
ArraySlice() Has An Exponential Performance Overhead In Lucee CFML 5.3.8.201
The other day, I tweeted about Lucee CFML struggling with a massive array. I had created a data-processing algorithm that was taking an array of user-generated data and splitting it up into chunks of 100 so that I could then gather some aggregates on that data in the database. Everything was running fine until I hit a user that had 2.1 million entries in this array. This was an unexpected volume of data, and it crushed the CFML server. 2.1M is a lot of data to my "human brain"; but, it's not a lot of data for a computer. As such, I started to investigate the root performance bottleneck; and, I discovered that the arraySlice() function in Lucee CFML 5.3.8.201 has a performance overhead that appears to increase exponentially with the size of the array.
This data-processing algorithm that I wrote was running as a ColdFusion Scheduled Task. This task was incrementally traversing the user-space; and, within each user, was incrementally calculating aggregate information on a subset of their data and then storing it in a database table. All was fine for the first few hours of the task execution. But then, Friday night, I started getting operational alerts about the server exhausting its CPU.
I jumped into the FusionReactor APM (Application Performance Monitoring) dashboard to see what was going on and the graphs showed me that the CPU was pegged and that the memory was thrashing:
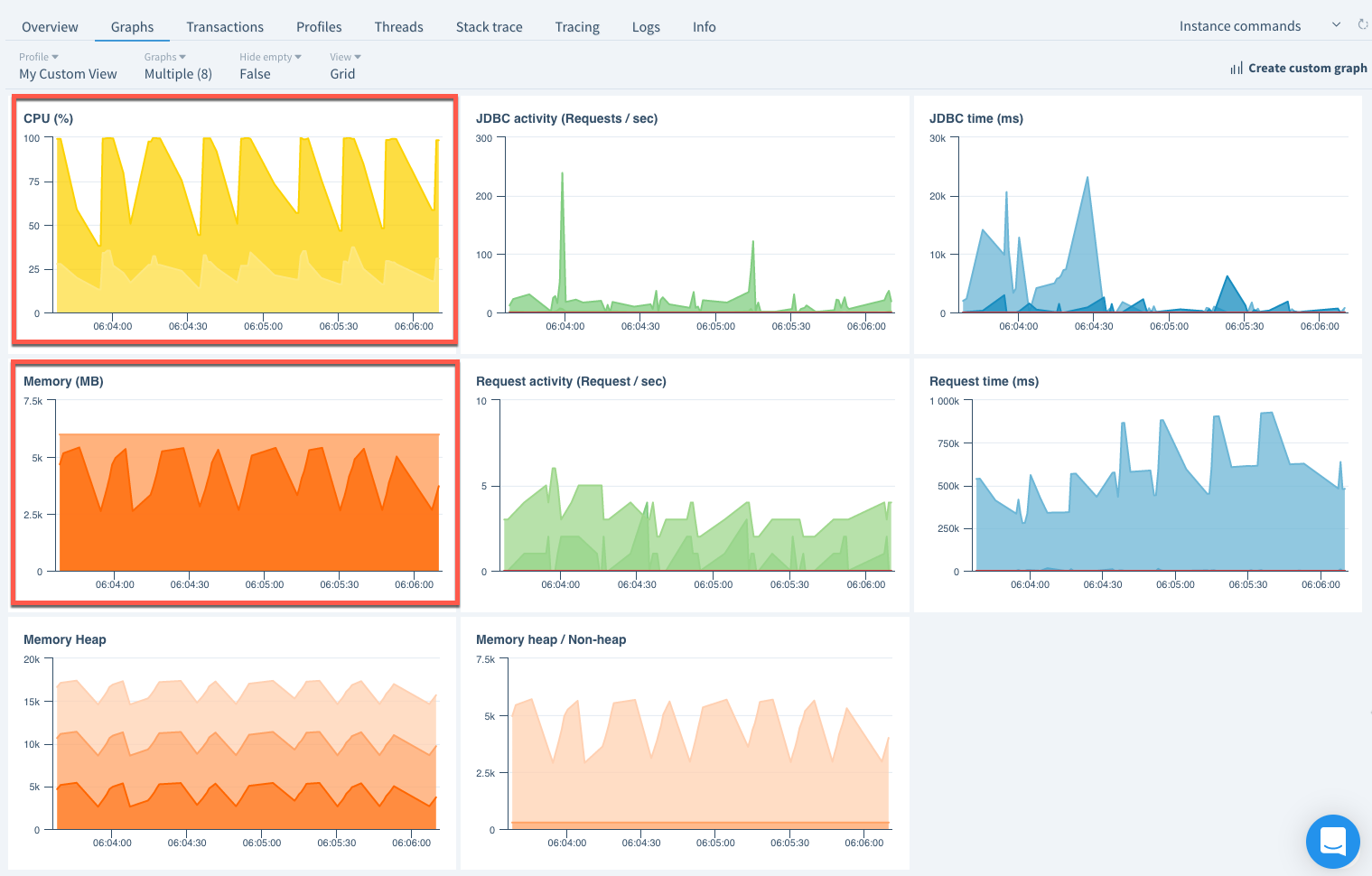
I then went into the running requests to see what was executing and I saw that my data-processing algorithm has been running for tens-of-thousands of seconds. This was an immediate red-flag because the algorithm actually has a short-circuit timeout of 10-minutes (so that it gives the server time to rest). So clearly, it was getting stuck somewhere.
