
Adding Myers Diff To Share Link Snapshots In Big Sexy Poems
Last week, I added the ability for share links on Big Sexy Poems to include a snapshot of the poem name and content. This way, if you send someone a snapshot share link, you can continue to edit the poem without changing the user's experience of said share link. Once I had this in place, it occurred to me that the Myers Diff work that I did in ColdFusion would be perfect for illustrating the delta between the snapshot content and the live poem content.
When I implemented the Myers Diff algorithm in ColdFusion, I included a demo that looked somewhat like a single-column GitHub code diff — showing both lines that have changed as well as individual words within those lines that were either inserted or deleted. But, I only provided this low-level granularity for "isolated line mutations". That is, a single-line delete followed by a single-line insert.
When I tried to apply the same algorithm to Big Sexy Poems, the diffs looked very bland. In poetry, it's not uncommon for several lines in a row to each contain very minor edits (small word substitutions and rhyme improvements). As such, I was often seeing a "block" of sibling line changes that disabled the low-level granularity.
After getting disappointing results on my own, I started to talk through the poem-oriented line-diffing algorithm with Claude Code. We went down a few different rabbit holes (thank you source control!); and ultimately ended up implementing a side-by-side comparison in which blocks of line-deletes followed by blocks of line-inserts can be interleaved.
Consider a series of line changes: (D1, D2, D3, I1, I2, I3, I4). In this case "D" stands for "delete" and "I" stands for "insert". In my original algorithm, I would have shown the "D"s in series followed by the "I"s in series. But, Claude suggested that I zipper the changes together thusly:
D1 | I1
D2 | I2
D3 | I3
__ | I4 -- left-side is empty.
In this case, each delete that corresponds by position is put next to an insert. Any mismatch in the number of deletes with the number of inserts simply creates an orphaned row in which one side of the comparison is empty.
Once I had the side-by-side orientation, I could apply the low-level, token-based changes to each delete/insert on the same row.
It's definitely not a perfect algorithm; and will end up comparing rows that are unrelated. But, GitHub suffers from the same problem, often comparing rows of code that were unrelated. So, I take some comfort knowing that this is a hard problem to solve even for teams of people that are being paid to solve it.
To demonstrate this snapshotting diff, let's create a new poem in Big Sexy Poems:
Your juicy fruits and coffee notes,
Have given me an ache,
Your wicked smarts and clever quotes,
Are more than I can take!I've run the maths and found a sum,
Still I'm left unsated,
My soul is crushed and feeling numb,
Still I'm desimated!
Now, I'm going to create a snapshot share-link for this poem at this state. And with the snapshot in place, I'm going to update the poem content:
Your tasty fruits and coffee notes,
Have given me an ache,
With wicked smarts and clever quotes,
You're more than I can take!I've run the maths I've found a sum,
Still I feel unsated,
My soul is crushed and feeling numb,
