
property name="base64UrlEncoder" ioc:type="core.lib.util.Base64UrlEncoder";
property name="internalHost" ioc:skip;
property name="jsoup" ioc:type="core.lib.util.JSoupParser";
property name="logger" ioc:type="core.lib.util.Logger";
property name="router" ioc:type="core.lib.web.Router";
property name="site" ioc:get="config.site";
property name="urlParser" ioc:type="core.lib.util.UrlParser";
// ColdFusion language extensions (global functions).
include "/core/cfmlx.cfm";
/**
* I initialize the interceptor.
*/
public void function initAfterInjection() {
variables.internalHost = urlParser.getHost( site.url );
}
// ---
// PUBLIC METHODS.
// ---
/**
* I decode the given external URL payload, returning the original URL string.
*/
public string function decode( required string encodedUrl ) {
return base64UrlEncoder.decodeString( encodedUrl );
}
/**
* I intercept external links in the given HTML, rewriting them to proxy through the
* external link warning page.
*/
public string function intercept( required string html ) {
if ( ! html.len() ) {
return html;
}
var body = jsoup.parseFragment( html );
var anchors = body.select( "a[href]" );
var mutationCount = 0;
for ( var anchor in anchors ) {
if ( isInternal( anchor ) ) {
continue;
}
mutationCount++;
// When passing URLs around as a search parameter in another URL, I find that
// it's safest to encode the URL using base64url. This way, we don't have to
// worry about any issues with double-encoding of embedded query string values
// or losing access to embedded fragments.
anchor.attr(
"href",
router.urlFor([
event: "go.external",
externalUrl: base64UrlEncoder.encodeString( anchor.attr( "href" ) )
])
);
// Since we're going to be linking to an external resource, we want to open
// the link in a new browser tab and inject rel attributes that prevent the
// browser from providing information and mutation mechanics to a potentially
// malicious target. You can see the OWASP guide to "reverse tabnapping":
// --
// https://owasp.org/www-community/attacks/Reverse_Tabnabbing
anchor.attr( "rel", "noopener noreferrer" );
anchor.attr( "target", "_blank" );
}
return mutationCount
? body.html()
: html
;
}
// ---
// PRIVATE METHODS.
// ---
/**
* I determine if the given anchor element links to an internal page of the site.
*/
private boolean function isInternal( required any anchor ) {
// While URLs are extremely flexible, the underlying URL parser (java.net.URI)
// does have issues with characters outside of the URI specification. This is an
// edge-case; but we need to wrap parsing in a try-catch so that we don't break
// the calling context (which may be rendering the only view that allows editing
// of this HTML content).
try {
var href = anchor.attr( "href" );
// When parsing the href, we want to resolve it against the site URL such that
// if the href is a relative or root-relative links, it will take on the site
// host. This makes the comparison feel a little more safe. Note that if the
// href has a host already, the site URL resolution will be ignored.
var host = urlParser.getHost( href, site.url );
return ( host == internalHost );
} catch ( any error ) {
// Malformed URLs are considered external for safety purposes.
logger.logException( error );
return false;
}
}
}
Internally, this ColdFusion component is iterating over the <a[href]> elements and comparing the host in the given anchor to the host of the current site (Big Sexy Poems). This is where the URL parsing from the aforementioned blog post comes to bear. I only need to alter href attributes that point to a different domain.
Although I talked about URL parsing yesterday, that was a standalone example. Here's the internal implementation of the UrlParser.cfc that I'm using in Big Sexy Poems. Note that the urlParser.getHost() call from above is just a thin utility wrapper around the more robust parseUri() method.
component {
// Define properties for dependency-injection.
property name="URIClass" ioc:skip;
/**
* I initialize the parser.
*/
public void function init() {
variables.URIClass = createObject( "java", "java.net.URI" );
}
// ---
// PUBLIC METHODS.
// ---
/**
* I get the host from the given URI. If a base is provided, the input URI is resolved
* against the base URI before it's parsed.