I took a look at the stacktrace in FusionReactor; and, no matter how many times I refreshed the stacktrace, it was always sitting at the same spot:

Since Lucee CFML is open source, I jumped into GitHub and looked at their implementation of arraySlice() in Java. Here is a truncated version of that Java Class:
public final class ArraySlice extends BIF {
private static Array get(Array arr, int from, int to) throws PageException {
Array rtn = ArrayUtil.getInstance(arr.getDimension());
int[] keys = arr.intKeys();
for (int i = 0; i < keys.length; i++) {
int key = keys[i];
if (key < from) continue;
if (to > 0 && key > to) break;
rtn.append(arr.getE(key));
}
return rtn;
}
}
I'm not a Java developer, so my interpretation here may be off; but, looking at this code, two things jump out to me immediately:
I think the
arr.intKeys()is doing some sort of reflection to build-up an array of indices that are in the target collection. So, for my Array of 2.1M entries, this is building up an intermediary, throw-away array that is also 2.1M entries in size.It's building-up the desired slice by iterating over this intermediary keys array. Which means, if I want a slice starting at the index, 2M, this method literally loops over the first 2M entries in the
keysarray just to get to the start of my slice.
Keep in mind, this is algorithm is running for every slice that I generate. So, if I'm taking an array of 2M entries, and I'm splitting it up into slices that are 100 entries in size, this algorithm is running 200,000 times. Which means, 200,000 times I'm implicitly generating an intermediary array; and, 200,000 times I'm implicitly iterating over an increasingly large portion of the array to locate the slice.
That's a lot of work!
I started to look at alternative ways that I could break the massive array up into smaller groups without using arraySlice(). But first, I set up a control case so that I could see the relative performance. Here's my control case for arraySlice():
<cfscript>
include "./utilities.cfm";
// ------------------------------------------------------------------------------- //
// ------------------------------------------------------------------------------- //
things = getRange( 1000000 );
timer
type = "outline"
label = "Split Into Groups (Slice)"
{
groupedThings = splitArrayIntoGroups( things, 100 );
echo( "Done: #groupedThings.len()#" );
}
// ------------------------------------------------------------------------------- //
// ------------------------------------------------------------------------------- //
/**
* I split the collection into groups of the given max-length.
*/
public array function splitArrayIntoGroups(
required array collection,
required numeric maxLength
) {
var collectionLength = collection.len();
var groups = [];
for ( var i = 1 ; i <= collectionLength ; i += maxLength ) {
// The .slice() method will throw an error if we go past the end of the
// collection. As such, we have to clamp down the length.
var sliceLength = min( maxLength, ( collectionLength - i + 1 ) );
groups.append( collection.slice( i, sliceLength ) );
}
return( groups );
}
</cfscript>
As you can see, I'm taking an array of 1M entries and I'm breaking it up in groups of 100. The underlying algorithm in this case is iterating over the array and then using .slice() to gather sections of it. This is more-or-less the algorithm that I was running in production.