Deeply desimated!
At a glance, you can see that one or two words have changed; but it's hard to get a sense of how extensive the changes are. Which is exactly what the diff is meant to illustrate. If we look at the share link detail, we can now clearly see the difference between the poem snapshot (stored in the share link) and the live poem:
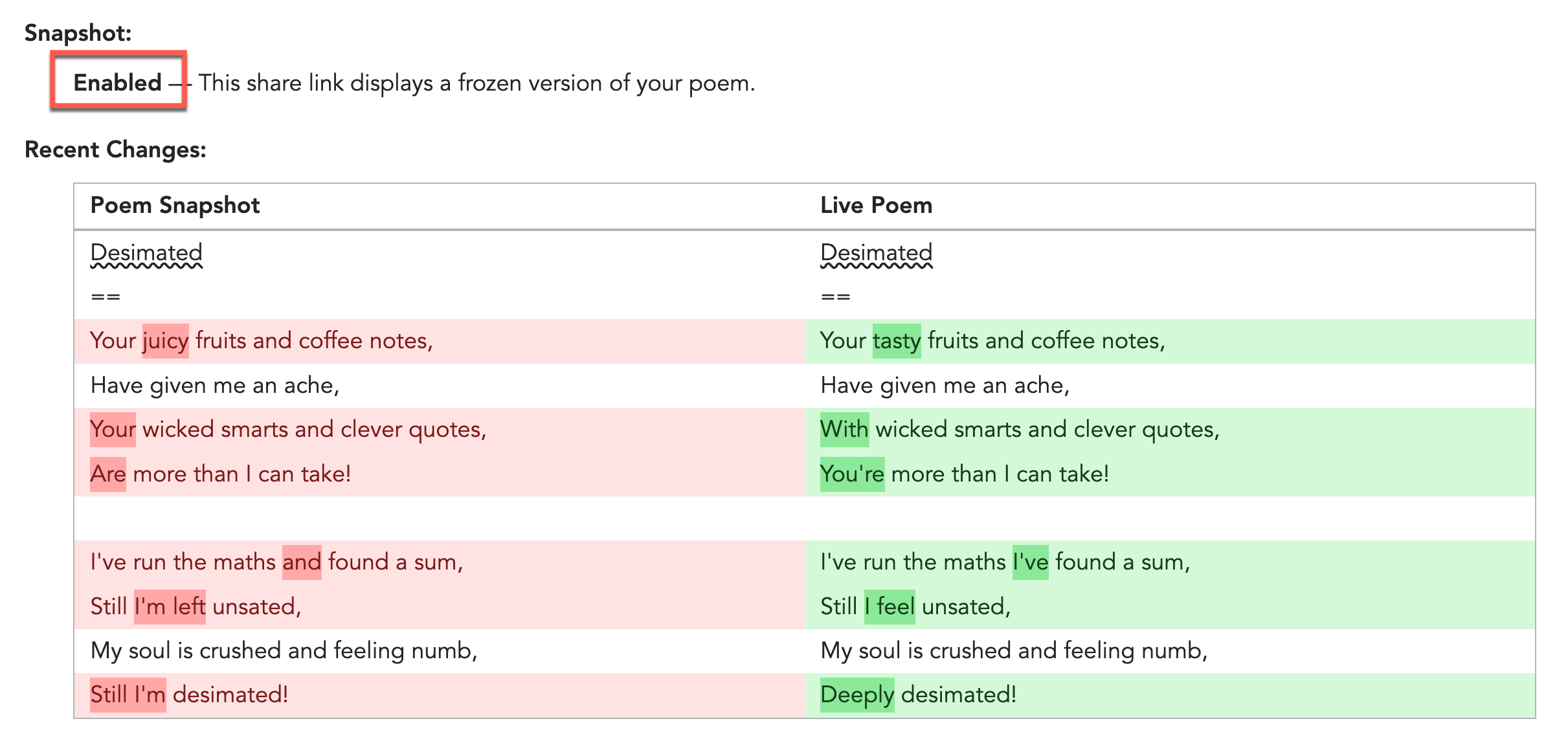
On the ColdFusion side, this is implemented by a PoemDiff.cfc ColdFusion component that wraps my original MyersDiff.cfc. Essentially, it calls the myersDiff.diffElements() internally, using the Name+Lines of the snapshot as the "original elements" and the Name+Lines of the live poem as the "modified elements" and then massages the diff into the side-by-side comparison structure that the output is expecting.
In the following code, the most interesting method is buildSplitRows() - the first private method. It's what zippers the delete/insert blocks together. The rest of the code performs the row-level, token-oriented diffing for word changes:
component {
// Define properties for dependency-injection.
property name="myersDiff" ioc:type="core.lib.util.MyersDiff";
property name="poemService" ioc:type="core.lib.service.poem.PoemService";
// ColdFusion language extensions (global functions).
include "/core/cfmlx.cfm";
// ---
// PUBLIC METHODS.
// ---
/**
* I diff two poem versions and return an array of split-row structs for a side-by-side
* view of the changes. Each row has "left" and "right" keys containing an operation
* struct with word-level tokens for paired mutation highlighting.
*/
public array function getSplitRows(
required string originalName,
required string originalContent,
required string modifiedName,
required string modifiedContent
) {
// Prepend title as first line so title changes appear in the diff naturally.
var originalLines = poemService.splitLines( originalContent );
originalLines.prepend( "==" );
originalLines.prepend( originalName );
var modifiedLines = poemService.splitLines( modifiedContent );
modifiedLines.prepend( "==" );
modifiedLines.prepend( modifiedName );
var diff = myersDiff.diffElements(
original = originalLines,
modified = modifiedLines
);
// Build the side-by-side rows directly from the flat operations, pairing deletes
// with inserts positionally within each mutation block. Then, enhance paired
// mutations with word-level tokens for inline highlighting.
return tokenizeSplitRows( buildSplitRows( diff.operations ) );
}
// ---
// PRIVATE METHODS.
// ---
/**
* I transform the flat diff operations array into an array of row structs for the
* side-by-side (split) view. Each row has "left" and "right" keys containing an
* operation struct. Contiguous mutation blocks are collected and deletes are zip-
* paired positionally with inserts; any orphans are paired with an empty placeholder.
*/
private array function buildSplitRows( required array operations ) {
var rows = [];
var placeholder = {
type: "empty",
value: "",
index: 0
};
var i = 1;
var operationCount = operations.len();
while ( i <= operationCount ) {
var current = operations[ i ];
if ( current.type == "equals" ) {
rows.append({
left: current,
right: current
});
i++;
continue;
}
// We've hit a mutation. Collect the entire contiguous block of mutations.