*/
public string function getHost(
required string input,
string base = ""
) {
return parseUri( argumentCollection = arguments )
.host
;
}
/**
* I parse the given URI into its component parts. If a base is provided, the input URI
* is resolved against the base URI before it's parsed. URI components follow the given
* semantics:
*
* Example: "https://admin:test@example.com:80/users.cfm?id=4#details"
* -------
* scheme: "https"
* authority: "admin:test@example.com:80"
* userInfo: "admin:test"
* host: "example.com"
* port: "80"
* resource: "//admin:test@example.com:80/users.cfm?id=4"
* path: "/users.cfm"
* search: "?id=4"
* parameters: "id=4"
* hash: "#details"
* fragment: "details"
*/
public struct function parseUri(
required string input,
string base = ""
) {
// If a base is provided, we want to resolve the input against the base. This is
// primarily helpful when the input lacks a scheme and/or authority. Resolution
// will traverse "../" and "/" path segments as needed.
var uri = base.len()
? URIClass.create( base ).resolve( input )
: URIClass.create( input )
;
// The URI object exposes a mix of encoded and decoded values. I've opted to
// surface all of the ENCODED values as the common case since this more closely
// aligns with the CGI scope that developers are used to consuming. The DECODED
// values are included as the decoded sub-struct for anyone who needs them.
return [
input: input,
base: base,
source: uri.toString(),
scheme: lcase( uri.getScheme() ?: "" ),
authority: ( uri.getRawAuthority() ?: "" ),
userInfo: ( uri.getRawUserInfo() ?: "" ),
host: lcase( uri.getHost() ?: "" ),
// Port defaults to -1 if it's not defined. I'd rather have it consistently be
// reported as a string using the empty string as the fallback.
port: ( uri.getPort() == -1 )
? ""
: toString( uri.getPort() )
,
resource: uri.getRawSchemeSpecificPart(),
path: ( uri.getRawPath() ?: "" ),
// Search is just a representation of the parameters prefixed with a "?". If
// the parameters are empty, so is the search.
search: len( uri.getRawQuery() )
? "?#uri.getRawQuery()#"
: ""
,
parameters: ( uri.getRawQuery() ?: "" ),
// Hash is just a representation of the fragment prefixed with a "#". If the
// fragment is empty, so is the hash.
hash: len( uri.getRawFragment() )
? "###uri.getRawFragment()#"
: ""
,
fragment: ( uri.getRawFragment() ?: "" ),
// An absolute URI starts with a scheme (http:, mailto:, etc). A non-absolute
// URI would start with something like "/" or "../" or "my/path".
isAbsolute: uri.isAbsolute(),
// An opaque URI is one whose resource is not representative of a path. It's
// for schemes like "mailto:" and "tel:". An opaque URI's resource isn't
// parsed into smaller components (path, parameters, etc). All non-relevant
// components will default to the empty string.
isOpaque: uri.isOpaque(),
// These decoded components include decoded character sequences. These aren't
// always safe to use because embedded delimiters such as "/" and "&" can
// corrupt the meaning of the string.
decoded: [
authority: ( uri.getAuthority() ?: "" ),
userInfo: ( uri.getUserInfo() ?: "" ),
resource: uri.getSchemeSpecificPart(),
path: ( uri.getPath() ?: "" ),
parameters: ( uri.getQuery() ?: "" ),
fragment: ( uri.getFragment() ?: "" ),
],
];
}
/**
* I parse the given parameters string into an ORDERED struct of key-values pairs. Each
* value in the struct is an array of strings. Parameters are collected in the order in
* which they are parsed and are appended the proper array. If a given parameter
* doesn't have a value, the value will be parsed as an empty string. This provides a
* consistent interface - every key is guaranteed to have at least one value.
