
Paging Through Data Using LIMIT And OFFSET In MySQL And ColdFusion
When I render a data-grid for a user, I usually use pagination to allow the user to iterate through some relatively finite amount of records. The other day, however, I had to build an administrative UI (user interface) that surfaced a tremendous amount of data - possibly hundreds-of-thousands of records. With so much data, standard pagination didn't seem like a meaningful solution. Instead, I switched over to using LIMIT and OFFSET in my MySQL, which allows the admin to page through the data one slice at a time. I don't use this technique that often, so I thought a ColdFusion demo would be fun.
In MySQL, if we want to extract a subset of rows from a larger possible result-set, we can use LIMIT and OFFSET:
LIMIT R- Used to constrain the number of rows (R) returned by theSELECTstatement. MySQL can apply a number of query optimizations when this clause is present in the SQL.OFFSET N- Used to determine the first row to be returned in theSELECTstatement. In other words, this defines how many rows we skip (N) before we start including rows in our result-set.
I like to use both LIMIT and OFFSET together because it makes it super clear which value is which. That said, MySQL supports this syntax specifically for compatibility with PostgreSQL. If compatibility is not a concern, MySQL also supports a syntax wherein you pass two "arguments" to the LIMIT clause as a comma-delimited list:
LIMIT {offset}, {count}
I don't care for this syntax because if you use LIMIT with only a single argument:
LIMIT {count}
... then the meaning of the first argument changes semantics. This seems to violate the principle of least surprise; which is why I always explicitly define both the LIMIT and OFFSET clause - no surprises!
By using the LIMIT and OFFSET clauses, we can start to approach paging through a larger result-set by thinking of each page as a combination of these clauses. Consider a UI in which we show 10-records at a time to the user:
LIMIT 10 OFFSET 0- Page 1LIMIT 10 OFFSET 10- Page 2LIMIT 10 OFFSET 20- Page 3LIMIT 10 OFFSET 30- Page 4LIMIT 10 OFFSET 40- Page 5
This is great because, for each page, we only have to read in and return the rows that we need to render. But, if we are going to provide tooling that allows the user to move from one page to another, how do we know if there is another page to link to?
Going backwards in the pagination is easy: if we have a non-zero OFFSET, we know that we skipped rows to get to where we are; which mean, we have rows to go back to.
Going forward is a bit more tricky. If we pull back rows 40-50, how do we know if row 51 exists on the next page? To test for a "next page", I'm going to use a technique that I believe I learned about in High Performance MySQL: Optimization, Backups, and Replication. In that book, the authors suggest pulling back N+1 rows for each "page". Then, if the number of rows is larger than the "page size", you know that you have at least one row beyond the current page.
To see this in action, I've put together a ColdFusion demo in which I can page through my blog comments. Since this site has tens-of-thousands of comments, showing typical pagination makes no sense. But, we can use LIMIT and OFFSET to incrementally walk through the data.
In this ColdFusion demo, each page consists of 10 comments. As such, I'm going to use a LIMIT 11 in my SQL query in order to pull back the next 11 rows (at most). If I do get 11 rows, I know that I have a next page. In that case, I slice off the 11th row, deferring it to a future rendering.
<cfscript>
param name="url.offset" type="numeric" default="0";
// ------------------------------------------------------------------------------- //
// ------------------------------------------------------------------------------- //
pageSize = 10;
// Make sure we don't drop below zero for our offset - this can happen if someone
// messes with the URL and gives us an offset that doesn't fall on a single page.
pageOffset = max( 0, url.offset );
// When we pull back the page of records, we're going to read in ( PAGESIZE + 1 )
// rows. This will allow us to see if there are any rows on the subsequent page
// without having to perform an additional SQL query. In this case, the 11th row will
// represent the 1st row of the NEXT page.
comments = queryExecute(
"
SELECT
c.id,
c.contentMarkdown,
c.createdAt,
( m.name ) AS memberName,
( e.name ) AS entryName
FROM
blog_comment c
INNER JOIN
member m
ON
m.id = c.memberiD
INNER JOIN
blog_entry e
ON
e.id = c.blogEntryID
-- Paging through the records using LIMIT (how many rows we want to return)
-- and OFFSET (where in the results we want to start reading). It's critical
-- that we have an ORDER BY in a query like this, otherwise the order of the
-- rows can be inconsistent (it depends on which indexes the query optimizer
-- uses behind the scenes).