As my first attempt at a non-slice() approach, I decided to use a vanilla for-loop to iterate over every index in the array and incrementally build the groups as I go. Essentially, I keep adding an entry to a group until it hits its max-size; then, I move onto the next group:
<cfscript>
include "./utilities.cfm";
// ------------------------------------------------------------------------------- //
// ------------------------------------------------------------------------------- //
things = getRange( 1000000 );
timer
type = "outline"
label = "Split Into Groups (Iterate)"
{
groupedThings = splitArrayIntoGroups( things, 100 );
echo( "Done: #groupedThings.len()#" );
}
// ------------------------------------------------------------------------------- //
// ------------------------------------------------------------------------------- //
/**
* I split the collection into groups of the given max-length.
*/
public array function splitArrayIntoGroups(
required array collection,
required numeric maxLength
) {
var collectionLength = collection.len();
var groups = [];
var group = [];
for ( var i = 1 ; i <= collectionLength ; i++ ) {
group.append( collection[ i ] );
if ( group.len() == maxLength ) {
groups.append( group );
group = [];
}
}
if ( group.len() ) {
groups.append( group );
}
return( groups );
}
</cfscript>
After I wrote this version, I wasn't satisfied with the fact that I was looking up the [i] value on each iteration. One of the features that I love about Lucee CFML is that you can seamlessly use all ColdFusion tags inside CFScript. And, another feature that I love about Lucee CFML is that the CFLoop tag can expose multiple values at the same time.
When using the CFLoop tag to iterate over an array Array, we can get both the index and the entry exposed as iteration variables:
<cfscript>
include "./utilities.cfm";
// ------------------------------------------------------------------------------- //
// ------------------------------------------------------------------------------- //
things = getRange( 1000000 );
timer
type = "outline"
label = "Split Into Groups (Loop)"
{
groupedThings = splitArrayIntoGroups( things, 100 );
echo( "Done: #groupedThings.len()#" );
}
// ------------------------------------------------------------------------------- //
// ------------------------------------------------------------------------------- //
/**
* I split the collection into groups of the given max-length.
*/
public array function splitArrayIntoGroups(
required array collection,
required numeric maxLength
) {
// PERFORMANCE NOTE: This code looks a bit esoteric; but, that's because this
// method is being used to split MASSIVE ARRAYS (2M+ elements) into smaller
// arrays. The code below is an attempt to remove any calls to methods like .len()
// and .append(), which add overhead.
var groups = [];
var groupsLength = 0;
var segment = [];
var segmentLength = 0;
loop
index = "local.i"
item = "local.item"
array = collection
{
segment[ ++segmentLength ] = item;
if ( segmentLength == maxLength ) {
groups[ ++groupsLength ] = segment;
segment = [];
segmentLength = 0;
}
}
if ( segmentLength ) {
groups[ ++groupsLength ] = segment;
}
return( groups );
}
</cfscript>
Not only does this implementation use the CFLoop tag to implicitly access both the index and entry values, it also uses some length-based shenanigans to avoid making any .append() calls. Remember, I'm trying to reduce the performance overhead of splitting up a 2M entry collection, micro-optimization is the goal.
When I ran these test, there was some small variation in each execution. But, generally speaking the order of magnitude was consistently along these lines:

In case the image above doesn't load, I was getting these results consistently (with some small variation):
Slice algorithm: 130,821 ms. 😱
Iteration algorithm: 884 ms.
Loop-tag algorithm: 254 ms. 🔥
Oh chickens!! My final algorithm - using the CFLoop tag - was 515 times faster than the algorithm using the .slice() method. On a small array, these differences are inconsequential. But, at large scale, this is the difference between the server crashing and the server not even batting an eye.
I'm sure there is a reason that the arraySlice() method is implemented the way it is - probably something to do with "sparse arrays". But, in my case, I know exactly what the data is going to look like. And, as such, I can make certain assumptions about how iteration works. And, those assumptions give me a 500x performance improvement in my ColdFusion data-processing algorithm!
Want to use code from this post? Check out the license.

Reader Comments
I opened a ticket for this on the Lucee Jira board:
https://luceeserver.atlassian.net/browse/LDEV-3958
I don't think it's a bug; but, I assume there is room for improvement.