*
* Example: "tag=fun&tag=adventure&medium=movie&favorites"
* -------
* tag: [ "fun", "adventure" ]
* medium: [ "movie" ]
* favorites: [ "" ]
*/
public struct function parseParameters(
required string parameters,
boolean caseSensitive = false
) {
var segments = parameters.listToArray( "&" );
// By default, the casing of the parameter keys is insensitive; and is defined
// coincidentally by the first key encountered. When case-sensitivity is enabled,
// keys with different casing are collected into different entries.
var parameterIndex = caseSensitive
? structNew( "ordered-casesensitive" )
: structNew( "ordered" )
;
for ( var segment in segments ) {
// By using the list-methods, we're ensuring that we cover edge-cases in which
// the key is empty or the value contains embedded "=" characters. Note that
// the `true` in this case is `includeEmptyValues`.
var key = urlDecode( segment.listFirst( "=", true ) );
var value = urlDecode( segment.listRest( "=", true ) );
if ( parameterIndex.keyExists( key ) ) {
parameterIndex[ key ].append( value );
} else {
parameterIndex[ key ] = [ value ];
}
}
return parameterIndex;
}
/**
* I parse the given URI into its component parts. The search parameters are further
* parsed into an ORDERED struct of key-values pairs. See parseParameters() for details
* on how the parameters are returned.
*/
public struct function parseUriAndParameters(
required string input,
string base = "",
boolean caseSensitive = false
) {
var uri = parseUri( input, base );
// Swap out the parameters string with the newly parsed and constructed object.
// But, let's keep the original string for posterity.
uri.parametersString = uri.parameters;
uri.parameters = parseParameters( uri.parameters, caseSensitive );
return uri;
}
}
Once the user lands on the go.external controller, I grab the externalUrl search parameter out of the url scope and decode the Base64url-encoding. Here's a truncated version of this controller:
<cfscript>
// ... truncated ...
param name="url.externalUrl" type="string" default="";
// Note: we are intentionally doing this without a try/catch so that any decoding
// errors bubble up to the root of the application and render an error page. There's
// no meaningful way to recover locally from a malformed encoding.
externalUrl = externalLinkInterceptor.decode( url.externalUrl );
externalHostname = urlParser.getHost( externalUrl );
sitename = config.site.name;
// Only allow http:// and https:// URLs.
if ( ! externalUrl.reFindNoCase( "^https?://" ) ) {
throw( type = "App.BadRequest" );
}
include "./external.view.cfm";
</cfscript>
The include "./external.view.cfm"; renders the interstitial warning page (from the earlier screenshot).
Is This Really Necessary?
Probably not. For every site that uses this pattern for user generate content, I'm sure you can find 100 sites that don't use this pattern. But, a big part of why I'm building Big Sexy Poems is so that I have room to think about this type of problem. Especially in the age of AI / agentic coding, I know that I need to have a place where I can continue to think deeply about the low-level details of how ColdFusion works.
This is how I will continue to develop my sense of "taste" in application architecture.
OWASP Deprecation For noopener
As a quick aside, when I was looking for an OWASP URL to link to, regarding the rel attribute of external links, I came across this note on the OWASP site:
Update 2023 - this is fixed in modern, evergreen, browsers
Links that use
target="_blank"now have implicitrel="noopener"in modern browsers, so this vulnerability isn't as widespread and critical as before. This implicit rule is also a part of the HTML standard. According to Caniuse.com evergreen browsers support implicitrel="noopener"from about 2018, but there are still some browsers out there that doesn't support it, so please consider your userbase when/if deciding to droprel="noopener".Using
rel="noreferrer"implies alsorel="noopener", so if you have chosen to userel="noreferrer", the use ofrel="noopener"isn't required.
This is good to know. And a reminder that mental models that we've been building over the years are always evolving. And, former truths may turn out to be less truthy as time goes on.
Want to use code from this post? Check out the license.

Reader Comments
Post A Comment — ❤️ I'd Love To Hear From You! ❤️
Post a Comment →