ORDER BY
c.id DESC
LIMIT
:limit
OFFSET
:offset
",
{
limit: {
value: ( pageSize + 1 ), // NOTE: Pulling back N+1 records.
cfsqltype: "cf_sql_bigint"
},
offset: {
value: pageOffset,
cfsqltype: "cf_sql_bigint"
}
}
);
// ------------------------------------------------------------------------------- //
// ------------------------------------------------------------------------------- //
// We know we have a PREV offset if our current offset is non-Zero.
hasPrev = !! pageOffset;
prevOffset = ( pageOffset - pageSize );
// Since our results read-in N+1 rows, we know we have a NEXT offset if our results
// are larger than our page size.
hasNext = ( comments.recordCount > pageSize );
nextOffset = ( pageOffset + pageSize );
// And, if we do have a NEXT offset, it means that we have one extra row in our
// results (N+1) - let's slice it out so that we defer it to the next page of data.
if ( hasNext ) {
comments = comments.slice( 1, pageSize );
}
</cfscript>
<cfoutput>
<!doctype html>
<html lang="en">
<head>
<meta charset="utf-8" />
<meta name="viewport" content="width=device-width, initial-scale=1" />
<link rel="stylesheet" type="text/css" href="./demo.css" />
</head>
<body>
<h1>
Paging Through Data Using LIMIT And OFFSET In MySQL And ColdFusion
</h1>
<div class="pager">
<div>
<cfif hasPrev>
<a href="#cgi.script_name#?offset=#prevOffset#">
« Prev #pageSize#
</a>
</cfif>
</div>
<div>
<cfif hasPrev>
Offset: #numberFormat( pageOffset )#
—
<a href="#cgi.script_name#">Reset</a>
</cfif>
</div>
<div>
<cfif hasNext>
<a href="#cgi.script_name#?offset=#nextOffset#">
Next #pageSize# »
</a>
</cfif>
</div>
</div>
<table>
<thead>
<tr>
<th> ID </th>
<th> Member </th>
<th> Comment </th>
<th> Created </th>
<th> Blog Entry </th>
</tr>
</thead>
<tbody>
<cfloop query="comments">
<tr>
<td> #encodeForHtml( comments.id )# </td>
<td> #encodeForHtml( comments.memberName )# </td>
<td> #encodeForHtml( comments.contentMarkdown.left( 100 ) )# </td>
<td> #dateFormat( comments.createdAt, "mmm d, yyyy" )# </td>
<td> #encodeForHtml( comments.entryName )# </td>
</tr>
</cfloop>
</tbody>
</table>
</body>
</html>
</cfoutput>
As you can see, I'm using LIMIT and OFFSET to pull back the current page of data (plus the 11th row indicating the next page). If I do have an 11th row, I record that I have a next page to render and then .slice() the query back down to 10 rows. Moving from page-to-page then becomes a matter of passing in the necessary offset via the url scope.