// Since Myers Diff emits all deletes before all inserts within a block, we'll
// gather them into separate lists and then zip-pair them positionally.
var deletes = [];
var inserts = [];
while ( i <= operationCount ) {
current = operations[ i ];
if ( current.type == "equals" ) {
break;
} else if ( current.type == "delete" ) {
deletes.append( current );
} else {
inserts.append( current );
}
i++;
}
// Zip-pair deletes with inserts by position. Any leftover operations on
// either side become orphans paired with an empty sentinel.
var deleteCount = deletes.len();
var insertCount = inserts.len();
var pairCount = max( deleteCount, insertCount );
for ( var p = 1 ; p <= pairCount ; p++ ) {
var left = ( deletes[ p ] ?: duplicate( placeholder ) );
var right = ( inserts[ p ] ?: duplicate( placeholder ) );
rows.append({ left, right });
}
}
return rows;
}
/**
* I extract and collapse word-level tokens from a word diff for one side of a paired
* mutation. The lineType ("delete" or "insert") determines which mutation tokens to
* keep — the other side's mutations are filtered out since each side of the split view
* only shows its own changes.
*/
private array function buildTokens(
required array wordOperations,
required string lineType
) {
var tokens = [];
// Since we're using the same set of operation to build both the left/right sides
// of the comparison, we need to filter word operations for the appropriate side.
// A delete line shows delete and equals tokens; an insert line shows insert and
// equals tokens.
for ( var wordOperation in wordOperations ) {
if (
( wordOperation.type == lineType ) ||
( wordOperation.type == "equals" )
) {
tokens.append({
type: wordOperation.type,
value: wordOperation.value
});
}
}
// Collapse adjacent mutation tokens that are separated by a whitespace-only
// equals token. This merges [mutation, whitespace, mutation] tuples into a
// single token, which reads better for the user.
var t = tokens.len();
while ( t >= 3 ) {
var minus0 = tokens[ t ];
var minus1 = tokens[ t - 1 ];
var minus2 = tokens[ t - 2 ];
if (
( minus0.type != "equals" ) &&
( minus1.type == "equals" ) &&
( minus0.type == minus2.type ) &&
( minus1.value.trim() == "" )
) {
minus2.value &= "#minus1.value##minus0.value#";
tokens.deleteAt( t-- );
tokens.deleteAt( t-- );
} else {
t--;
}
}
// Now that we've collapsed whitespace-based tuples, further collapse any sibling
// tokens that have the same type.
var t = tokens.len();
while ( t >= 2 ) {
var minus0 = tokens[ t ];
var minus1 = tokens[ t - 1 ];
if ( minus0.type == minus1.type ) {
minus1.value &= minus0.value;
tokens.deleteAt( t-- );
} else {
t--;
}
}
return tokens;
}
/**
* I perform a word-level diff against the two strings. Words and whitespace runs are
* treated as separate tokens, preserving spacing in the output.
*/
private struct function diffWords(
required string original,
required string modified,
boolean caseSensitive = true
) {
var pattern = "\s+|[\w""'\-]+|\W+";
return myersDiff.diffElements(
original = original.reMatch( pattern ),
modified = modified.reMatch( pattern ),
caseSensitive = caseSensitive
);
}
/**
* I enhance split rows with word-level tokens. For rows where a delete is paired with
* an insert (a mutation pair), both sides get word-level diff tokens that highlight
* the specific changes within the line. All other rows get a single token containing
* the full line value.
*/
private array function tokenizeSplitRows(
required array splitRows,
boolean caseSensitive = true
) {
for ( var row in splitRows ) {
// If this row pairs a delete with an insert, perform a word-level diff to
// highlight the specific changes within the line.
if (
( row.left.type == "delete" ) &&
( row.right.type == "insert" )
) {
var wordDiff = diffWords(
original = row.left.value,
modified = row.right.value,
caseSensitive = caseSensitive
);
row.left.tokens = buildTokens( wordDiff.operations, "delete" );
row.right.tokens = buildTokens( wordDiff.operations, "insert" );
// For non-paired operations, represent the full line as a single token.
} else {
row.left.tokens = [{
type: row.left.type,
value: row.left.value
}];
row.right.tokens = [{
type: row.right.type,
value: row.right.value
}];
}
}
return splitRows;
}
}
Now that I have snapshots working for share links, it makes me question why I don't have snapshots for poem changes over time. This feels like a natural next step; and something I should discuss with Claude Code. This is one of the things I appreciate most about AI — being able to discuss issues and work through the pros/cons of various choices.
Want to use code from this post? Check out the license.

Reader Comments
Post A Comment — ❤️ I'd Love To Hear From You! ❤️
Post a Comment →