Nice work! 🔥 One of the most satisfying things in development is optimisation, whether it's code or SQL.
It's one of the things I like about Advent of Code: the first half of a task often seems simple, but then you end up having to re-think it when the problem scales up by orders of magnitude...
@Seb,
I keep meaning to do the Advent of Code, but I just never seem to prioritize the time 😞 This year! This year I'll do it!
It would be interesting to see how many of these type of functions worked using a Unit test and give them some load...I know Ben and Unit Testing...LOL
I feel like I see these type of slow downs with many functions like this...maybe if we had some sort of generic query that pulls back X amount of records and then created a Unit Test for the functions and added that to cfdocs.org at the bottom of each function page, maybe we could start to see the issues easier....maybe.
You want to start creating Unit Tests for all the functions, I know you love creating tests....LOL
@Dan,
What are these "tests" you speak of 🤣 But seriously, it's an interesting idea. I know that "premature optimization is the root of all evil"; and, at small scale, I'm sure it really doesn't matter what approach you use. But, sometimes, like in cases like this, performance really does matter. And a small micro-optimization can have a profound impact.
Ben, is there a reason you didn't just use the
.subList()method of JavaLists which is what powers a CFML array.https://docs.oracle.com/javase/7/docs/api/java/util/ArrayList.html#subList(int,%20int)
It's WAY faster on Adobe and Lucee, and honestly it's what they should both be using under the hood.
https://trycf.com/gist/bcb561351af6ad4daa610e0374ab9314/lucee5?theme=monokai
This code will run on both engines:
@Brad,
Oh snap! I didn't know that even existed. Plus, I get a little shy about using the underlying Java methods because whenever I do, inevitably someone shakes their finger at me for using an "undocumented" feature. But, yeah, kind of crazy that we're not using that already (under the hood) if it is faster.
@Brad,
By the way, every time I run that in Try CF, the
.subList()approach is 0ms ... every time 😮@Brad,
you just made my year, refactoring my DAL as we speak and this is infinately helpful.
@Dawesi,
Awwww yeaaahhhhhh! It takes team work to make the dream work! 🎉
Pothys rightly pointed out in the Lucee ticket tracker that an
ArrayList$SubListinstance is not a copy of the original items, but is just a wrapper that points to the original array. As such, any changes made to the original array or the sublist will be reflected in both places.If you're only slicing the array to pass around and not modifying the original array or its slices, then this will be no issue. However, if you want to modify the original array or sublists WITHOUT having those changes happen in both places, that means you can't just blindly swap
arr.slice()out forarr.subList().And on a related note, I found a little bug in Adobe CF while testing this:
https://tracker.adobe.com/#/view/CF-4213260
@Brad,
That's a great catch! Yeah, that could have / would have lead to some seriously hard-to-debug errors, no doubt. That said, you could probably do something like:
[].append( collection.subList( ... ), true )... to create a copy of the sub-list and isolate it. That said, I'm just assuming that you can pass the results of the Java-level
.subList()call into the CFML-level.append(values,all)call.@Brad,
Oh, ha ha, I just now see that your ACF bug is about treating
.subList()as an Array in ColdFusion :D And, that your demo is exactly what I was suggesting 😅 Great minds think alike, clearly.Lol, yep, that's exactly what you'd do. Now, the million dollar question is whether copying the items over to a new array undoes the performance gain of using a sublist in the first place!
@Brad,
I believe it would still be a net-win for performance since the problem with the current implementation of
arraySlice()is that it iterates over the array to find the slice. If we reduce the "pre slice space" using.subList(), then we would get rid of that iteration overhead. I think.@All,
I took a quick peek at using the
Array.sublist()method in ColdFusion. First, I just demonstrate what Brad already demonstrated - that mutations to the.sublist()slice also mutate the original array. But, then I look at the overall performance in the context of my large array processing and it looks like even with the overhead of having to create a native ColdFusion array from the.sublist()array, it's still 8-times faster than the fastest manual algorithm that I came up with:www.bennadel.com/blog/4257-safely-using-array-sublist-to-generate-slices-in-lucee-cfml.htm
So, at small scale, almost certainly a micro-optimization; but, at large scale, this is an awesome method to know about (as long as you use it safely).