If we run this ColdFusion demo and then page through the records, we get the following output:
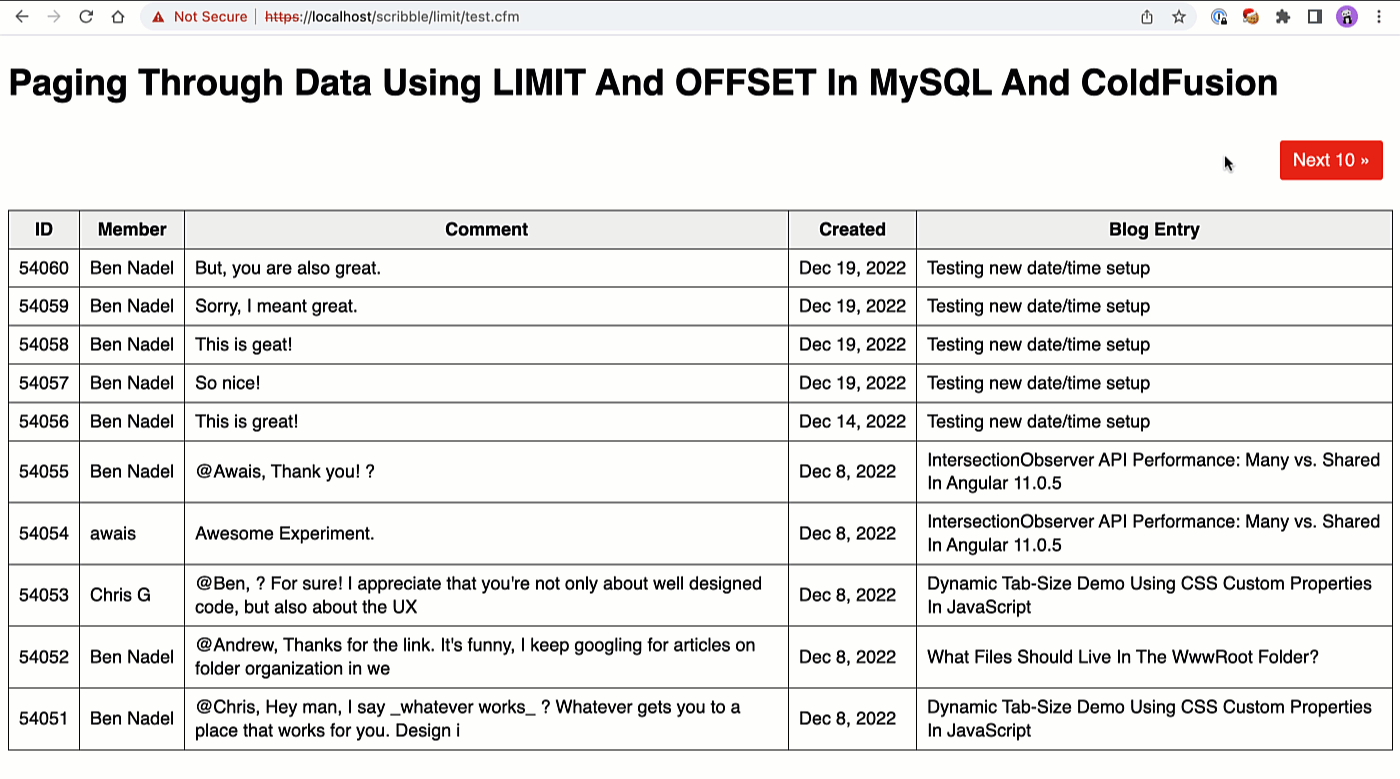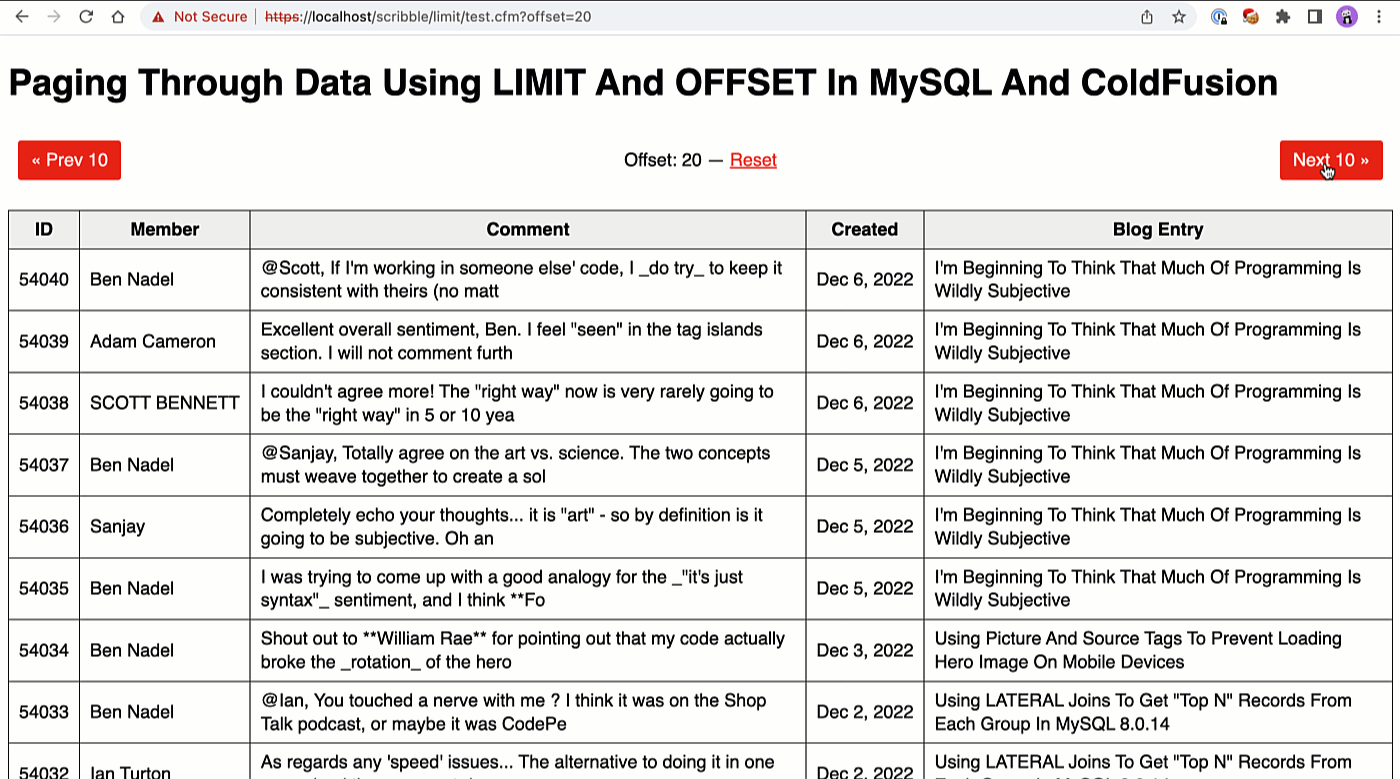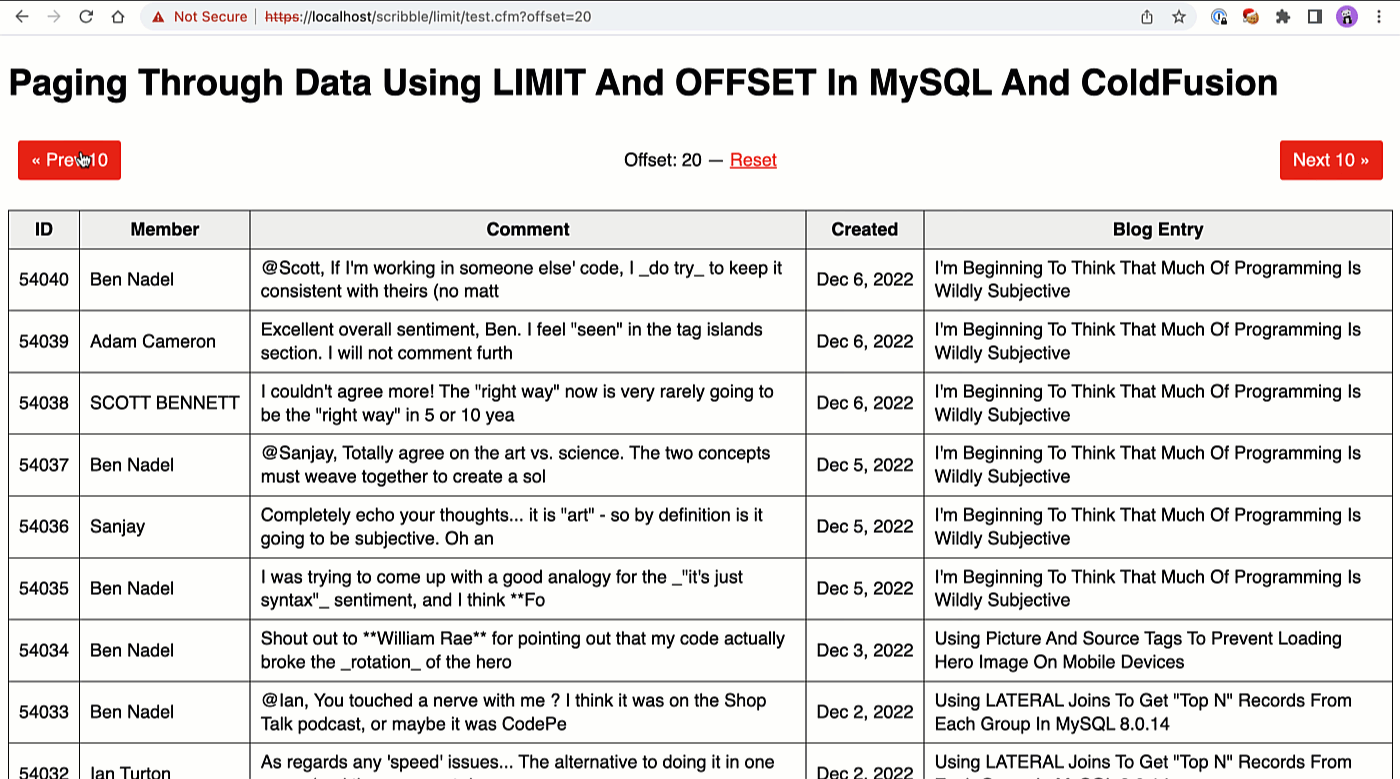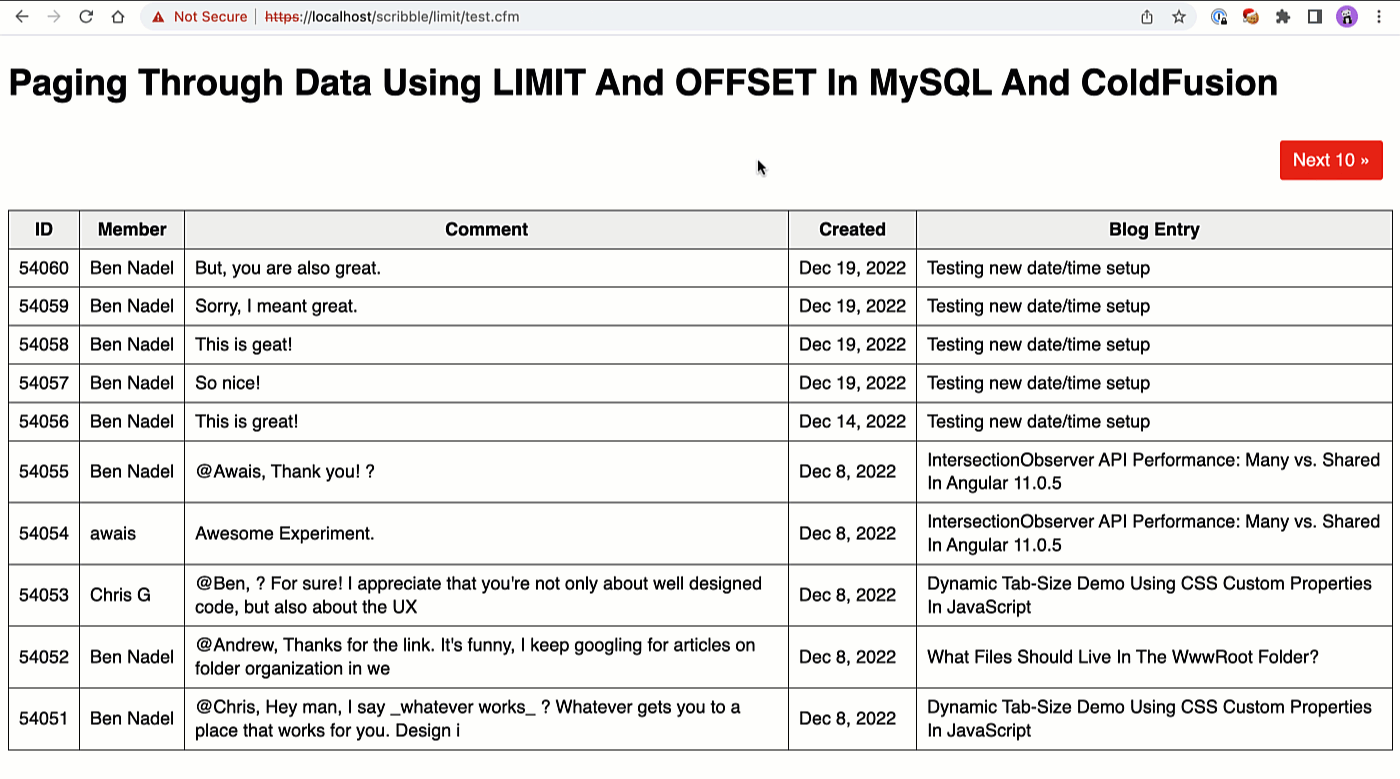
As you can see, we're able to quickly and easily page forward and backward through the larger result-set 10-rows at a time by adjusting the LIMIT and OFFSET clauses in our SQL query.
In some ways, I think this approach actually makes more sense than "traditional pagination". After all, the user's typical gesture is to go to the "next page" - how often do users want to jump to an arbitrary page (ie, "let's see what's on page 73!")? According to my application analytics, very rarely. This type of query is also easier to write and faster to perform.
Make Sure You Run EXPLAIN on Your SQL Query!
Speaking of performance, make sure you run an EXPLAIN on your SQL query! Even though we are only returning LIMIT {count} rows, it doesn't necessarily mean that the database is only reading that number of rows. If you keep your SQL query simple, MySQL can apply optimizations; however, the moment you start adding filtering to your query, you might accidentally trigger a full-table scan. This happened to me recently when I started showing recent comments on my blog.
Want to use code from this post? Check out the license.

Reader Comments
Over on LinkedIn, Igal Sapir mentioned that I should look at Markus Winand's post on paginating data without
OFFSET. It's a good read. From what I understand, one of the issues withOFFSETis that the database still has to read the rows (and drop them) until it gets to the desired offset in the recordset.While this is certainly true sometimes, I am not sure that it is true all the time - though, I am not a database export. When I run the
EXPLAINon my query, it says that it is performing a "reverse read" from the index in order to find the row. My understanding of that is that MySQL is using the index to locate the rows before I does the read.To be clear, this is a database optimization that MySQL can only do under certain circumstances! Which is why I made a point to say always run
EXPLAIN!With all that said, I'm going to see if I can rewrite this demo using Markus' approach to see how it looks / feels.
This morning, I started playing around with Markus' approach to pagination, which he calls either seek method or keyset pagination. It's definitely not straight-forward (in comparison to the
LIMITandOFFSETmethod). If you only need to go one direction (ie, next page, next page, next page), it's relatively simple. But, the moment you have to go to the previous page, you sort of need to flip all the logic in order to get the IDs needed to demarcate the page boundaries.I'll get something working, but it won't be today.
Still trying to get the "keyset pagination" to work, but won't have it done today. The more I dig into it, the more complicated it gets 😆 One of the nice things about the
OFFSETis that if you have anOFFSET 1and you get records back, you're very likely to be able to assume that records exist at anOFFSET 0. However, when we're doing key-based pagination, it's hard to assume things exist based on the current ID anchor..... and still trying to get Winand's "keyset pagination" to work. I keep running into more complications trying to perform it in a single query. My original thinking would that I could get N+2 records to see if I have pages on either side of the current N records. But, this breaks if someone deletes an earlier record.
For example, let's say the user is looking at records 1-10. Then, they go to the next page, and I try to query for 10-21 (in hopes that 10 will indicate a Previous page and 21 will indicate a next page). However, if someone deleted record 10 in the meantime, then the query will actually return 11-22. And, since "11" is supposed to be on the current page - not the last item on the previous page - I can't depend on the first record being the anchor from the previous page.
🤔 🤔 🤔 ... this is what makes the
OFFSETapproach so luxurious - it's an abstraction that takes care of much of the detail below the surface. When I start dealing with anchor IDs for pagination, then I start to run into all sorts of weirdness.I'm struggling to figure out how to do "keyset pagination" without having to run another query to see what the min/max IDs are to know if I can go to the previous page.
@All,
I just wanted to provide some real-world performance characteristics of this approach. I'm currently working on a workflow that queues-up and the processes a bunch of data. And, I've been using this
LIMIT/OFFSETapproach to page-through the queue data.My queue is currently at about 1.4M records, and paging-through it take about 1-2 seconds per page-load. And, that's just for the early pages (1, 2, 3, etc) - it's not like I'm paging to
OFFSET 100000or something. If I go directly to the database and run the application SQL withOFFSET 1000000, the query takes about 5-8 seconds to run.It's not horrible; but, it's not snappy either. You can very much feel the load times. That said, 1.4M records is a lot of data.